 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Analysis of Deeply Quantized Tiny Neural Networks Robust to Adversarial Attacks
Mar 12, 2025


Reducing the memory footprint of Machine Learning (ML) models, especially Deep Neural Networks (DNNs), is imperative to facilitate their deployment on resource-constrained edge devices. However, a notable drawback of DNN models lies in their susceptibility to adversarial attacks, wherein minor input perturbations can deceive them. A primary challenge revolves around the development of accurate, resilient, and compact DNN models suitable for deployment on resource-constrained edge devices. This paper presents the outcomes of a compact DNN model that exhibits resilience against both black-box and white-box adversarial attacks. This work has achieved this resilience through training with the QKeras quantization-aware training framework. The study explores the potential of QKeras and an adversarial robustness technique, Jacobian Regularization (JR), to co-optimize the DNN architecture through per-layer JR methodology. As a result, this paper has devised a DNN model employing this co-optimization strategy based on Stochastic Ternary Quantization (STQ). Its performance was compared against existing DNN models in the face of various white-box and black-box attacks. The experimental findings revealed that, the proposed DNN model had small footprint and on average, it exhibited better performance than Quanos and DS-CNN MLCommons/TinyML (MLC/T) benchmarks when challenged with white-box and black-box attacks, respectively, on the CIFAR-10 image and Google Speech Commands audio datasets.
Improving Robustness Against Adversarial Attacks with Deeply Quantized Neural Networks
Apr 25, 2023



Reducing the memory footprint of Machine Learning (ML) models, particularly Deep Neural Networks (DNNs), is essential to enable their deployment into resource-constrained tiny devices. However, a disadvantage of DNN models is their vulnerability to adversarial attacks, as they can be fooled by adding slight perturbations to the inputs. Therefore, the challenge is how to create accurate, robust, and tiny DNN models deployable on resource-constrained embedded devices. This paper reports the results of devising a tiny DNN model, robust to adversarial black and white box attacks, trained with an automatic quantizationaware training framework, i.e. QKeras, with deep quantization loss accounted in the learning loop, thereby making the designed DNNs more accurate for deployment on tiny devices. We investigated how QKeras and an adversarial robustness technique, Jacobian Regularization (JR), can provide a co-optimization strategy by exploiting the DNN topology and the per layer JR approach to produce robust yet tiny deeply quantized DNN models. As a result, a new DNN model implementing this cooptimization strategy was conceived, developed and tested on three datasets containing both images and audio inputs, as well as compared its performance with existing benchmarks against various white-box and black-box attacks. Experimental results demonstrated that on average our proposed DNN model resulted in 8.3% and 79.5% higher accuracy than MLCommons/Tiny benchmarks in the presence of white-box and black-box attacks on the CIFAR-10 image dataset and a subset of the Google Speech Commands audio dataset respectively. It was also 6.5% more accurate for black-box attacks on the SVHN image dataset.
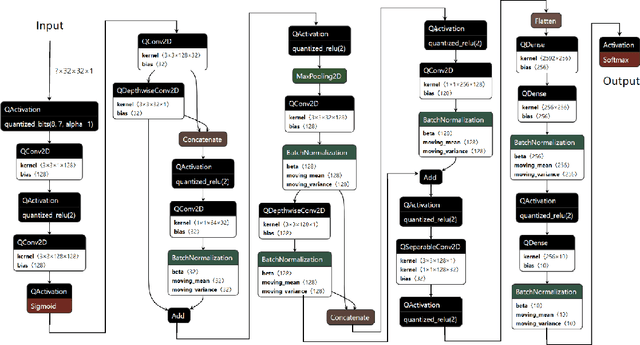
Resource Constrained Neural Networks for 5G Direction-of-Arrival Estimation in Micro-controllers
Jul 23, 2021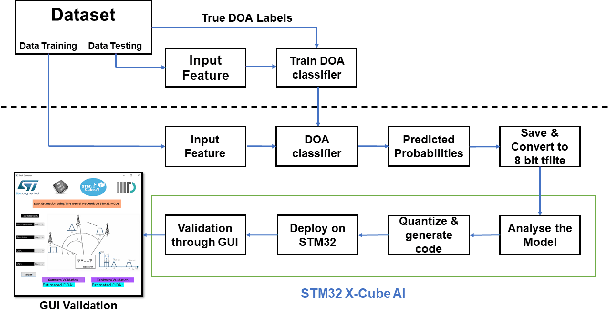
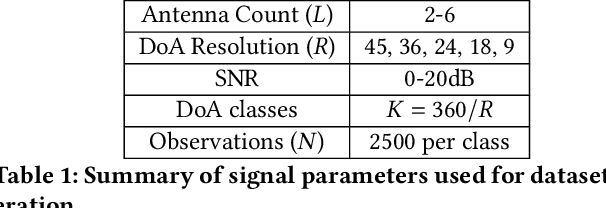
With the introduction of shared spectrum sensing and beam-forming based multi-antenna transceivers, 5G networks demand spectrum sensing to identify opportunities in time, frequency, and spatial domains. Narrow beam-forming makes it difficult to have spatial sensing (direction-of-arrival, DoA, estimation) in a centralized manner, and with the evolution of paradigms such as artificial intelligence of Things (AIOT), ultra-reliable low latency communication (URLLC) services and distributed networks, intelligence for edge devices (Edge-AI) is highly desirable. It helps to reduce the data-communication overhead compared to cloud-AI-centric networks and is more secure and free from scalability limitations. However, achieving desired functional accuracy is a challenge on edge devices such as microcontroller units (MCU) due to area, memory, and power constraints. In this work, we propose low complexity neural network-based algorithm for accurate DoA estimation and its efficient mapping on the off-the-self MCUs. An ad-hoc graphical-user interface (GUI) is developed to configure the STM32 NUCLEO-H743ZI2 MCU with the proposed algorithm and to validate its functionality. The performance of the proposed algorithm is analyzed for different signal-to-noise ratios (SNR), word-length, the number of antennas, and DoA resolution. In-depth experimental results show that it outperforms the conventional statistical spatial sensing approach.
MLPerf Tiny Benchmark
Jun 28, 2021
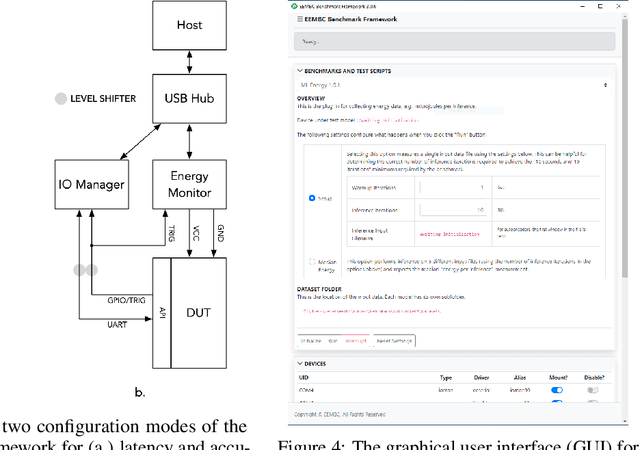
Advancements in ultra-low-power tiny machine learning (TinyML) systems promise to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted and easily reproducible benchmark for these systems. To meet this need, we present MLPerf Tiny, the first industry-standard benchmark suite for ultra-low-power tiny machine learning systems. The benchmark suite is the collaborative effort of more than 50 organizations from industry and academia and reflects the needs of the community. MLPerf Tiny measures the accuracy, latency, and energy of machine learning inference to properly evaluate the tradeoffs between systems. Additionally, MLPerf Tiny implements a modular design that enables benchmark submitters to show the benefits of their product, regardless of where it falls on the ML deployment stack, in a fair and reproducible manner. The suite features four benchmarks: keyword spotting, visual wake words, image classification, and anomaly detection.
Characterization of Neural Networks Automatically Mapped on Automotive-grade Microcontrollers
Feb 27, 2021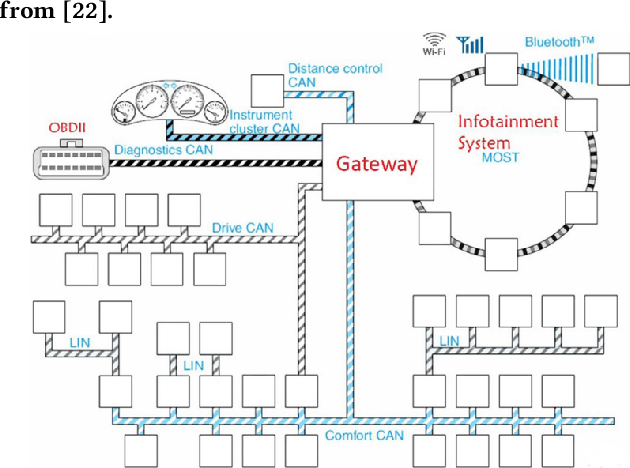


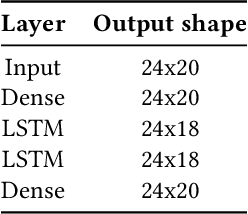
Nowadays, Neural Networks represent a major expectation for the realization of powerful Deep Learning algorithms, which can determine several physical systems' behaviors and operations. Computational resources required for model, training, and running are large, especially when related to the amount of data that Neural Networks typically need to generalize. The latest TinyML technologies allow integrating pre-trained models on embedded systems, allowing making computing at the edge faster, cheaper, and safer. Although these technologies originated in the consumer and industrial worlds, many sectors can greatly benefit from them, such as the automotive industry. In this paper, we present a framework for implementing Neural Network-based models on a family of automotive Microcontrollers, showing their efficiency in two case studies applied to vehicles: intrusion detection on the Controller Area Network bus and residual capacity estimation in Lithium-Ion batteries, widely used in Electric Vehicles.
Benchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020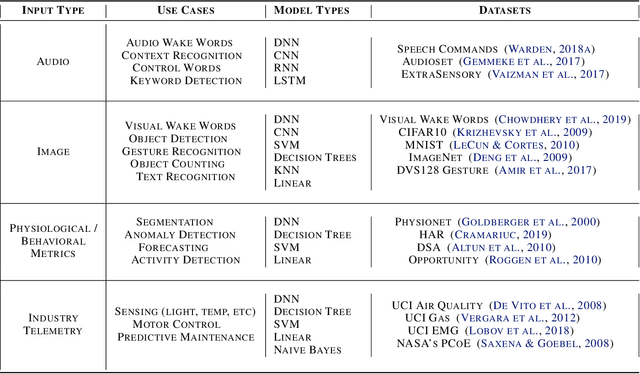
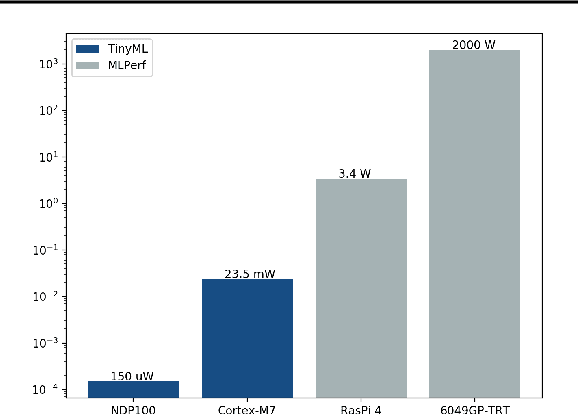
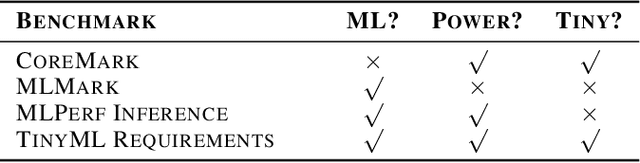
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.
Reduced Memory Region Based Deep Convolutional Neural Network Detection
Sep 08, 2016
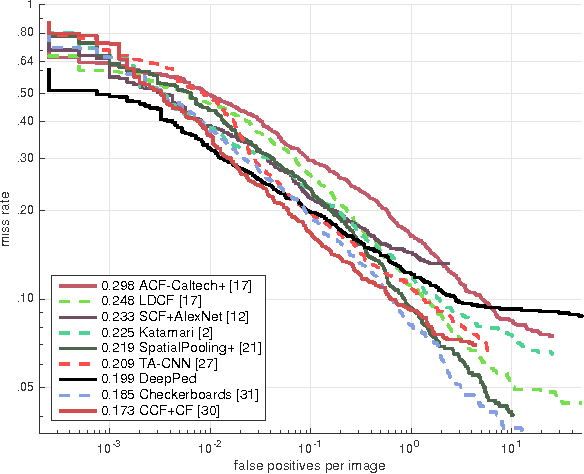
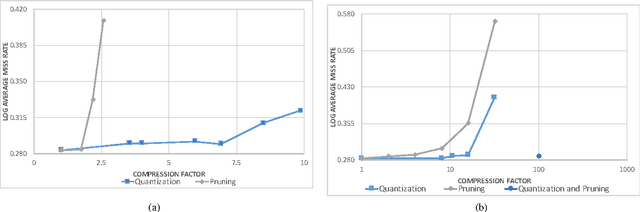
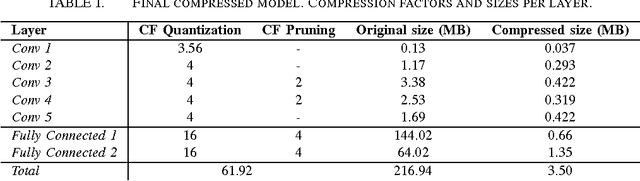
Accurate pedestrian detection has a primary role in automotive safety: for example, by issuing warnings to the driver or acting actively on car's brakes, it helps decreasing the probability of injuries and human fatalities. In order to achieve very high accuracy, recent pedestrian detectors have been based on Convolutional Neural Networks (CNN). Unfortunately, such approaches require vast amounts of computational power and memory, preventing efficient implementations on embedded systems. This work proposes a CNN-based detector, adapting a general-purpose convolutional network to the task at hand. By thoroughly analyzing and optimizing each step of the detection pipeline, we develop an architecture that outperforms methods based on traditional image features and achieves an accuracy close to the state-of-the-art while having low computational complexity. Furthermore, the model is compressed in order to fit the tight constrains of low power devices with a limited amount of embedded memory available. This paper makes two main contributions: (1) it proves that a region based deep neural network can be finely tuned to achieve adequate accuracy for pedestrian detection (2) it achieves a very low memory usage without reducing detection accuracy on the Caltech Pedestrian dataset.
* IEEE 2016 ICCE-Berlin
A Multi-signal Variant for the GPU-based Parallelization of Growing Self-Organizing Networks
Mar 28, 2015
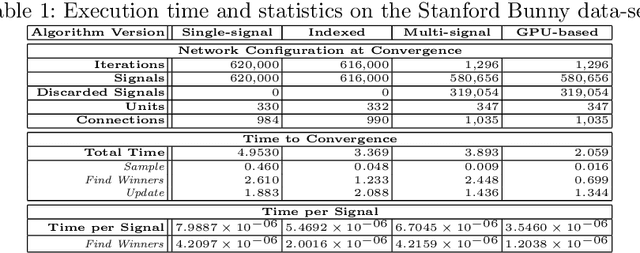
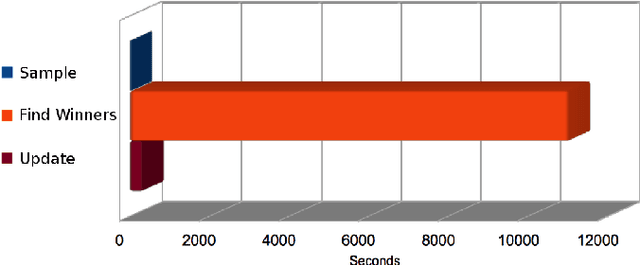
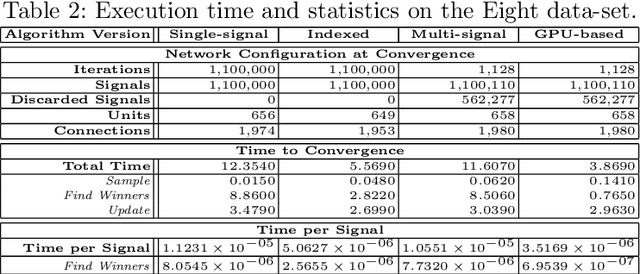
Among the many possible approaches for the parallelization of self-organizing networks, and in particular of growing self-organizing networks, perhaps the most common one is producing an optimized, parallel implementation of the standard sequential algorithms reported in the literature. In this paper we explore an alternative approach, based on a new algorithm variant specifically designed to match the features of the large-scale, fine-grained parallelism of GPUs, in which multiple input signals are processed at once. Comparative tests have been performed, using both parallel and sequential implementations of the new algorithm variant, in particular for a growing self-organizing network that reconstructs surfaces from point clouds. The experimental results show that this approach allows harnessing in a more effective way the intrinsic parallelism that the self-organizing networks algorithms seem intuitively to suggest, obtaining better performances even with networks of smaller size.
* 17 pages