 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAJ: Data-Reweighted LLM Judge for Test-Time Scaling in Code Generation
Jan 29, 2026Test-time scaling for code generation commonly relies on Best-of-N selection, in which multiple candidate solutions are sampled from a base model, and the best one is selected by an LLM judge. However, training reliable LLM judges is challenging due to severe distribution shifts, including imbalances between easy and hard problems, mismatches between training tasks and evaluation benchmarks, and trajectory mismatch arising from training data generated by cheaper models whose behavior differs from that of inference-time models. We propose DAJ, a reasoning-based LLM judge trained with verifiable rewards under a bi-level data-reweighted learning framework. The proposed framework learns data-importance weights (either domain-level or instance-level) to optimize generalization performance on a held-out meta set aligned with target benchmarks. To the best of our knowledge, this is the first application of data reweighting to LLM-as-a-Judge training for test-time scaling. Our approach automatically emphasizes hard problems, in-distribution samples, and trajectory-aligned data, without relying on hand-crafted heuristics. Empirically, DAJ achieves state-of-the-art performance on LiveCodeBench and BigCodeBench, outperforming strong test-time scaling baselines as well as leading proprietary models.
FunPRM: Function-as-Step Process Reward Model with Meta Reward Correction for Code Generation
Jan 29, 2026Code generation is a core application of large language models (LLMs), yet LLMs still frequently fail on complex programming tasks. Given its success in mathematical reasoning, test-time scaling approaches such as Process Reward Model (PRM)-based Best-of-N selection offer a promising way to improve performance. However, existing PRMs remain ineffective for code generation due to the lack of meaningful step decomposition in code and the noise of Monte Carlo-estimated partial-solution correctness scores (rewards). To address these challenges, we propose FunPRM. FunPRM prompts LLMs to encourage modular code generation organized into functions, with functions treated as PRM reasoning steps. Furthermore, FunPRM introduces a novel meta-learning-based reward correction mechanism that leverages clean final-solution rewards obtained via a unit-test-based evaluation system to purify noisy partial-solution rewards. Experiments on LiveCodeBench and BigCodeBench demonstrate that FunPRM consistently outperforms existing test-time scaling methods across five base LLMs, notably achieving state-of-the-art performance on LiveCodeBench when combined with O4-mini. Furthermore, FunPRM produces code that is more readable and reusable for developers.
BLO-Inst: Bi-Level Optimization Based Alignment of YOLO and SAM for Robust Instance Segmentation
Jan 29, 2026The Segment Anything Model has revolutionized image segmentation with its zero-shot capabilities, yet its reliance on manual prompts hinders fully automated deployment. While integrating object detectors as prompt generators offers a pathway to automation, existing pipelines suffer from two fundamental limitations: objective mismatch, where detectors optimized for geometric localization do not correspond to the optimal prompting context required by SAM, and alignment overfitting in standard joint training, where the detector simply memorizes specific prompt adjustments for training samples rather than learning a generalizable policy. To bridge this gap, we introduce BLO-Inst, a unified framework that aligns detection and segmentation objectives by bi-level optimization. We formulate the alignment as a nested optimization problem over disjoint data splits. In the lower level, the SAM is fine-tuned to maximize segmentation fidelity given the current detection proposals on a subset ($D_1$). In the upper level, the detector is updated to generate bounding boxes that explicitly minimize the validation loss of the fine-tuned SAM on a separate subset ($D_2$). This effectively transforms the detector into a segmentation-aware prompt generator, optimizing the bounding boxes not just for localization accuracy, but for downstream mask quality. Extensive experiments demonstrate that BLO-Inst achieves superior performance, outperforming standard baselines on tasks in general and biomedical domains.
Models Under SCOPE: Scalable and Controllable Routing via Pre-hoc Reasoning
Jan 29, 2026Model routing chooses which language model to use for each query. By sending easy queries to cheaper models and hard queries to stronger ones, it can significantly reduce inference cost while maintaining high accuracy. However, most existing routers treat this as a fixed choice among a small set of models, which makes them hard to adapt to new models or changing budget constraints. In this paper, we propose SCOPE (Scalable and Controllable Outcome Performance Estimator), a routing framework that goes beyond model selection by predicting their cost and performance. Trained with reinforcement learning, SCOPE makes reasoning-based predictions by retrieving how models behave on similar problems, rather than relying on fixed model names, enabling it to work with new, unseen models. Moreover, by explicitly predicting how accurate and how expensive a model will be, it turns routing into a dynamic decision problem, allowing users to easily control the trade-off between accuracy and cost. Experiments show that SCOPE is more than just a cost-saving tool. It flexibly adapts to user needs: it can boost accuracy by up to 25.7% when performance is the priority, or cut costs by up to 95.1% when efficiency matters most.
FlashVLM: Text-Guided Visual Token Selection for Large Multimodal Models
Dec 23, 2025



Large vision-language models (VLMs) typically process hundreds or thousands of visual tokens per image or video frame, incurring quadratic attention cost and substantial redundancy. Existing token reduction methods often ignore the textual query or rely on deep attention maps, whose instability under aggressive pruning leads to degraded semantic alignment. We propose FlashVLM, a text guided visual token selection framework that dynamically adapts visual inputs to the query. Instead of relying on noisy attention weights, FlashVLM computes an explicit cross modal similarity between projected image tokens and normalized text embeddings in the language model space. This extrinsic relevance is fused with intrinsic visual saliency using log domain weighting and temperature controlled sharpening. In addition, a diversity preserving partition retains a minimal yet representative set of background tokens to maintain global context. Under identical token budgets and evaluation protocols, FlashVLM achieves beyond lossless compression, slightly surpassing the unpruned baseline while pruning up to 77.8 percent of visual tokens on LLaVA 1.5, and maintaining 92.8 percent accuracy even under 94.4 percent compression. Extensive experiments on 14 image and video benchmarks demonstrate that FlashVLM delivers state of the art efficiency performance trade offs while maintaining strong robustness and generalization across mainstream VLMs.
DreamPRM-Code: Function-as-Step Process Reward Model with Label Correction for LLM Coding
Dec 17, 2025


Process Reward Models (PRMs) have become essential for improving Large Language Models (LLMs) via test-time scaling, yet their effectiveness in coding remains limited due to the lack of meaningful step decompositions in code and the noise of Monte-Carlo-generated partial labels. We propose DreamPRM-Code, a coding-focused PRM that treats functions as reasoning steps using a Chain-of-Function prompting strategy to induce modular code generation, enabling PRM training and application analogous to mathematical reasoning tasks. To address label noise, DreamPRM-Code introduces a meta-learning-based correction mechanism that leverages clean final-solution unit-test labels and performs bi-level optimization to refine intermediate labels. Applying on test-time scaling, DreamPRM-Code achieved state-of-the-art performance on LiveCodeBench with 80.9 pass@1 rate, surpassing OpenAI o4-mini.
Steganographic Backdoor Attacks in NLP: Ultra-Low Poisoning and Defense Evasion
Nov 18, 2025Transformer models are foundational to natural language processing (NLP) applications, yet remain vulnerable to backdoor attacks introduced through poisoned data, which implant hidden behaviors during training. To strengthen the ability to prevent such compromises, recent research has focused on designing increasingly stealthy attacks to stress-test existing defenses, pairing backdoor behaviors with stylized artifact or token-level perturbation triggers. However, this trend diverts attention from the harder and more realistic case: making the model respond to semantic triggers such as specific names or entities, where a successful backdoor could manipulate outputs tied to real people or events in deployed systems. Motivated by this growing disconnect, we introduce SteganoBackdoor, bringing stealth techniques back into line with practical threat models. Leveraging innocuous properties from natural-language steganography, SteganoBackdoor applies a gradient-guided data optimization process to transform semantic trigger seeds into steganographic carriers that embed a high backdoor payload, remain fluent, and exhibit no representational resemblance to the trigger. Across diverse experimental settings, SteganoBackdoor achieves over 99% attack success at an order-of-magnitude lower data-poisoning rate than prior approaches while maintaining unparalleled evasion against a comprehensive suite of data-level defenses. By revealing this practical and covert attack, SteganoBackdoor highlights an urgent blind spot in current defenses and demands immediate attention to adversarial data defenses and real-world threat modeling.
S-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025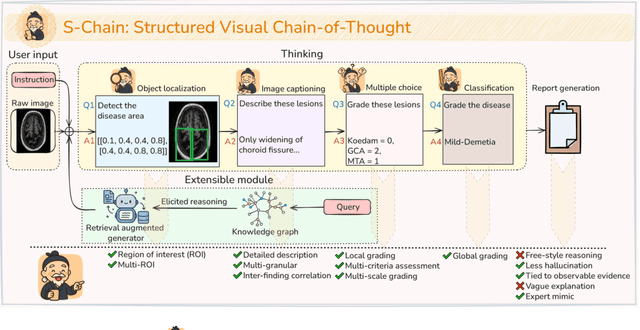
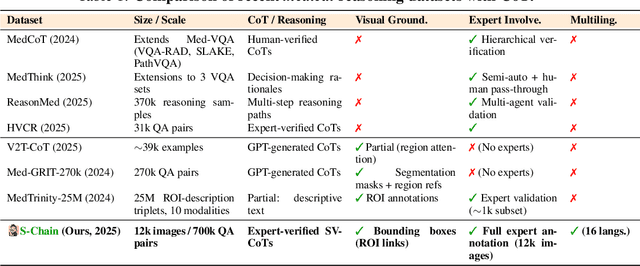
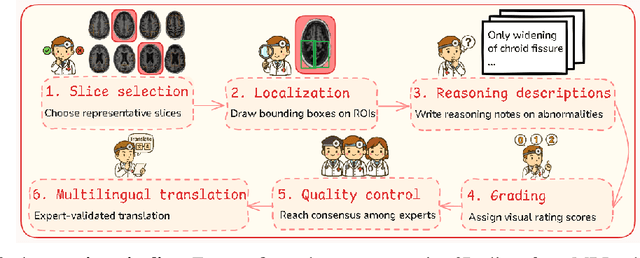
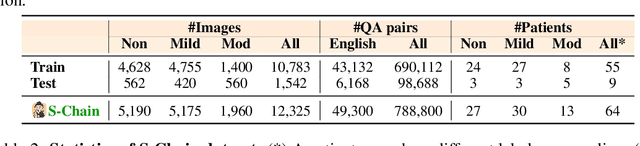
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
DreamPRM: Domain-Reweighted Process Reward Model for Multimodal Reasoning
May 26, 2025Reasoning has substantially improved the performance of large language models (LLMs) on complicated tasks. Central to the current reasoning studies, Process Reward Models (PRMs) offer a fine-grained evaluation of intermediate reasoning steps and guide the reasoning process. However, extending PRMs to multimodal large language models (MLLMs) introduces challenges. Since multimodal reasoning covers a wider range of tasks compared to text-only scenarios, the resulting distribution shift from the training to testing sets is more severe, leading to greater generalization difficulty. Training a reliable multimodal PRM, therefore, demands large and diverse datasets to ensure sufficient coverage. However, current multimodal reasoning datasets suffer from a marked quality imbalance, which degrades PRM performance and highlights the need for an effective data selection strategy. To address the issues, we introduce DreamPRM, a domain-reweighted training framework for multimodal PRMs which employs bi-level optimization. In the lower-level optimization, DreamPRM performs fine-tuning on multiple datasets with domain weights, allowing the PRM to prioritize high-quality reasoning signals and alleviating the impact of dataset quality imbalance. In the upper-level optimization, the PRM is evaluated on a separate meta-learning dataset; this feedback updates the domain weights through an aggregation loss function, thereby improving the generalization capability of trained PRM. Extensive experiments on multiple multimodal reasoning benchmarks covering both mathematical and general reasoning show that test-time scaling with DreamPRM consistently improves the performance of state-of-the-art MLLMs. Further comparisons reveal that DreamPRM's domain-reweighting strategy surpasses other data selection methods and yields higher accuracy gains than existing test-time scaling approaches.
Defense against Prompt Injection Attacks via Mixture of Encodings
Apr 10, 2025Large Language Models (LLMs) have emerged as a dominant approach for a wide range of NLP tasks, with their access to external information further enhancing their capabilities. However, this introduces new vulnerabilities, known as prompt injection attacks, where external content embeds malicious instructions that manipulate the LLM's output. Recently, the Base64 defense has been recognized as one of the most effective methods for reducing success rate of prompt injection attacks. Despite its efficacy, this method can degrade LLM performance on certain NLP tasks. To address this challenge, we propose a novel defense mechanism: mixture of encodings, which utilizes multiple character encodings, including Base64. Extensive experimental results show that our method achieves one of the lowest attack success rates under prompt injection attacks, while maintaining high performance across all NLP tasks, outperforming existing character encoding-based defense methods. This underscores the effectiveness of our mixture of encodings strategy for both safety and task performance metrics.