 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJANUS: A Lightweight Framework for Jailbreaking Text-to-Image Models via Distribution Optimization
Mar 22, 2026Text-to-image (T2I) models such as Stable Diffusion and DALLE remain susceptible to generating harmful or Not-Safe-For-Work (NSFW) content under jailbreak attacks despite deployed safety filters. Existing jailbreak attacks either rely on proxy-loss optimization instead of the true end-to-end objective, or depend on large-scale and costly RL-trained generators. Motivated by these limitations, we propose JANUS , a lightweight framework that formulates jailbreak as optimizing a structured prompt distribution under a black-box, end-to-end reward from the T2I system and its safety filters. JANUS replaces a high-capacity generator with a low-dimensional mixing policy over two semantically anchored prompt distributions, enabling efficient exploration while preserving the target semantics. On modern T2I models, we outperform state-of-the-art jailbreak methods, improving ASR-8 from 25.30% to 43.15% on Stable Diffusion 3.5 Large Turbo with consistently higher CLIP and NSFW scores. JANUS succeeds across both open-source and commercial models. These findings expose structural weaknesses in current T2I safety pipelines and motivate stronger, distribution-aware defenses. Warning: This paper contains model outputs that may be offensive.
ADAPT: Adaptive Dual-projection Architecture for Perceptive Traversal
Mar 17, 2026Agile humanoid locomotion in complex 3D en- vironments requires balancing perceptual fidelity with com- putational efficiency, yet existing methods typically rely on rigid sensing configurations. We propose ADAPT (Adaptive dual-projection architecture for perceptive traversal), which represents the environment using a horizontal elevation map for terrain geometry and a vertical distance map for traversable- space constraints. ADAPT further treats its spatial sensing range as a learnable action, enabling the policy to expand its perceptual horizon during fast motion and contract it in cluttered scenes for finer local resolution. Compared with voxel-based baselines, ADAPT drastically reduces observation dimensionality and computational overhead while substantially accelerating training. Experimentally, it achieves successful zero-shot transfer to a Unitree G1 Humanoid and signifi- cantly outperforms fixed-range baselines, yielding highly robust traversal across diverse 3D environtmental challenges.
DiT-JSCC: Rethinking Deep JSCC with Diffusion Transformers and Semantic Representations
Jan 06, 2026Generative joint source-channel coding (GJSCC) has emerged as a new Deep JSCC paradigm for achieving high-fidelity and robust image transmission under extreme wireless channel conditions, such as ultra-low bandwidth and low signal-to-noise ratio. Recent studies commonly adopt diffusion models as generative decoders, but they frequently produce visually realistic results with limited semantic consistency. This limitation stems from a fundamental mismatch between reconstruction-oriented JSCC encoders and generative decoders, as the former lack explicit semantic discriminability and fail to provide reliable conditional cues. In this paper, we propose DiT-JSCC, a novel GJSCC backbone that can jointly learn a semantics-prioritized representation encoder and a diffusion transformer (DiT) based generative decoder, our open-source project aims to promote the future research in GJSCC. Specifically, we design a semantics-detail dual-branch encoder that aligns naturally with a coarse-to-fine conditional DiT decoder, prioritizing semantic consistency under extreme channel conditions. Moreover, a training-free adaptive bandwidth allocation strategy inspired by Kolmogorov complexity is introduced to further improve the transmission efficiency, thereby indeed redefining the notion of information value in the era of generative decoding. Extensive experiments demonstrate that DiT-JSCC consistently outperforms existing JSCC methods in both semantic consistency and visual quality, particularly in extreme regimes.
Retrofit: Continual Learning with Bounded Forgetting for Security Applications
Nov 14, 2025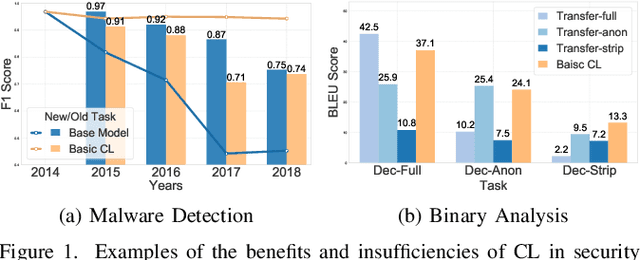
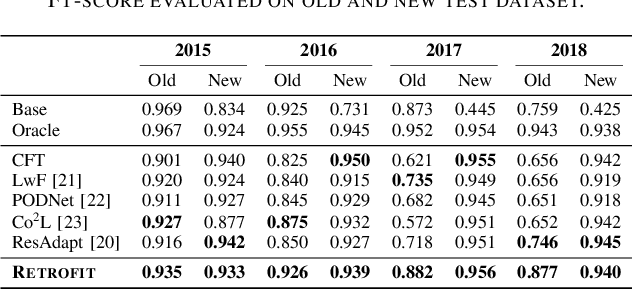

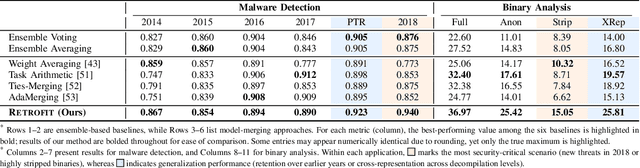
Modern security analytics are increasingly powered by deep learning models, but their performance often degrades as threat landscapes evolve and data representations shift. While continual learning (CL) offers a promising paradigm to maintain model effectiveness, many approaches rely on full retraining or data replay, which are infeasible in data-sensitive environments. Moreover, existing methods remain inadequate for security-critical scenarios, facing two coupled challenges in knowledge transfer: preserving prior knowledge without old data and integrating new knowledge with minimal interference. We propose RETROFIT, a data retrospective-free continual learning method that achieves bounded forgetting for effective knowledge transfer. Our key idea is to consolidate previously trained and newly fine-tuned models, serving as teachers of old and new knowledge, through parameter-level merging that eliminates the need for historical data. To mitigate interference, we apply low-rank and sparse updates that confine parameter changes to independent subspaces, while a knowledge arbitration dynamically balances the teacher contributions guided by model confidence. Our evaluation on two representative applications demonstrates that RETROFIT consistently mitigates forgetting while maintaining adaptability. In malware detection under temporal drift, it substantially improves the retention score, from 20.2% to 38.6% over CL baselines, and exceeds the oracle upper bound on new data. In binary summarization across decompilation levels, where analyzing stripped binaries is especially challenging, RETROFIT achieves around twice the BLEU score of transfer learning used in prior work and surpasses all baselines in cross-representation generalization.
Generative AI Meets 6G and Beyond: Diffusion Models for Semantic Communications
Nov 11, 2025Semantic communications mark a paradigm shift from bit-accurate transmission toward meaning-centric communication, essential as wireless systems approach theoretical capacity limits. The emergence of generative AI has catalyzed generative semantic communications, where receivers reconstruct content from minimal semantic cues by leveraging learned priors. Among generative approaches, diffusion models stand out for their superior generation quality, stable training dynamics, and rigorous theoretical foundations. However, the field currently lacks systematic guidance connecting diffusion techniques to communication system design, forcing researchers to navigate disparate literatures. This article provides the first comprehensive tutorial on diffusion models for generative semantic communications. We present score-based diffusion foundations and systematically review three technical pillars: conditional diffusion for controllable generation, efficient diffusion for accelerated inference, and generalized diffusion for cross-domain adaptation. In addition, we introduce an inverse problem perspective that reformulates semantic decoding as posterior inference, bridging semantic communications with computational imaging. Through analysis of human-centric, machine-centric, and agent-centric scenarios, we illustrate how diffusion models enable extreme compression while maintaining semantic fidelity and robustness. By bridging generative AI innovations with communication system design, this article aims to establish diffusion models as foundational components of next-generation wireless networks and beyond.
Black-Box Guardrail Reverse-engineering Attack
Nov 06, 2025Large language models (LLMs) increasingly employ guardrails to enforce ethical, legal, and application-specific constraints on their outputs. While effective at mitigating harmful responses, these guardrails introduce a new class of vulnerabilities by exposing observable decision patterns. In this work, we present the first study of black-box LLM guardrail reverse-engineering attacks. We propose Guardrail Reverse-engineering Attack (GRA), a reinforcement learning-based framework that leverages genetic algorithm-driven data augmentation to approximate the decision-making policy of victim guardrails. By iteratively collecting input-output pairs, prioritizing divergence cases, and applying targeted mutations and crossovers, our method incrementally converges toward a high-fidelity surrogate of the victim guardrail. We evaluate GRA on three widely deployed commercial systems, namely ChatGPT, DeepSeek, and Qwen3, and demonstrate that it achieves an rule matching rate exceeding 0.92 while requiring less than $85 in API costs. These findings underscore the practical feasibility of guardrail extraction and highlight significant security risks for current LLM safety mechanisms. Our findings expose critical vulnerabilities in current guardrail designs and highlight the urgent need for more robust defense mechanisms in LLM deployment.
SoK: Large Language Model Copyright Auditing via Fingerprinting
Aug 27, 2025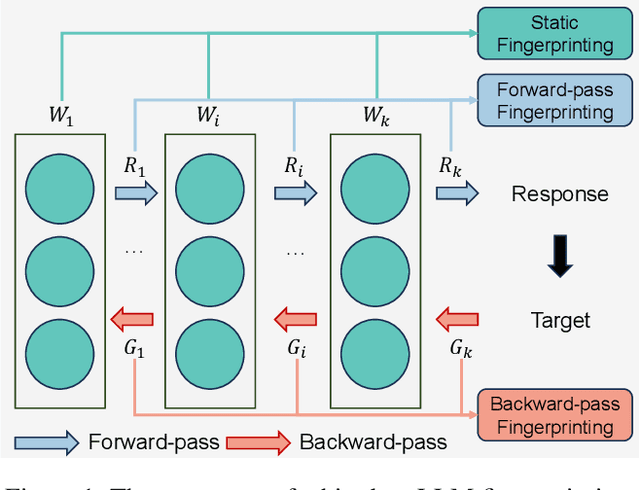

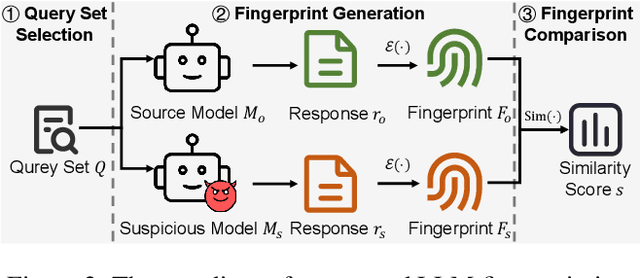

The broad capabilities and substantial resources required to train Large Language Models (LLMs) make them valuable intellectual property, yet they remain vulnerable to copyright infringement, such as unauthorized use and model theft. LLM fingerprinting, a non-intrusive technique that extracts and compares the distinctive features from LLMs to identify infringements, offers a promising solution to copyright auditing. However, its reliability remains uncertain due to the prevalence of diverse model modifications and the lack of standardized evaluation. In this SoK, we present the first comprehensive study of LLM fingerprinting. We introduce a unified framework and formal taxonomy that categorizes existing methods into white-box and black-box approaches, providing a structured overview of the state of the art. We further propose LeaFBench, the first systematic benchmark for evaluating LLM fingerprinting under realistic deployment scenarios. Built upon mainstream foundation models and comprising 149 distinct model instances, LeaFBench integrates 13 representative post-development techniques, spanning both parameter-altering methods (e.g., fine-tuning, quantization) and parameter-independent mechanisms (e.g., system prompts, RAG). Extensive experiments on LeaFBench reveal the strengths and weaknesses of existing methods, thereby outlining future research directions and critical open problems in this emerging field. The code is available at https://github.com/shaoshuo-ss/LeaFBench.
Quantifying Conversation Drift in MCP via Latent Polytope
Aug 08, 2025The Model Context Protocol (MCP) enhances large language models (LLMs) by integrating external tools, enabling dynamic aggregation of real-time data to improve task execution. However, its non-isolated execution context introduces critical security and privacy risks. In particular, adversarially crafted content can induce tool poisoning or indirect prompt injection, leading to conversation hijacking, misinformation propagation, or data exfiltration. Existing defenses, such as rule-based filters or LLM-driven detection, remain inadequate due to their reliance on static signatures, computational inefficiency, and inability to quantify conversational hijacking. To address these limitations, we propose SecMCP, a secure framework that detects and quantifies conversation drift, deviations in latent space trajectories induced by adversarial external knowledge. By modeling LLM activation vectors within a latent polytope space, SecMCP identifies anomalous shifts in conversational dynamics, enabling proactive detection of hijacking, misleading, and data exfiltration. We evaluate SecMCP on three state-of-the-art LLMs (Llama3, Vicuna, Mistral) across benchmark datasets (MS MARCO, HotpotQA, FinQA), demonstrating robust detection with AUROC scores exceeding 0.915 while maintaining system usability. Our contributions include a systematic categorization of MCP security threats, a novel latent polytope-based methodology for quantifying conversation drift, and empirical validation of SecMCP's efficacy.
Can Knowledge Improve Security? A Coding-Enhanced Jamming Approach for Semantic Communication
May 06, 2025As semantic communication (SemCom) attracts growing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels has become a critical issue. However, traditional encryption methods often introduce significant additional communication overhead to maintain stability, and conventional learning-based secure SemCom methods typically rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in real-world scenarios. In this paper, we propose a coding-enhanced jamming method that eliminates the need to transmit a secret key by utilizing shared knowledge-potentially part of the training set of the SemCom system-between the legitimate receiver and the transmitter. Specifically, we leverage the shared private knowledge base to generate a set of private digital codebooks in advance using neural network (NN)-based encoders. For each transmission, we encode the transmitted data into digital sequence Y1 and associate Y1 with a sequence randomly picked from the private codebook, denoted as Y2, through superposition coding. Here, Y1 serves as the outer code and Y2 as the inner code. By optimizing the power allocation between the inner and outer codes, the legitimate receiver can reconstruct the transmitted data using successive decoding with the index of Y2 shared, while the eavesdropper' s decoding performance is severely degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Enhancing the Security of Semantic Communication via Knowledge-Aided Coding and Jamming
May 01, 2025As semantic communication (SemCom) emerges as a promising communication paradigm, ensuring the security of semantic information over open wireless channels has become crucial. Traditional encryption methods introduce considerable communication overhead, while existing learning-based secure SemCom schemes often rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in practice. In this paper, we propose a coding-enhanced jamming approach that eliminates the need to transmit a secret key by utilizing shared knowledge between the legitimate receiver and the transmitter. We generate private codebooks with neural network (NN)-based encoders, using them to encode data into a sequence Y1, which is then superposed with a sequence Y2 drawn from the private codebook. By optimizing the power allocation between the two sequences, the legitimate receiver can successfully decode the data, while the eavesdropper' s performance is significantly degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.