 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomSeer: Reinforcing Multimodal LLMs to Reason for Time-Series Anomaly Detection
Feb 09, 2026Time-series anomaly detection (TSAD) with multimodal large language models (MLLMs) is an emerging area, yet a persistent challenge remains: MLLMs rely on coarse time-series heuristics but struggle with multi-dimensional, detailed reasoning, which is vital for understanding complex time-series data. We present AnomSeer to address this by reinforcing the model to ground its reasoning in precise, structural details of time series, unifying anomaly classification, localization, and explanation. At its core, an expert chain-of-thought trace is generated to provide a verifiable, fine-grained reasoning from classical analyses (e.g., statistical measures, frequency transforms). Building on this, we propose a novel time-series grounded policy optimization (TimerPO) that incorporates two additional components beyond standard reinforcement learning: a time-series grounded advantage based on optimal transport and an orthogonal projection to ensure this auxiliary granular signal does not interfere with the primary detection objective. Across diverse anomaly scenarios, AnomSeer, with Qwen2.5-VL-3B/7B-Instruct, outperforms larger commercial baselines (e.g., GPT-4o) in classification and localization accuracy, particularly on point- and frequency-driven exceptions. Moreover, it produces plausible time-series reasoning traces that support its conclusions.
Black-Box Guardrail Reverse-engineering Attack
Nov 06, 2025Large language models (LLMs) increasingly employ guardrails to enforce ethical, legal, and application-specific constraints on their outputs. While effective at mitigating harmful responses, these guardrails introduce a new class of vulnerabilities by exposing observable decision patterns. In this work, we present the first study of black-box LLM guardrail reverse-engineering attacks. We propose Guardrail Reverse-engineering Attack (GRA), a reinforcement learning-based framework that leverages genetic algorithm-driven data augmentation to approximate the decision-making policy of victim guardrails. By iteratively collecting input-output pairs, prioritizing divergence cases, and applying targeted mutations and crossovers, our method incrementally converges toward a high-fidelity surrogate of the victim guardrail. We evaluate GRA on three widely deployed commercial systems, namely ChatGPT, DeepSeek, and Qwen3, and demonstrate that it achieves an rule matching rate exceeding 0.92 while requiring less than $85 in API costs. These findings underscore the practical feasibility of guardrail extraction and highlight significant security risks for current LLM safety mechanisms. Our findings expose critical vulnerabilities in current guardrail designs and highlight the urgent need for more robust defense mechanisms in LLM deployment.
Quantifying Conversation Drift in MCP via Latent Polytope
Aug 08, 2025The Model Context Protocol (MCP) enhances large language models (LLMs) by integrating external tools, enabling dynamic aggregation of real-time data to improve task execution. However, its non-isolated execution context introduces critical security and privacy risks. In particular, adversarially crafted content can induce tool poisoning or indirect prompt injection, leading to conversation hijacking, misinformation propagation, or data exfiltration. Existing defenses, such as rule-based filters or LLM-driven detection, remain inadequate due to their reliance on static signatures, computational inefficiency, and inability to quantify conversational hijacking. To address these limitations, we propose SecMCP, a secure framework that detects and quantifies conversation drift, deviations in latent space trajectories induced by adversarial external knowledge. By modeling LLM activation vectors within a latent polytope space, SecMCP identifies anomalous shifts in conversational dynamics, enabling proactive detection of hijacking, misleading, and data exfiltration. We evaluate SecMCP on three state-of-the-art LLMs (Llama3, Vicuna, Mistral) across benchmark datasets (MS MARCO, HotpotQA, FinQA), demonstrating robust detection with AUROC scores exceeding 0.915 while maintaining system usability. Our contributions include a systematic categorization of MCP security threats, a novel latent polytope-based methodology for quantifying conversation drift, and empirical validation of SecMCP's efficacy.
ControlNET: A Firewall for RAG-based LLM System
Apr 13, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced the factual accuracy and domain adaptability of Large Language Models (LLMs). This advancement has enabled their widespread deployment across sensitive domains such as healthcare, finance, and enterprise applications. RAG mitigates hallucinations by integrating external knowledge, yet introduces privacy risk and security risk, notably data breaching risk and data poisoning risk. While recent studies have explored prompt injection and poisoning attacks, there remains a significant gap in comprehensive research on controlling inbound and outbound query flows to mitigate these threats. In this paper, we propose an AI firewall, ControlNET, designed to safeguard RAG-based LLM systems from these vulnerabilities. ControlNET controls query flows by leveraging activation shift phenomena to detect adversarial queries and mitigate their impact through semantic divergence. We conduct comprehensive experiments on four different benchmark datasets including Msmarco, HotpotQA, FinQA, and MedicalSys using state-of-the-art open source LLMs (Llama3, Vicuna, and Mistral). Our results demonstrate that ControlNET achieves over 0.909 AUROC in detecting and mitigating security threats while preserving system harmlessness. Overall, ControlNET offers an effective, robust, harmless defense mechanism, marking a significant advancement toward the secure deployment of RAG-based LLM systems.
Imitator Learning: Achieve Out-of-the-Box Imitation Ability in Variable Environments
Oct 09, 2023

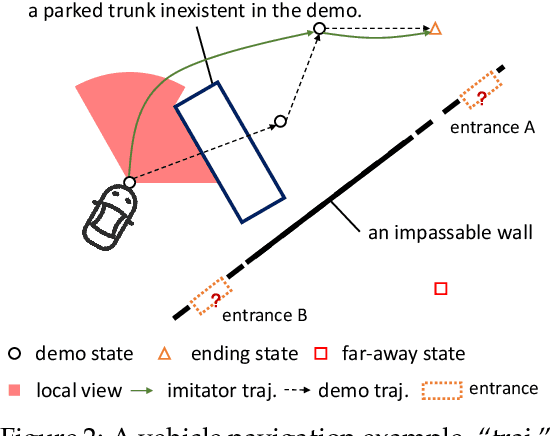

Imitation learning (IL) enables agents to mimic expert behaviors. Most previous IL techniques focus on precisely imitating one policy through mass demonstrations. However, in many applications, what humans require is the ability to perform various tasks directly through a few demonstrations of corresponding tasks, where the agent would meet many unexpected changes when deployed. In this scenario, the agent is expected to not only imitate the demonstration but also adapt to unforeseen environmental changes. This motivates us to propose a new topic called imitator learning (ItorL), which aims to derive an imitator module that can on-the-fly reconstruct the imitation policies based on very limited expert demonstrations for different unseen tasks, without any extra adjustment. In this work, we focus on imitator learning based on only one expert demonstration. To solve ItorL, we propose Demo-Attention Actor-Critic (DAAC), which integrates IL into a reinforcement-learning paradigm that can regularize policies' behaviors in unexpected situations. Besides, for autonomous imitation policy building, we design a demonstration-based attention architecture for imitator policy that can effectively output imitated actions by adaptively tracing the suitable states in demonstrations. We develop a new navigation benchmark and a robot environment for \topic~and show that DAAC~outperforms previous imitation methods \textit{with large margins} both on seen and unseen tasks.
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021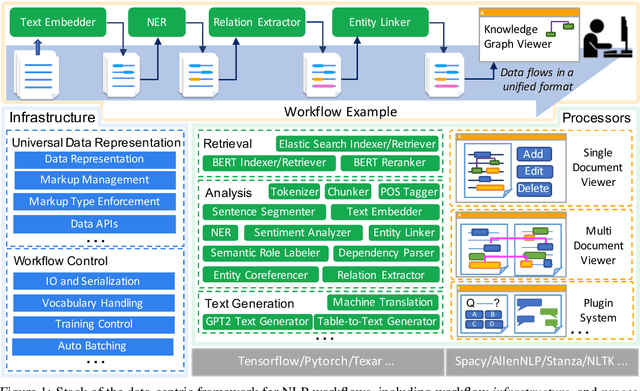
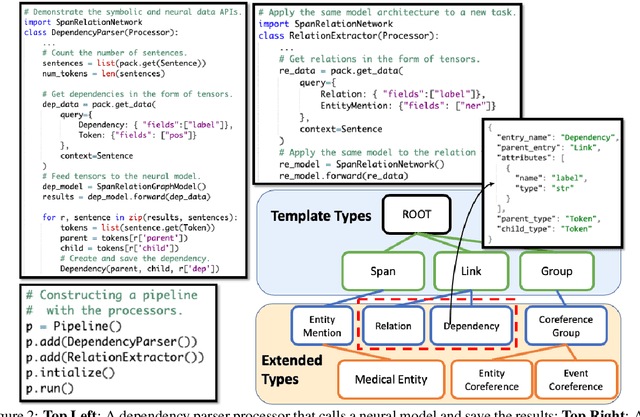
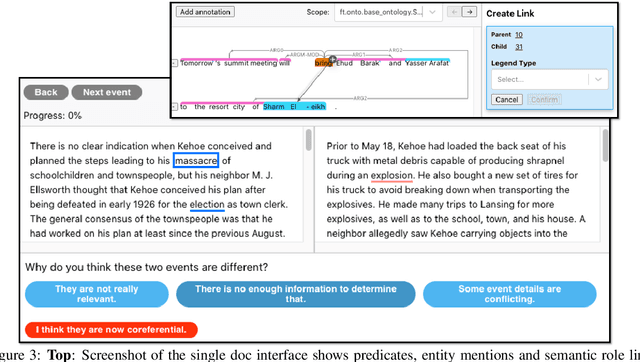

Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
Learning Hierarchical Representations of Electronic Health Records for Clinical Outcome Prediction
Mar 20, 2019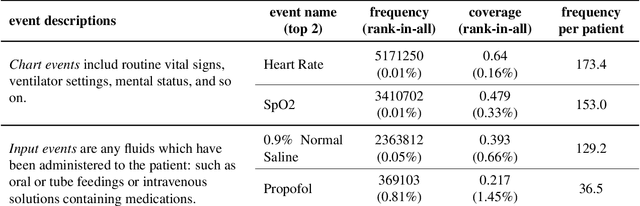
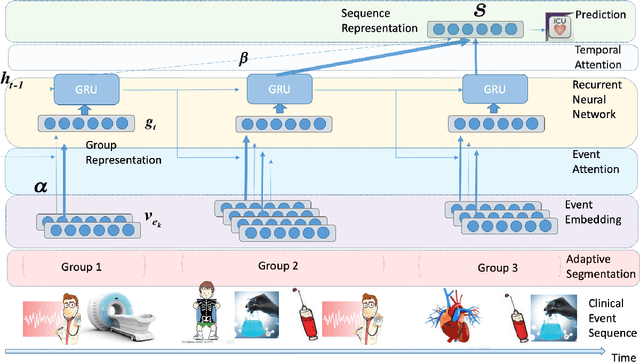

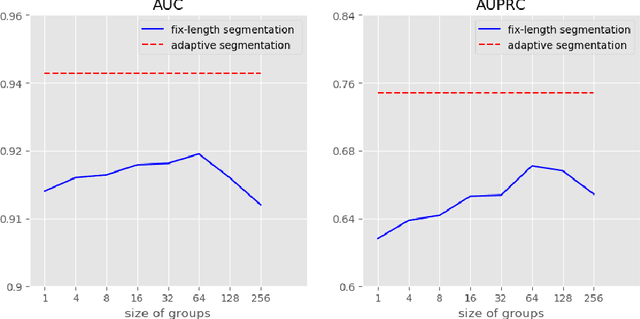
Clinical outcome prediction based on the Electronic Health Record (EHR) plays a crucial role in improving the quality of healthcare. Conventional deep sequential models fail to capture the rich temporal patterns encoded in the longand irregular clinical event sequences. We make the observation that clinical events at a long time scale exhibit strongtemporal patterns, while events within a short time period tend to be disordered co-occurrence. We thus propose differentiated mechanisms to model clinical events at different time scales. Our model learns hierarchical representationsof event sequences, to adaptively distinguish between short-range and long-range events, and accurately capture coretemporal dependencies. Experimental results on real clinical data show that our model greatly improves over previous state-of-the-art models, achieving AUC scores of 0.94 and 0.90 for predicting death and ICU admission respectively, Our model also successfully identifies important events for different clinical outcome prediction tasks
Toward Unsupervised Text Content Manipulation
Feb 08, 2019



Controlled generation of text is of high practical use. Recent efforts have made impressive progress in generating or editing sentences with given textual attributes (e.g., sentiment). This work studies a new practical setting of text content manipulation. Given a structured record, such as `(PLAYER: Lebron, POINTS: 20, ASSISTS: 10)', and a reference sentence, such as `Kobe easily dropped 30 points', we aim to generate a sentence that accurately describes the full content in the record, with the same writing style (e.g., wording, transitions) of the reference. The problem is unsupervised due to lack of parallel data in practice, and is challenging to minimally yet effectively manipulate the text (by rewriting/adding/deleting text portions) to ensure fidelity to the structured content. We derive a dataset from a basketball game report corpus as our testbed, and develop a neural method with unsupervised competing objectives and explicit content coverage constraints. Automatic and human evaluations show superiority of our approach over competitive methods including a strong rule-based baseline and prior approaches designed for style transfer.
Texar: A Modularized, Versatile, and Extensible Toolkit for Text Generation
Sep 04, 2018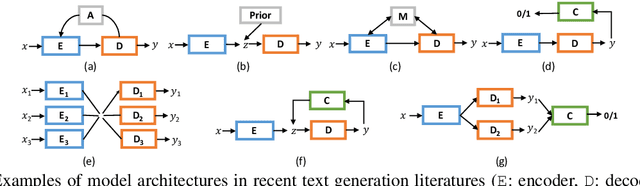
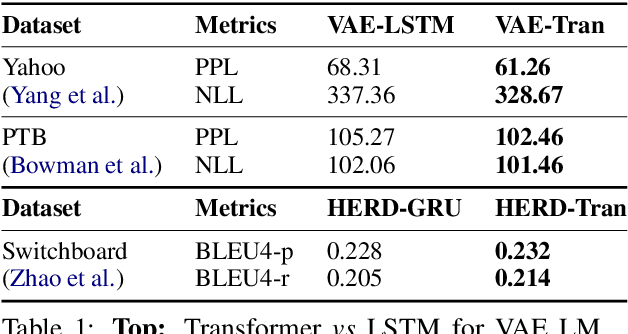
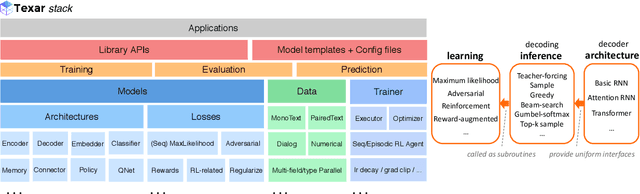

We introduce Texar, an open-source toolkit aiming to support the broad set of text generation tasks that transforms any inputs into natural language, such as machine translation, summarization, dialog, content manipulation, and so forth. With the design goals of modularity, versatility, and extensibility in mind, Texar extracts common patterns underlying the diverse tasks and methodologies, creates a library of highly reusable modules and functionalities, and allows arbitrary model architectures and algorithmic paradigms. In Texar, model architecture, losses, and learning processes are fully decomposed. Modules at high concept level can be freely assembled or plugged in/swapped out. These features make Texar particularly suitable for researchers and practitioners to do fast prototyping and experimentation, as well as foster technique sharing across different text generation tasks. We provide case studies to demonstrate the use and advantage of the toolkit. Texar is released under Apache license 2.0 at https://github.com/asyml/texar.
Towards Automated ICD Coding Using Deep Learning
Nov 30, 2017
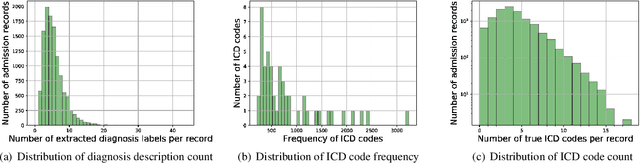

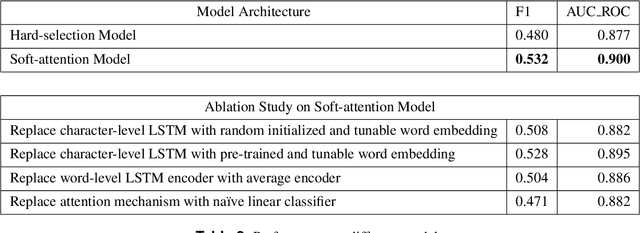
International Classification of Diseases(ICD) is an authoritative health care classification system of different diseases and conditions for clinical and management purposes. Considering the complicated and dedicated process to assign correct codes to each patient admission based on overall diagnosis, we propose a hierarchical deep learning model with attention mechanism which can automatically assign ICD diagnostic codes given written diagnosis. We utilize character-aware neural language models to generate hidden representations of written diagnosis descriptions and ICD codes, and design an attention mechanism to address the mismatch between the numbers of descriptions and corresponding codes. Our experimental results show the strong potential of automated ICD coding from diagnosis descriptions. Our best model achieves 0.53 and 0.90 of F1 score and area under curve of receiver operating characteristic respectively. The result outperforms those achieved using character-unaware encoding method or without attention mechanism. It indicates that our proposed deep learning model can code automatically in a reasonable way and provide a framework for computer-auxiliary ICD coding.