 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Interpretable Multi-Parameter Control Policies for Evolutionary Algorithms Using Deep Reinforcement Learning
Jun 08, 2026While deep Reinforcement Learning (deep-RL) has been increasingly applied to parameter control in evolutionary algorithms, rigorous theoretical analysis of parameter control remains largely restricted to single-parameter settings, owing to the difficulty of deriving effective, interpretable multi-parameter policies amenable to formal study. We demonstrate how deep-RL can be leveraged to overcome this barrier, using the (1+($λ$,$λ$))-genetic algorithm optimizing OneMax, one of the few problems where a super-constant speedup of dynamic control has been formally proven, as a representative case study. We first show that standard approaches struggle to converge in this multi-parameter setting, and introduce algorithm-agnostic enhancements targeting action-space decomposition, reward shifting, and long-horizon discounting. With these in place, we compare common deep-RL methods and find that Double Deep Q-Networks uniquely avoid the policy collapse observed in Proximal Policy Optimization, yielding trajectories suitable for downstream analysis. Crucially, we move beyond the ``black-box'' nature of neural networks by distilling the learned behaviors into a transparent, symbolic control policy. This resulting policy does not only offer interpretability for future theoretical analysis but also yields exceptional performance, consistently outperforming existing baselines across a wide range of problem sizes.
Multi-parameter Control for the (1+($λ$,$λ$))-GA on OneMax via Deep Reinforcement Learning
May 19, 2025It is well known that evolutionary algorithms can benefit from dynamic choices of the key parameters that control their behavior, to adjust their search strategy to the different stages of the optimization process. A prominent example where dynamic parameter choices have shown a provable super-constant speed-up is the $(1+(\lambda,\lambda))$ Genetic Algorithm optimizing the OneMax function. While optimal parameter control policies result in linear expected running times, this is not possible with static parameter choices. This result has spurred a lot of interest in parameter control policies. However, many works, in particular theoretical running time analyses, focus on controlling one single parameter. Deriving policies for controlling multiple parameters remains very challenging. In this work we reconsider the problem of the $(1+(\lambda,\lambda))$ Genetic Algorithm optimizing OneMax. We decouple its four main parameters and investigate how well state-of-the-art deep reinforcement learning techniques can approximate good control policies. We show that although making deep reinforcement learning learn effectively is a challenging task, once it works, it is very powerful and is able to find policies that outperform all previously known control policies on the same benchmark. Based on the results found through reinforcement learning, we derive a simple control policy that consistently outperforms the default theory-recommended setting by $27\%$ and the irace-tuned policy, the strongest existing control policy on this benchmark, by $13\%$, for all tested problem sizes up to $40{,}000$.
On the Importance of Reward Design in Reinforcement Learning-based Dynamic Algorithm Configuration: A Case Study on OneMax with (1+($λ$,$λ$))-GA
Feb 27, 2025Dynamic Algorithm Configuration (DAC) has garnered significant attention in recent years, particularly in the prevalence of machine learning and deep learning algorithms. Numerous studies have leveraged the robustness of decision-making in Reinforcement Learning (RL) to address the optimization challenges associated with algorithm configuration. However, making an RL agent work properly is a non-trivial task, especially in reward design, which necessitates a substantial amount of handcrafted knowledge based on domain expertise. In this work, we study the importance of reward design in the context of DAC via a case study on controlling the population size of the $(1+(\lambda,\lambda))$-GA optimizing OneMax. We observed that a poorly designed reward can hinder the RL agent's ability to learn an optimal policy because of a lack of exploration, leading to both scalability and learning divergence issues. To address those challenges, we propose the application of a reward shaping mechanism to facilitate enhanced exploration of the environment by the RL agent. Our work not only demonstrates the ability of RL in dynamically configuring the $(1+(\lambda,\lambda))$-GA, but also confirms the advantages of reward shaping in the scalability of RL agents across various sizes of OneMax problems.
Deep Learning for Ophthalmology: The State-of-the-Art and Future Trends
Jan 07, 2025



The emergence of artificial intelligence (AI), particularly deep learning (DL), has marked a new era in the realm of ophthalmology, offering transformative potential for the diagnosis and treatment of posterior segment eye diseases. This review explores the cutting-edge applications of DL across a range of ocular conditions, including diabetic retinopathy, glaucoma, age-related macular degeneration, and retinal vessel segmentation. We provide a comprehensive overview of foundational ML techniques and advanced DL architectures, such as CNNs, attention mechanisms, and transformer-based models, highlighting the evolving role of AI in enhancing diagnostic accuracy, optimizing treatment strategies, and improving overall patient care. Additionally, we present key challenges in integrating AI solutions into clinical practice, including ensuring data diversity, improving algorithm transparency, and effectively leveraging multimodal data. This review emphasizes AI's potential to improve disease diagnosis and enhance patient care while stressing the importance of collaborative efforts to overcome these barriers and fully harness AI's impact in advancing eye care.
LoGra-Med: Long Context Multi-Graph Alignment for Medical Vision-Language Model
Oct 03, 2024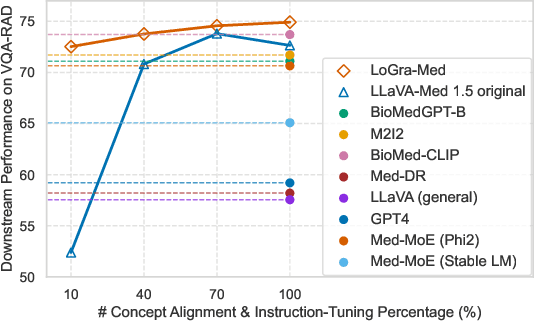
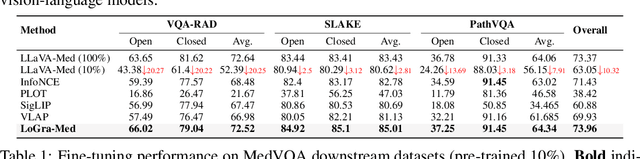
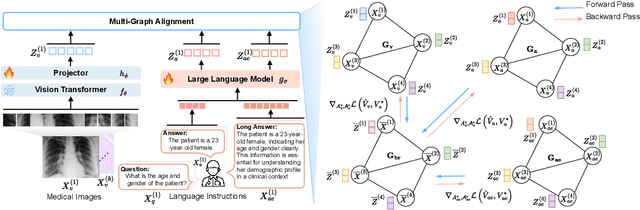
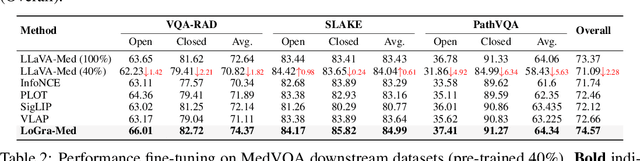
State-of-the-art medical multi-modal large language models (med-MLLM), like LLaVA-Med or BioMedGPT, leverage instruction-following data in pre-training. However, those models primarily focus on scaling the model size and data volume to boost performance while mainly relying on the autoregressive learning objectives. Surprisingly, we reveal that such learning schemes might result in a weak alignment between vision and language modalities, making these models highly reliant on extensive pre-training datasets - a significant challenge in medical domains due to the expensive and time-consuming nature of curating high-quality instruction-following instances. We address this with LoGra-Med, a new multi-graph alignment algorithm that enforces triplet correlations across image modalities, conversation-based descriptions, and extended captions. This helps the model capture contextual meaning, handle linguistic variability, and build cross-modal associations between visuals and text. To scale our approach, we designed an efficient end-to-end learning scheme using black-box gradient estimation, enabling faster LLaMa 7B training. Our results show LoGra-Med matches LLAVA-Med performance on 600K image-text pairs for Medical VQA and significantly outperforms it when trained on 10% of the data. For example, on VQA-RAD, we exceed LLAVA-Med by 20.13% and nearly match the 100% pre-training score (72.52% vs. 72.64%). We also surpass SOTA methods like BiomedGPT on visual chatbots and RadFM on zero-shot image classification with VQA, highlighting the effectiveness of multi-graph alignment.
Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model
Jul 05, 2024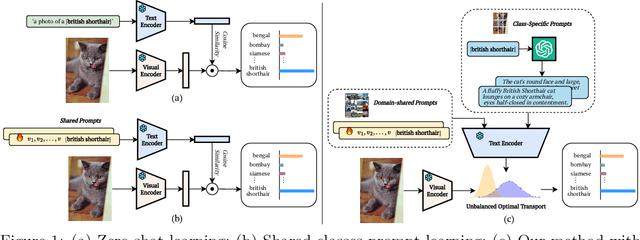
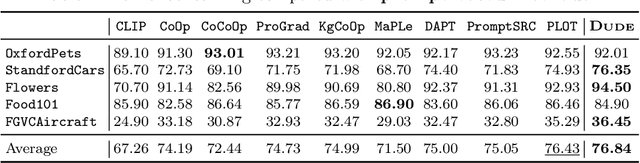
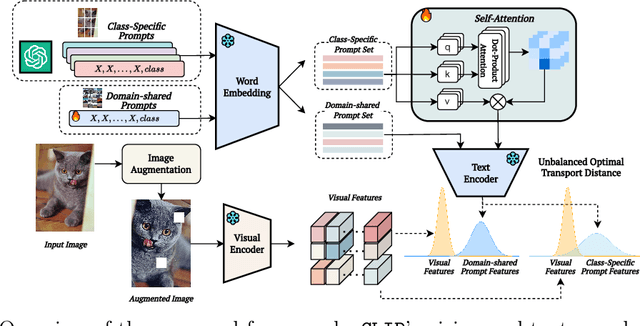
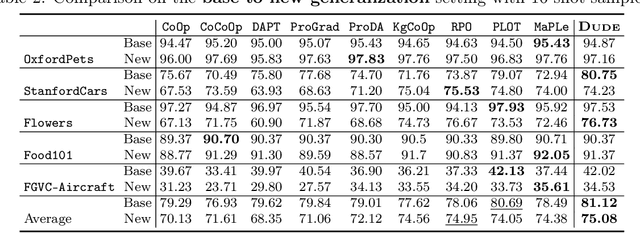
Prompt learning methods are gaining increasing attention due to their ability to customize large vision-language models to new domains using pre-trained contextual knowledge and minimal training data. However, existing works typically rely on optimizing unified prompt inputs, often struggling with fine-grained classification tasks due to insufficient discriminative attributes. To tackle this, we consider a new framework based on a dual context of both domain-shared and class-specific contexts, where the latter is generated by Large Language Models (LLMs) such as GPTs. Such dual prompt methods enhance the model's feature representation by joining implicit and explicit factors encoded in LLM knowledge. Moreover, we formulate the Unbalanced Optimal Transport (UOT) theory to quantify the relationships between constructed prompts and visual tokens. Through partial matching, UOT can properly align discrete sets of visual tokens and prompt embeddings under different mass distributions, which is particularly valuable for handling irrelevant or noisy elements, ensuring that the preservation of mass does not restrict transport solutions. Furthermore, UOT's characteristics integrate seamlessly with image augmentation, expanding the training sample pool while maintaining a reasonable distance between perturbed images and prompt inputs. Extensive experiments across few-shot classification and adapter settings substantiate the superiority of our model over current state-of-the-art baselines.
Structure-Aware E(3)-Invariant Molecular Conformer Aggregation Networks
Feb 03, 2024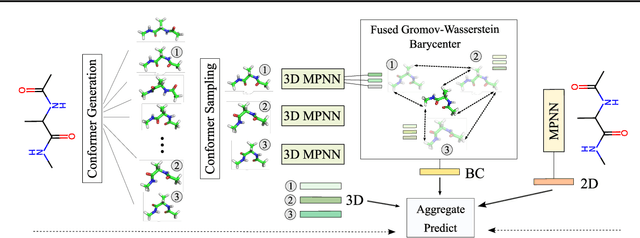

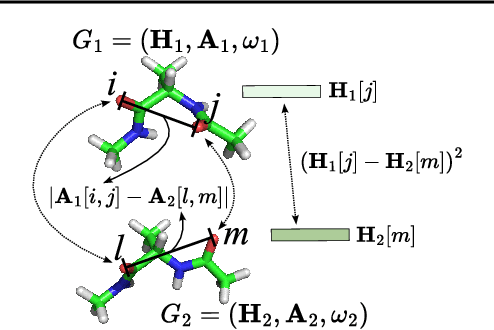

A molecule's 2D representation consists of its atoms, their attributes, and the molecule's covalent bonds. A 3D (geometric) representation of a molecule is called a conformer and consists of its atom types and Cartesian coordinates. Every conformer has a potential energy, and the lower this energy, the more likely it occurs in nature. Most existing machine learning methods for molecular property prediction consider either 2D molecular graphs or 3D conformer structure representations in isolation. Inspired by recent work on using ensembles of conformers in conjunction with 2D graph representations, we propose E(3)-invariant molecular conformer aggregation networks. The method integrates a molecule's 2D representation with that of multiple of its conformers. Contrary to prior work, we propose a novel 2D--3D aggregation mechanism based on a differentiable solver for the \emph{Fused Gromov-Wasserstein Barycenter} problem and the use of an efficient online conformer generation method based on distance geometry. We show that the proposed aggregation mechanism is E(3) invariant and provides an efficient GPU implementation. Moreover, we demonstrate that the aggregation mechanism helps to outperform state-of-the-art property prediction methods on established datasets significantly.
Software Entity Recognition with Noise-Robust Learning
Aug 21, 2023Recognizing software entities such as library names from free-form text is essential to enable many software engineering (SE) technologies, such as traceability link recovery, automated documentation, and API recommendation. While many approaches have been proposed to address this problem, they suffer from small entity vocabularies or noisy training data, hindering their ability to recognize software entities mentioned in sophisticated narratives. To address this challenge, we leverage the Wikipedia taxonomy to develop a comprehensive entity lexicon with 79K unique software entities in 12 fine-grained types, as well as a large labeled dataset of over 1.7M sentences. Then, we propose self-regularization, a noise-robust learning approach, to the training of our software entity recognition (SER) model by accounting for many dropouts. Results show that models trained with self-regularization outperform both their vanilla counterparts and state-of-the-art approaches on our Wikipedia benchmark and two Stack Overflow benchmarks. We release our models, data, and code for future research.
Explanation-based Finetuning Makes Models More Robust to Spurious Cues
May 08, 2023Large Language Models (LLMs) are so powerful that they sometimes learn correlations between labels and features that are irrelevant to the task, leading to poor generalization on out-of-distribution data. We propose explanation-based finetuning as a novel and general approach to mitigate LLMs' reliance on spurious correlations. Unlike standard finetuning where the model only predicts the answer given the input, we finetune the model to additionally generate a free-text explanation supporting its answer. To evaluate our method, we finetune the model on artificially constructed training sets containing different types of spurious cues, and test it on a test set without these cues. Compared to standard finetuning, our method makes models remarkably more robust against spurious cues in terms of accuracy drop across four classification tasks: ComVE (+1.2), CREAK (+9.1), e-SNLI (+15.4), and SBIC (+6.5). Moreover, our method works equally well with explanations generated by the model, implying its applicability to more datasets without human-written explanations.
In-context Example Selection with Influences
Feb 21, 2023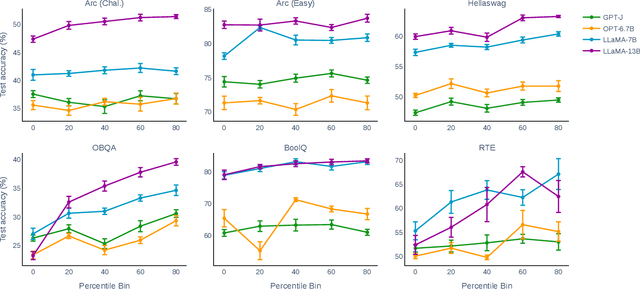
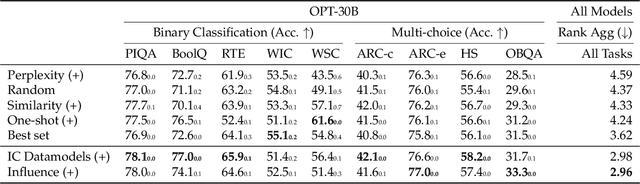

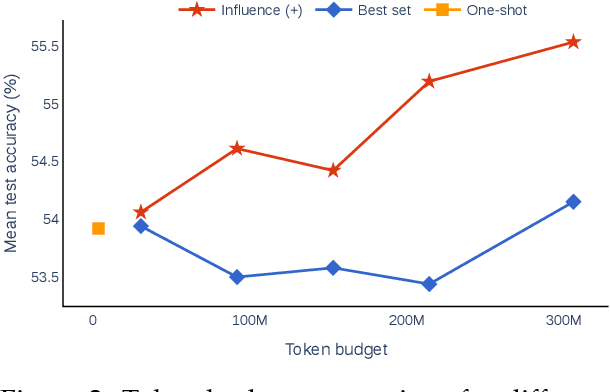
In-context learning (ICL) is a powerful paradigm emerged from large language models (LLMs). Despite its promises, ICL performance is known to be highly sensitive to input examples. In this work, we use in-context influences to analyze few-shot ICL performance directly from the in-context examples. Our proposed influence-based example selection method outperforms most baselines when evaluated on 10 SuperGlue tasks and stably scales with increasing k-shot. The analysis finds up to a 22.2% performance gap between the most positively and negatively influential examples. In a case study, we apply our influence-based framework to quantify the phenomena of recency bias in example ordering for few-shot ICL.