 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Transformers with Spectrum-Preserving Token Merging
Paper and Code

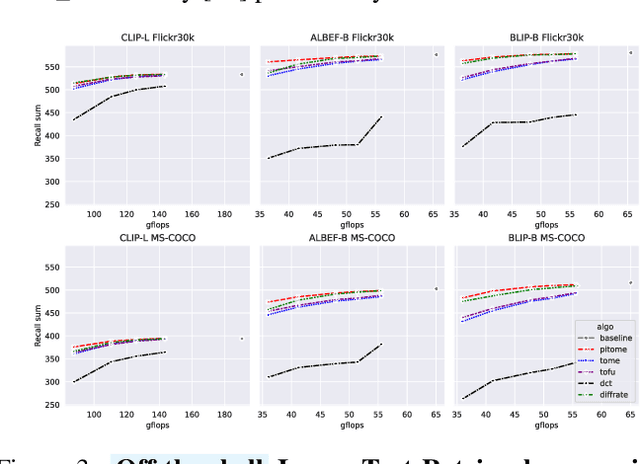
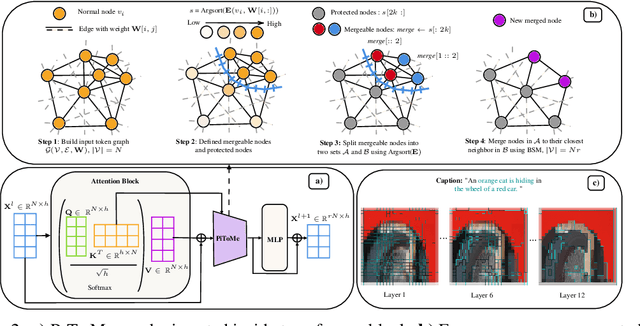
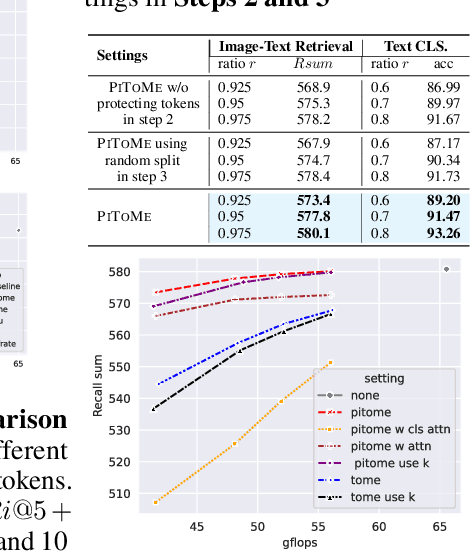
Increasing the throughput of the Transformer architecture, a foundational component used in numerous state-of-the-art models for vision and language tasks (e.g., GPT, LLaVa), is an important problem in machine learning. One recent and effective strategy is to merge token representations within Transformer models, aiming to reduce computational and memory requirements while maintaining accuracy. Prior works have proposed algorithms based on Bipartite Soft Matching (BSM), which divides tokens into distinct sets and merges the top k similar tokens. However, these methods have significant drawbacks, such as sensitivity to token-splitting strategies and damage to informative tokens in later layers. This paper presents a novel paradigm called PiToMe, which prioritizes the preservation of informative tokens using an additional metric termed the energy score. This score identifies large clusters of similar tokens as high-energy, indicating potential candidates for merging, while smaller (unique and isolated) clusters are considered as low-energy and preserved. Experimental findings demonstrate that PiToMe saved from 40-60\% FLOPs of the base models while exhibiting superior off-the-shelf performance on image classification (0.5\% average performance drop of ViT-MAE-H compared to 2.6\% as baselines), image-text retrieval (0.3\% average performance drop of CLIP on Flickr30k compared to 4.5\% as others), and analogously in visual questions answering with LLaVa-7B. Furthermore, PiToMe is theoretically shown to preserve intrinsic spectral properties of the original token space under mild conditions