 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Vision-Language-Action Models Requires Fewer Layers Than You Think
Jun 18, 2026Vision-Language-Action (VLA) models pre-trained on massive video-robot datasets have revolutionized robotic manipulation, yet their multi-billion parameter architectures impose prohibitive computational burdens during downstream fine-tuning and real-time inference. In this work, we reveal a highly non-trivial architectural characteristic of these continuous control foundation policies (e.g., pi_0, GR00T-N1.5): despite being trained on diverse physical trajectories, they exhibit severe layer-wise representational redundancy. To exploit this, we introduce a structural compression pipeline that is entirely training-free, bypassing the need of existing methods to load full-scale models to learn optimized token reductions or dynamic layer selectors. Instead, using only a single forward pass via Centered Kernel Alignment to identify redundant layer features, we remove twin layers to permanently compress the model depth by up to 50% across both the VLM backbone and the continuous control policy head. Downstream fine-tuning of this streamlined architecture yields a dual acceleration benefit: a 40-50% reduction in training time and up to 30% faster real-time inference, while matching or exceeding full-scale base model performance. We comprehensively validate our method across three simulation benchmarks (LIBERO, RoboCasa, SimplerEnv) and 10 diverse real-world manipulation tasks across 4 unique robotic embodiments. These results prove that advanced VLAs require significantly fewer layers than previously assumed, offering a highly compute-efficient paradigm for scalable robot learning.
FOCA: Future-Oriented Conditioning for Data-Efficient Vision-Language-Action Adaptation
Jun 18, 2026Vision-Language-Action (VLA) models enable general-purpose robotic control via large-scale multimodal pretraining, yet their effectiveness under few-shot imitation learning remains limited. We conduct a systematic stress test of state-of-the-art VLA models and show that performance degrades sharply as demonstrations are reduced, revealing a key weakness of existing adaptation strategies. To address this, we introduce FOCA, a future-oriented conditioning framework for data-efficient VLA adaptation. FOCA combines explicit prediction of task-grounded future interaction embeddings with implicit alignment to future goal observations, enabling long-horizon reasoning in latent space without pixel-level prediction. This formulation naturally supports action-free co-training with synthetic videos from video world models and can be interpreted as learning a future-conditioned value-like representation. Extensive experiments demonstrate FOCA achieves 95.7% success with 20 demonstrations on LIBERO, improves 7-12% on RoboCasa, and delivers up to 26% absolute gains on real robots, establishing a new state of the art in few-shot VLA adaptation.
Self-Improving VLA Policies: Selected Diffusion Noise for Spurious-Robust Action Smoothing
Jun 12, 2026Diffusion-based Vision-Language-Action (VLA) policies enable strong generalization in robotic manipulation, but remain sensitive to spurious visual correlations and noisy action generation, leading to brittle behavior under perturbations. We introduce Selected Diffusion Noise (SDN), a simple, training-free test-time method that improves both robustness and success rate by leveraging the diffusion noise space as a controllable degree of freedom. SDN dynamically samples noise vectors that are maximally separated from a reference set to mitigate reliance on spurious cues, while selecting candidates that yield more coherent action trajectories. This dual objective encourages stable behavior even under object-masked observations and reduces action jitter without modifying model parameters. We evaluate SDN on two simulation benchmarks (Google Robot, Widow-X) and two real-world robotic datasets across multiple VLA policies, including pi_0, Groot-N1.5, and Groot-N1.6. SDN consistently improves success rates by +8% in simulation and +10% in real-world settings, while producing smoother and more stable actions. Our results highlight that diffusion noise selection can serve as an effective and general mechanism for enhancing VLA policies at test time.
The Speed-up Factor: A Quantitative Multi-Iteration Active Learning Performance Metric
Feb 13, 2026Machine learning models excel with abundant annotated data, but annotation is often costly and time-intensive. Active learning (AL) aims to improve the performance-to-annotation ratio by using query methods (QMs) to iteratively select the most informative samples. While AL research focuses mainly on QM development, the evaluation of this iterative process lacks appropriate performance metrics. This work reviews eight years of AL evaluation literature and formally introduces the speed-up factor, a quantitative multi-iteration QM performance metric that indicates the fraction of samples needed to match random sampling performance. Using four datasets from diverse domains and seven QMs of various types, we empirically evaluate the speed-up factor and compare it with state-of-the-art AL performance metrics. The results confirm the assumptions underlying the speed-up factor, demonstrate its accuracy in capturing the described fraction, and reveal its superior stability across iterations.
How Many Tokens Do 3D Point Cloud Transformer Architectures Really Need?
Nov 07, 2025Recent advances in 3D point cloud transformers have led to state-of-the-art results in tasks such as semantic segmentation and reconstruction. However, these models typically rely on dense token representations, incurring high computational and memory costs during training and inference. In this work, we present the finding that tokens are remarkably redundant, leading to substantial inefficiency. We introduce gitmerge3D, a globally informed graph token merging method that can reduce the token count by up to 90-95% while maintaining competitive performance. This finding challenges the prevailing assumption that more tokens inherently yield better performance and highlights that many current models are over-tokenized and under-optimized for scalability. We validate our method across multiple 3D vision tasks and show consistent improvements in computational efficiency. This work is the first to assess redundancy in large-scale 3D transformer models, providing insights into the development of more efficient 3D foundation architectures. Our code and checkpoints are publicly available at https://gitmerge3d.github.io
S-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025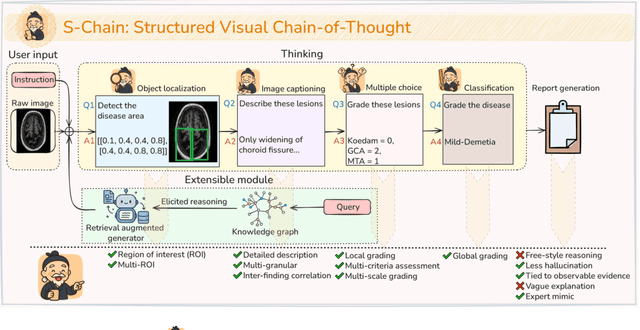
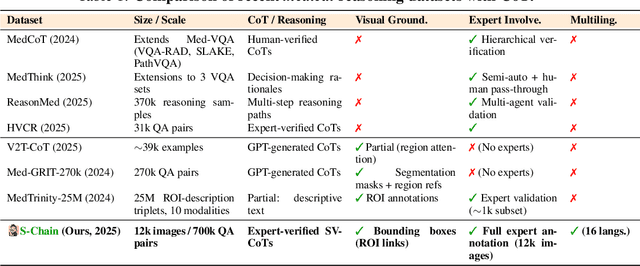
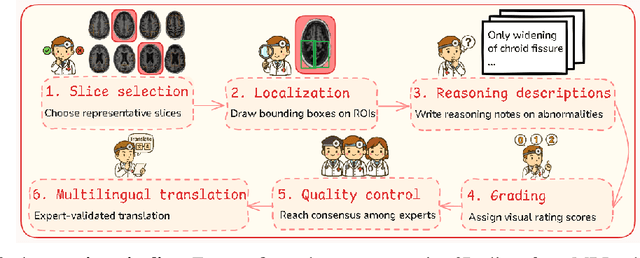
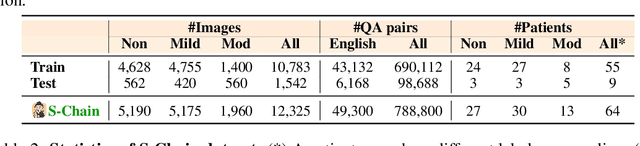
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
Mitigating Reward Over-optimization in Direct Alignment Algorithms with Importance Sampling
Jun 11, 2025Direct Alignment Algorithms (DAAs) such as Direct Preference Optimization (DPO) have emerged as alternatives to the standard Reinforcement Learning from Human Feedback (RLHF) for aligning large language models (LLMs) with human values. However, these methods are more susceptible to over-optimization, in which the model drifts away from the reference policy, leading to degraded performance as training progresses. This paper proposes a novel importance-sampling approach to mitigate the over-optimization problem of offline DAAs. This approach, called (IS-DAAs), multiplies the DAA objective with an importance ratio that accounts for the reference policy distribution. IS-DAAs additionally avoid the high variance issue associated with importance sampling by clipping the importance ratio to a maximum value. Our extensive experiments demonstrate that IS-DAAs can effectively mitigate over-optimization, especially under low regularization strength, and achieve better performance than other methods designed to address this problem. Our implementations are provided publicly at this link.
CBM-RAG: Demonstrating Enhanced Interpretability in Radiology Report Generation with Multi-Agent RAG and Concept Bottleneck Models
Apr 29, 2025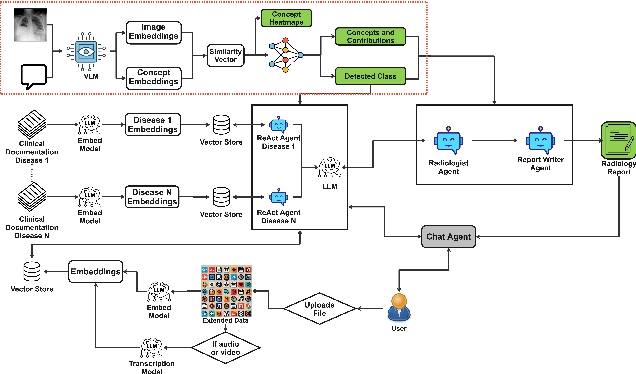
Advancements in generative Artificial Intelligence (AI) hold great promise for automating radiology workflows, yet challenges in interpretability and reliability hinder clinical adoption. This paper presents an automated radiology report generation framework that combines Concept Bottleneck Models (CBMs) with a Multi-Agent Retrieval-Augmented Generation (RAG) system to bridge AI performance with clinical explainability. CBMs map chest X-ray features to human-understandable clinical concepts, enabling transparent disease classification. Meanwhile, the RAG system integrates multi-agent collaboration and external knowledge to produce contextually rich, evidence-based reports. Our demonstration showcases the system's ability to deliver interpretable predictions, mitigate hallucinations, and generate high-quality, tailored reports with an interactive interface addressing accuracy, trust, and usability challenges. This framework provides a pathway to improving diagnostic consistency and empowering radiologists with actionable insights.
InFL-UX: A Toolkit for Web-Based Interactive Federated Learning
Mar 06, 2025

This paper presents InFL-UX, an interactive, proof-of-concept browser-based Federated Learning (FL) toolkit designed to integrate user contributions seamlessly into the machine learning (ML) workflow. InFL-UX enables users across multiple devices to upload datasets, define classes, and collaboratively train classification models directly in the browser using modern web technologies. Unlike traditional FL toolkits, which often focus on backend simulations, InFL-UX provides a simple user interface for researchers to explore how users interact with and contribute to FL systems in real-world, interactive settings. By prioritising usability and decentralised model training, InFL-UX bridges the gap between FL and Interactive Machine Learning (IML), empowering non-technical users to actively participate in ML classification tasks.
MGPATH: Vision-Language Model with Multi-Granular Prompt Learning for Few-Shot WSI Classification
Feb 11, 2025



Whole slide pathology image classification presents challenges due to gigapixel image sizes and limited annotation labels, hindering model generalization. This paper introduces a prompt learning method to adapt large vision-language models for few-shot pathology classification. We first extend the Prov-GigaPath vision foundation model, pre-trained on 1.3 billion pathology image tiles, into a vision-language model by adding adaptors and aligning it with medical text encoders via contrastive learning on 923K image-text pairs. The model is then used to extract visual features and text embeddings from few-shot annotations and fine-tunes with learnable prompt embeddings. Unlike prior methods that combine prompts with frozen features using prefix embeddings or self-attention, we propose multi-granular attention that compares interactions between learnable prompts with individual image patches and groups of them. This approach improves the model's ability to capture both fine-grained details and broader context, enhancing its recognition of complex patterns across sub-regions. To further improve accuracy, we leverage (unbalanced) optimal transport-based visual-text distance to secure model robustness by mitigating perturbations that might occur during the data augmentation process. Empirical experiments on lung, kidney, and breast pathology modalities validate the effectiveness of our approach; thereby, we surpass several of the latest competitors and consistently improve performance across diverse architectures, including CLIP, PLIP, and Prov-GigaPath integrated PLIP. We release our implementations and pre-trained models at this MGPATH.