 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
wa-hls4ml: A Benchmark and Surrogate Models for hls4ml Resource and Latency Estimation
Nov 06, 2025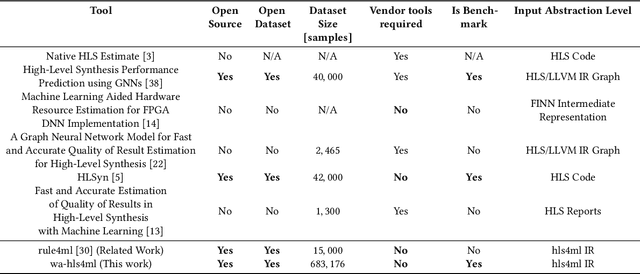
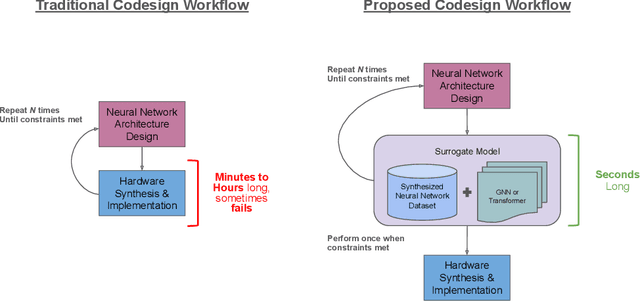

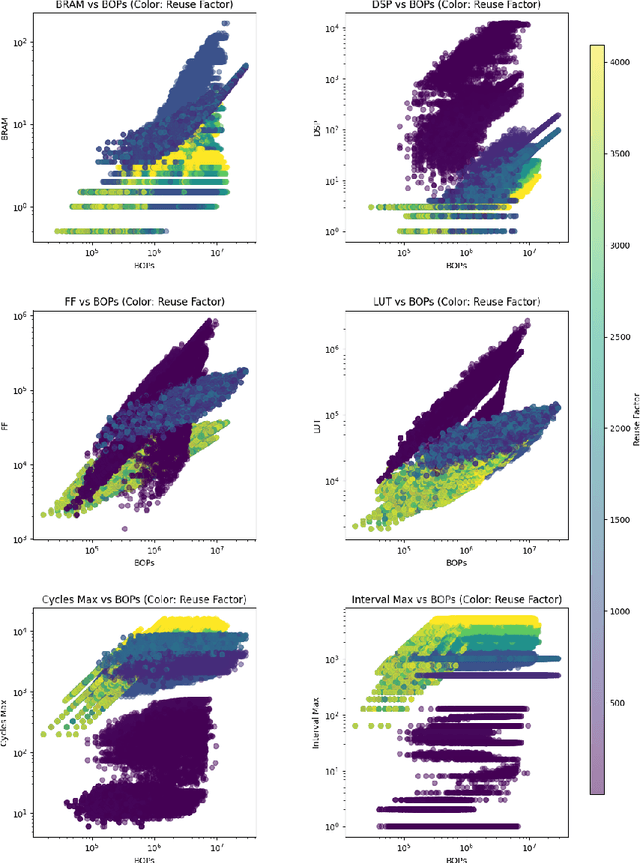
As machine learning (ML) is increasingly implemented in hardware to address real-time challenges in scientific applications, the development of advanced toolchains has significantly reduced the time required to iterate on various designs. These advancements have solved major obstacles, but also exposed new challenges. For example, processes that were not previously considered bottlenecks, such as hardware synthesis, are becoming limiting factors in the rapid iteration of designs. To mitigate these emerging constraints, multiple efforts have been undertaken to develop an ML-based surrogate model that estimates resource usage of ML accelerator architectures. We introduce wa-hls4ml, a benchmark for ML accelerator resource and latency estimation, and its corresponding initial dataset of over 680,000 fully connected and convolutional neural networks, all synthesized using hls4ml and targeting Xilinx FPGAs. The benchmark evaluates the performance of resource and latency predictors against several common ML model architectures, primarily originating from scientific domains, as exemplar models, and the average performance across a subset of the dataset. Additionally, we introduce GNN- and transformer-based surrogate models that predict latency and resources for ML accelerators. We present the architecture and performance of the models and find that the models generally predict latency and resources for the 75% percentile within several percent of the synthesized resources on the synthetic test dataset.
End-to-end workflow for machine learning-based qubit readout with QICK and hls4ml
Jan 24, 2025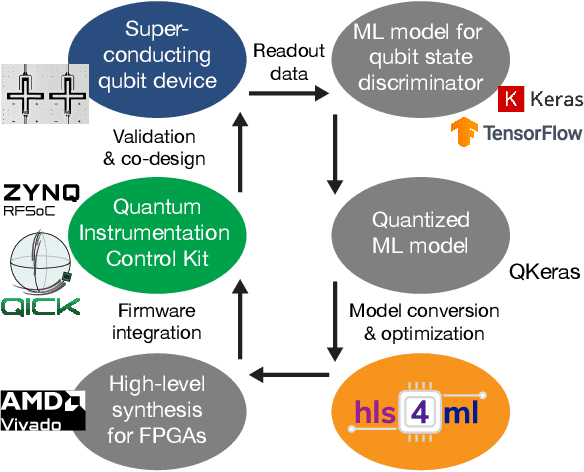
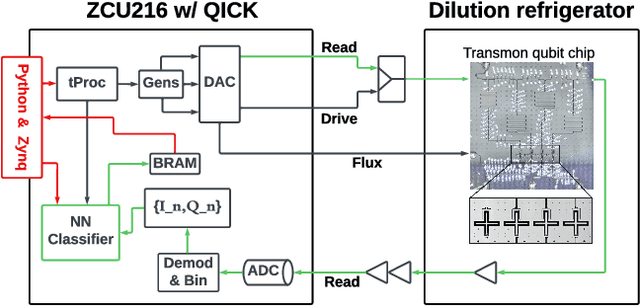
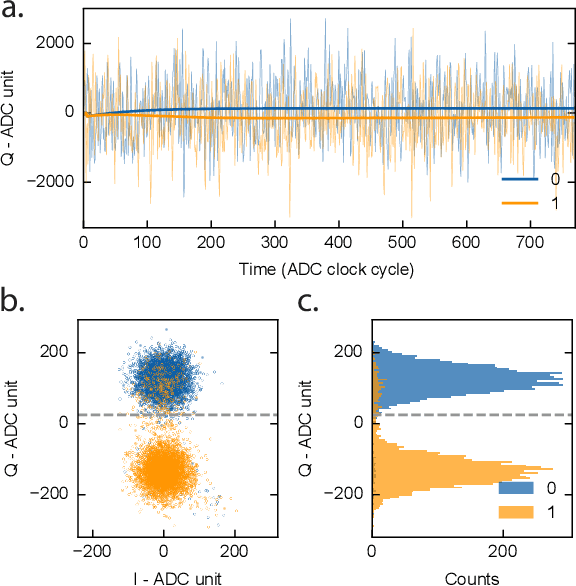

We present an end-to-end workflow for superconducting qubit readout that embeds co-designed Neural Networks (NNs) into the Quantum Instrumentation Control Kit (QICK). Capitalizing on the custom firmware and software of the QICK platform, which is built on Xilinx RFSoC FPGAs, we aim to leverage machine learning (ML) to address critical challenges in qubit readout accuracy and scalability. The workflow utilizes the hls4ml package and employs quantization-aware training to translate ML models into hardware-efficient FPGA implementations via user-friendly Python APIs. We experimentally demonstrate the design, optimization, and integration of an ML algorithm for single transmon qubit readout, achieving 96% single-shot fidelity with a latency of 32ns and less than 16% FPGA look-up table resource utilization. Our results offer the community an accessible workflow to advance ML-driven readout and adaptive control in quantum information processing applications.
Low latency optical-based mode tracking with machine learning deployed on FPGAs on a tokamak
Nov 30, 2023
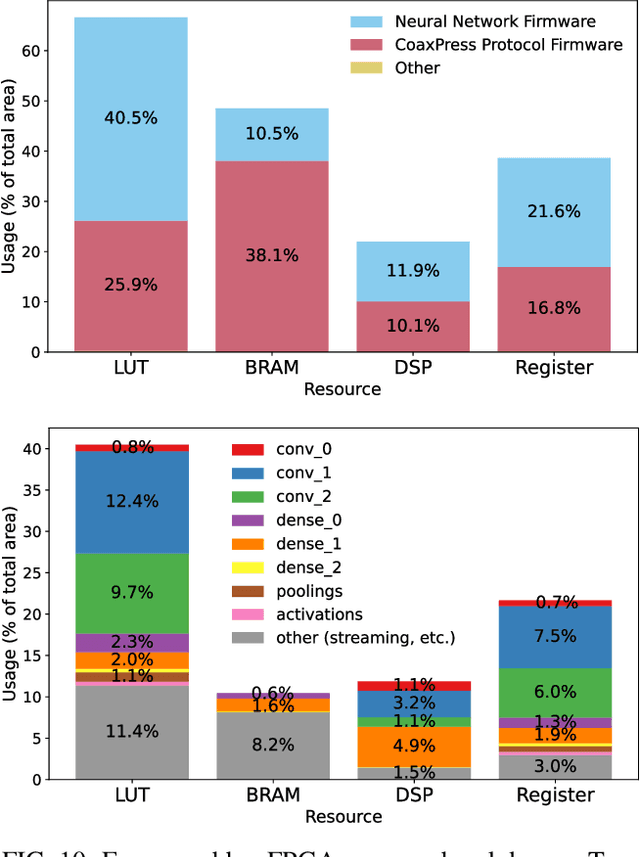
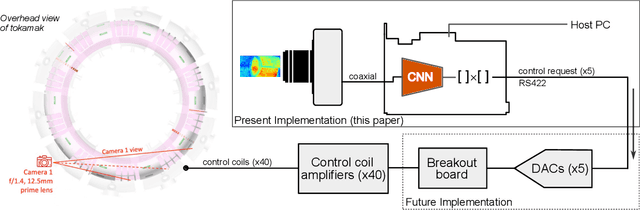

Active feedback control in magnetic confinement fusion devices is desirable to mitigate plasma instabilities and enable robust operation. Optical high-speed cameras provide a powerful, non-invasive diagnostic and can be suitable for these applications. In this study, we process fast camera data, at rates exceeding 100kfps, on $\textit{in situ}$ Field Programmable Gate Array (FPGA) hardware to track magnetohydrodynamic (MHD) mode evolution and generate control signals in real-time. Our system utilizes a convolutional neural network (CNN) model which predicts the $n$=1 MHD mode amplitude and phase using camera images with better accuracy than other tested non-deep-learning-based methods. By implementing this model directly within the standard FPGA readout hardware of the high-speed camera diagnostic, our mode tracking system achieves a total trigger-to-output latency of 17.6$\mu$s and a throughput of up to 120kfps. This study at the High Beta Tokamak-Extended Pulse (HBT-EP) experiment demonstrates an FPGA-based high-speed camera data acquisition and processing system, enabling application in real-time machine-learning-based tokamak diagnostic and control as well as potential applications in other scientific domains.
Neural network accelerator for quantum control
Aug 04, 2022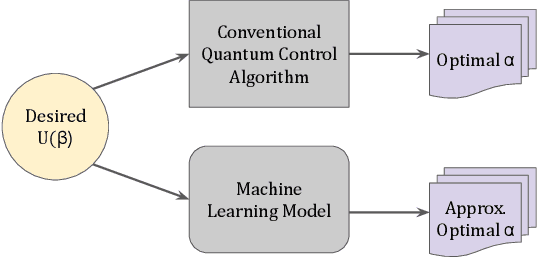
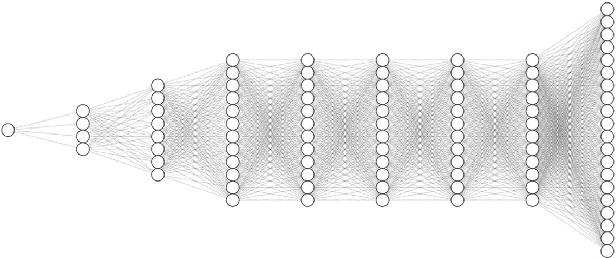
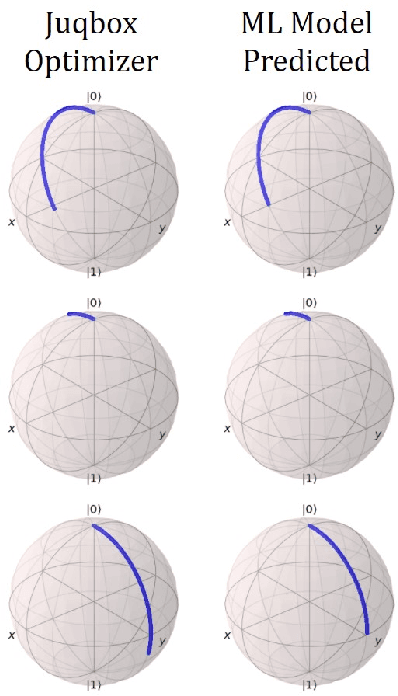
Efficient quantum control is necessary for practical quantum computing implementations with current technologies. Conventional algorithms for determining optimal control parameters are computationally expensive, largely excluding them from use outside of the simulation. Existing hardware solutions structured as lookup tables are imprecise and costly. By designing a machine learning model to approximate the results of traditional tools, a more efficient method can be produced. Such a model can then be synthesized into a hardware accelerator for use in quantum systems. In this study, we demonstrate a machine learning algorithm for predicting optimal pulse parameters. This algorithm is lightweight enough to fit on a low-resource FPGA and perform inference with a latency of 175 ns and pipeline interval of 5 ns with $~>~$0.99 gate fidelity. In the long term, such an accelerator could be used near quantum computing hardware where traditional computers cannot operate, enabling quantum control at a reasonable cost at low latencies without incurring large data bandwidths outside of the cryogenic environment.
Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark
Jun 23, 2022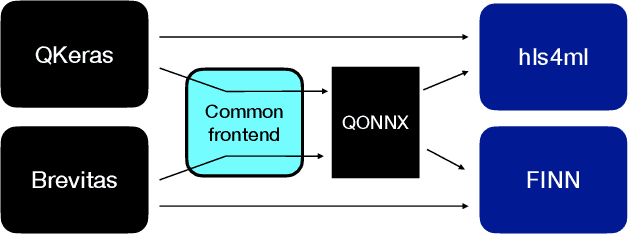
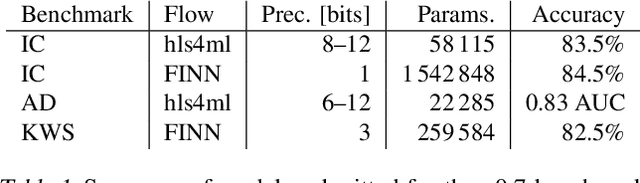
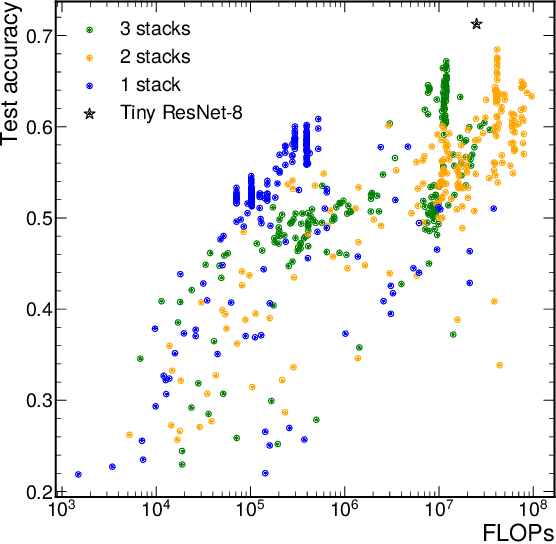
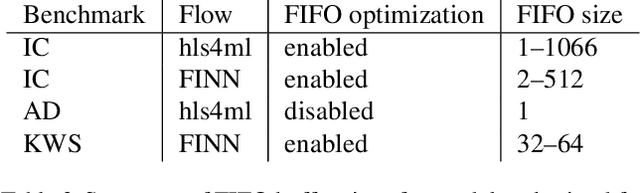
We present our development experience and recent results for the MLPerf Tiny Inference Benchmark on field-programmable gate array (FPGA) platforms. We use the open-source hls4ml and FINN workflows, which aim to democratize AI-hardware codesign of optimized neural networks on FPGAs. We present the design and implementation process for the keyword spotting, anomaly detection, and image classification benchmark tasks. The resulting hardware implementations are quantized, configurable, spatial dataflow architectures tailored for speed and efficiency and introduce new generic optimizations and common workflows developed as a part of this work. The full workflow is presented from quantization-aware training to FPGA implementation. The solutions are deployed on system-on-chip (Pynq-Z2) and pure FPGA (Arty A7-100T) platforms. The resulting submissions achieve latencies as low as 20 $\mu$s and energy consumption as low as 30 $\mu$J per inference. We demonstrate how emerging ML benchmarks on heterogeneous hardware platforms can catalyze collaboration and the development of new techniques and more accessible tools.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021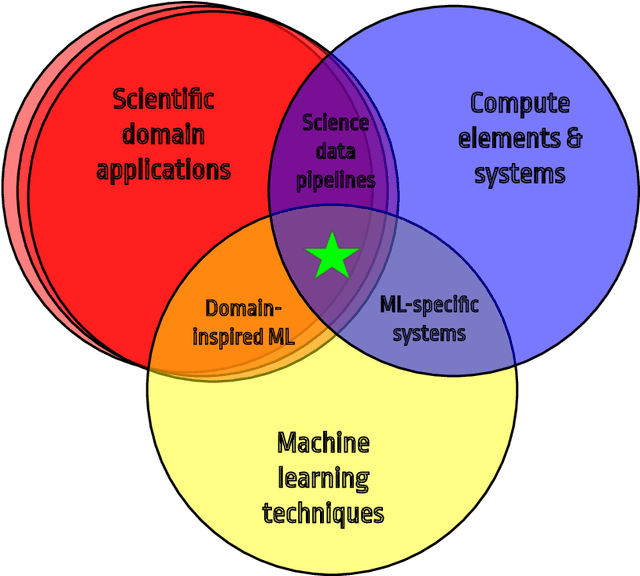
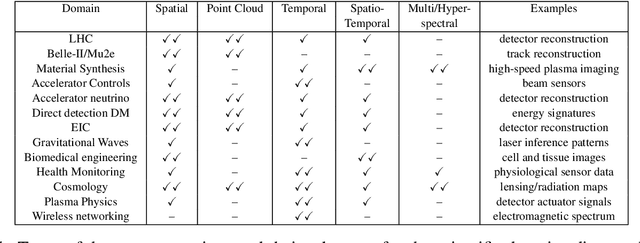
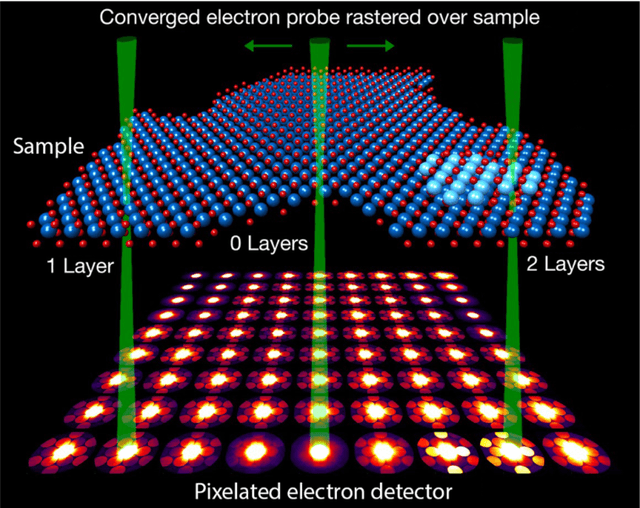
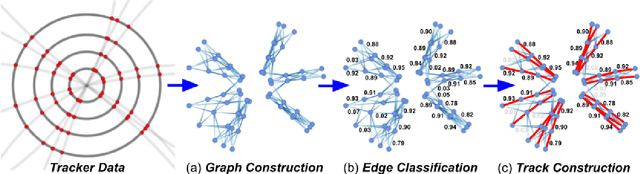
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
MLPerf Tiny Benchmark
Jun 28, 2021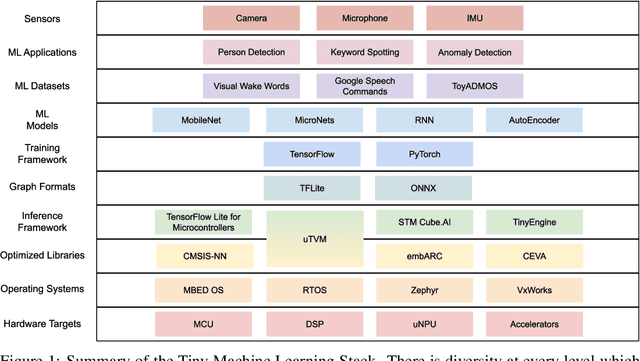
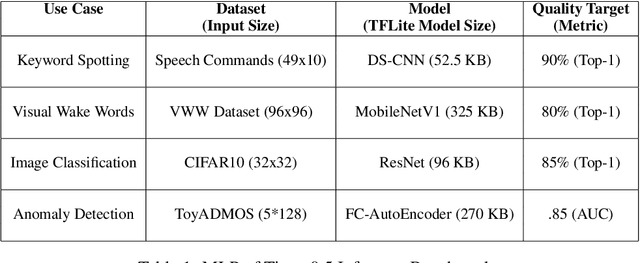
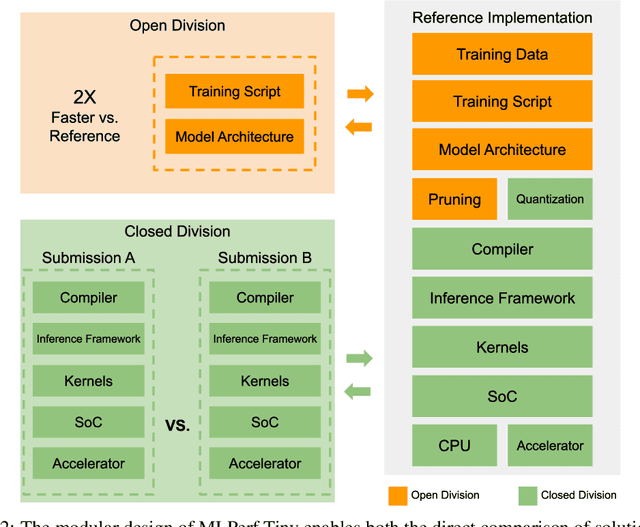
Advancements in ultra-low-power tiny machine learning (TinyML) systems promise to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted and easily reproducible benchmark for these systems. To meet this need, we present MLPerf Tiny, the first industry-standard benchmark suite for ultra-low-power tiny machine learning systems. The benchmark suite is the collaborative effort of more than 50 organizations from industry and academia and reflects the needs of the community. MLPerf Tiny measures the accuracy, latency, and energy of machine learning inference to properly evaluate the tradeoffs between systems. Additionally, MLPerf Tiny implements a modular design that enables benchmark submitters to show the benefits of their product, regardless of where it falls on the ML deployment stack, in a fair and reproducible manner. The suite features four benchmarks: keyword spotting, visual wake words, image classification, and anomaly detection.
A reconfigurable neural network ASIC for detector front-end data compression at the HL-LHC
May 04, 2021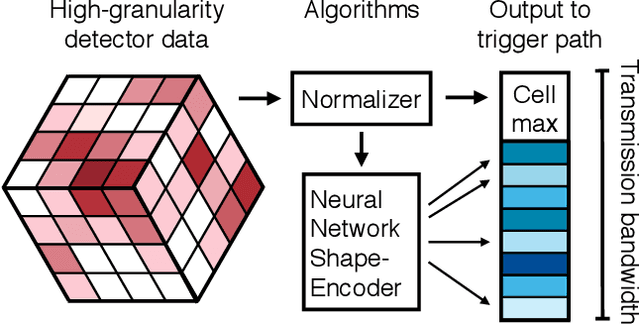
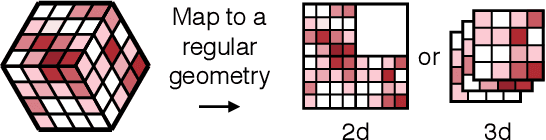
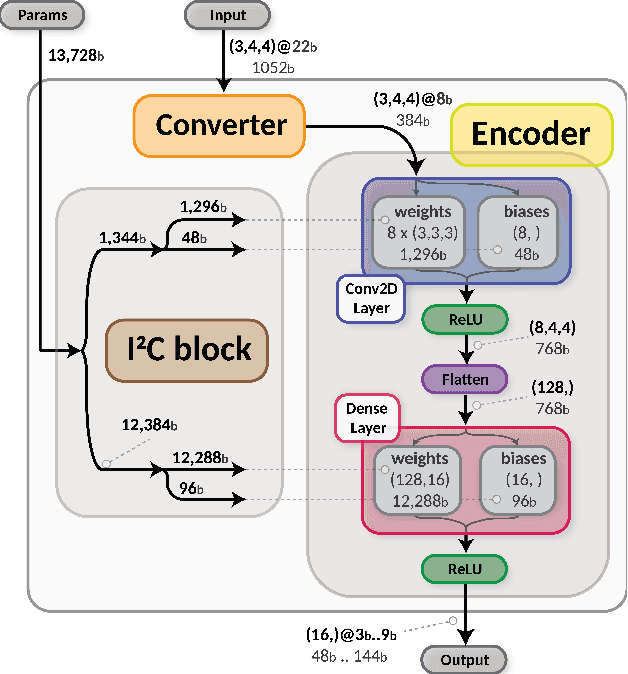
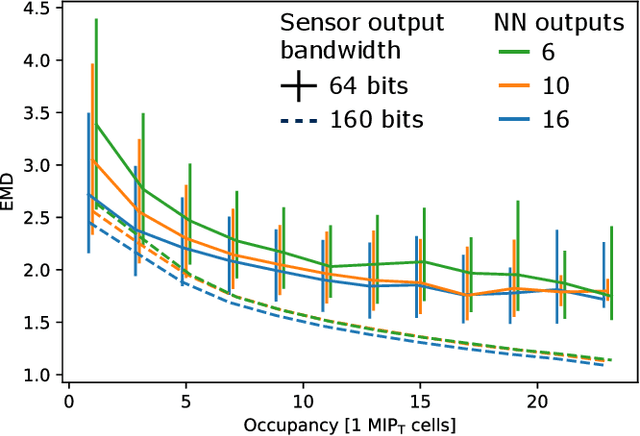
Despite advances in the programmable logic capabilities of modern trigger systems, a significant bottleneck remains in the amount of data to be transported from the detector to off-detector logic where trigger decisions are made. We demonstrate that a neural network autoencoder model can be implemented in a radiation tolerant ASIC to perform lossy data compression alleviating the data transmission problem while preserving critical information of the detector energy profile. For our application, we consider the high-granularity calorimeter from the CMS experiment at the CERN Large Hadron Collider. The advantage of the machine learning approach is in the flexibility and configurability of the algorithm. By changing the neural network weights, a unique data compression algorithm can be deployed for each sensor in different detector regions, and changing detector or collider conditions. To meet area, performance, and power constraints, we perform a quantization-aware training to create an optimized neural network hardware implementation. The design is achieved through the use of high-level synthesis tools and the hls4ml framework, and was processed through synthesis and physical layout flows based on a LP CMOS 65 nm technology node. The flow anticipates 200 Mrad of ionizing radiation to select gates, and reports a total area of 3.6 mm^2 and consumes 95 mW of power. The simulated energy consumption per inference is 2.4 nJ. This is the first radiation tolerant on-detector ASIC implementation of a neural network that has been designed for particle physics applications.
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 23, 2021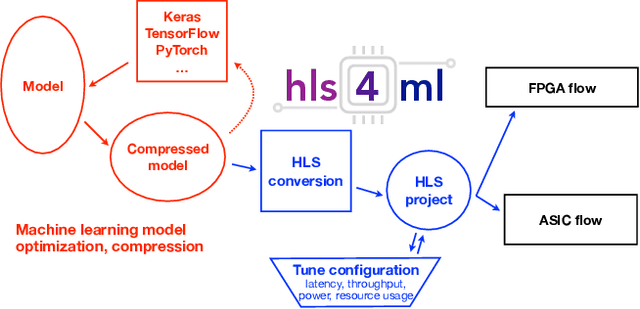
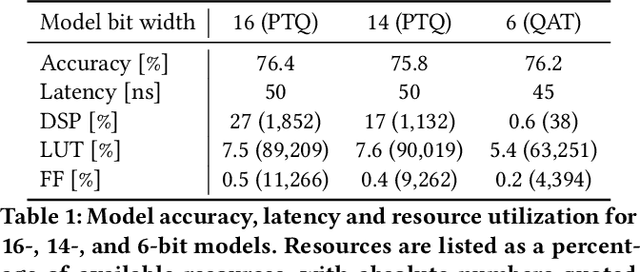
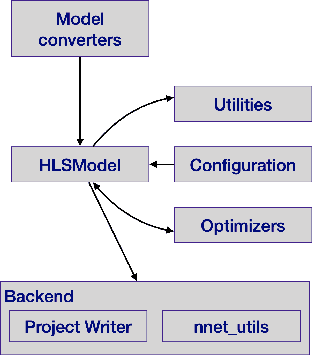
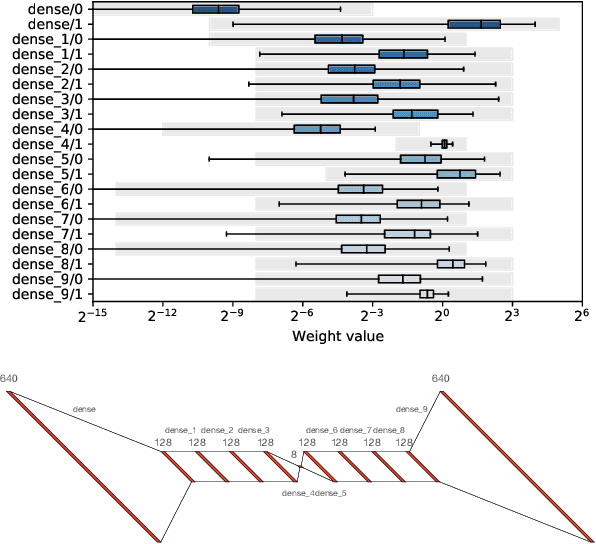
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.