 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeze and Learn: Continual Learning with Selective Freezing for Speech Deepfake Detection
Sep 26, 2024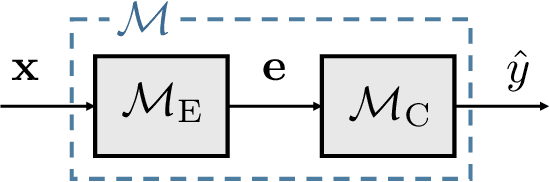
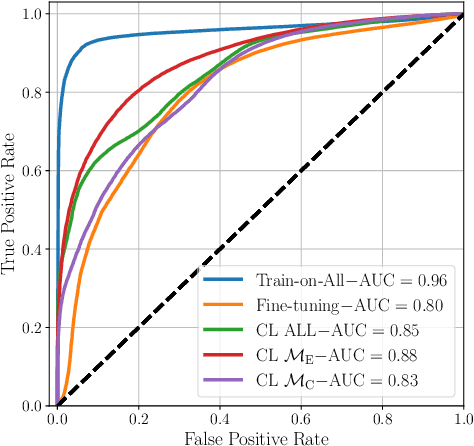
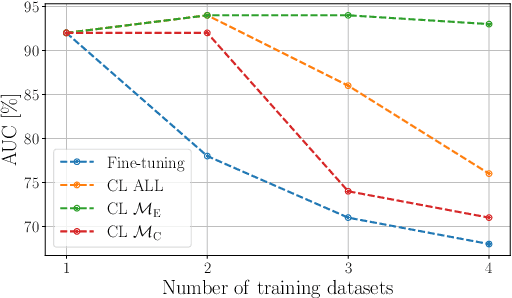
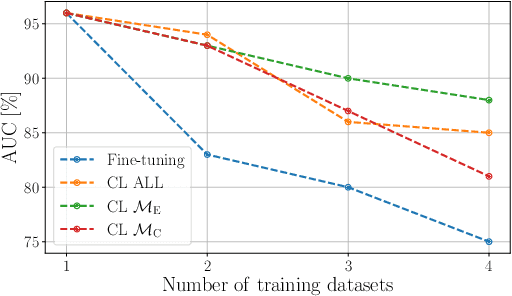
In speech deepfake detection, one of the critical aspects is developing detectors able to generalize on unseen data and distinguish fake signals across different datasets. Common approaches to this challenge involve incorporating diverse data into the training process or fine-tuning models on unseen datasets. However, these solutions can be computationally demanding and may lead to the loss of knowledge acquired from previously learned data. Continual learning techniques offer a potential solution to this problem, allowing the models to learn from unseen data without losing what they have already learned. Still, the optimal way to apply these algorithms for speech deepfake detection remains unclear, and we do not know which is the best way to apply these algorithms to the developed models. In this paper we address this aspect and investigate whether, when retraining a speech deepfake detector, it is more effective to apply continual learning across the entire model or to update only some of its layers while freezing others. Our findings, validated across multiple models, indicate that the most effective approach among the analyzed ones is to update only the weights of the initial layers, which are responsible for processing the input features of the detector.
Can Synthetic Data Boost the Training of Deep Acoustic Vehicle Counting Networks?
Jan 17, 2024
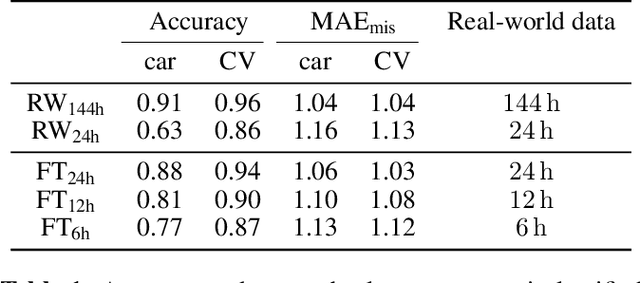
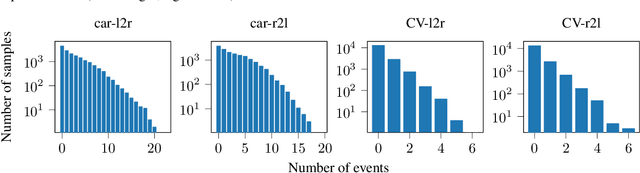
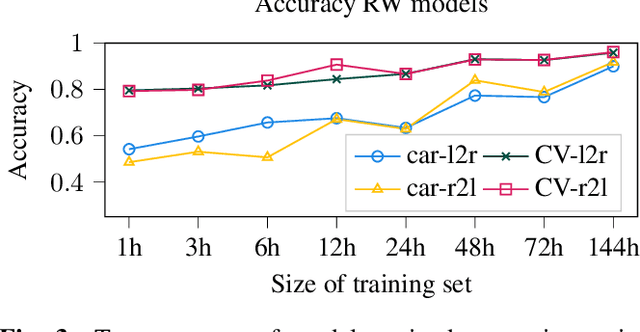
In the design of traffic monitoring solutions for optimizing the urban mobility infrastructure, acoustic vehicle counting models have received attention due to their cost effectiveness and energy efficiency. Although deep learning has proven effective for visual traffic monitoring, its use has not been thoroughly investigated in the audio domain, likely due to real-world data scarcity. In this work, we propose a novel approach to acoustic vehicle counting by developing: i) a traffic noise simulation framework to synthesize realistic vehicle pass-by events; ii) a strategy to mix synthetic and real data to train a deep-learning model for traffic counting. The proposed system is capable of simultaneously counting cars and commercial vehicles driving on a two-lane road, and identifying their direction of travel under moderate traffic density conditions. With only 24 hours of labeled real-world traffic noise, we are able to improve counting accuracy on real-world data from $63\%$ to $88\%$ for cars and from $86\%$ to $94\%$ for commercial vehicles.
Learning Audio Concepts from Counterfactual Natural Language
Jan 10, 2024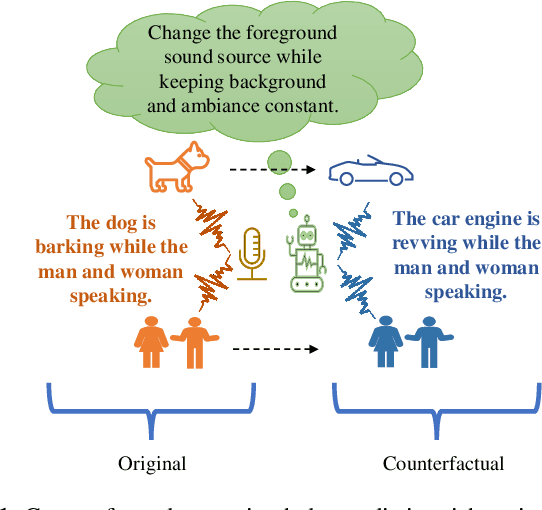
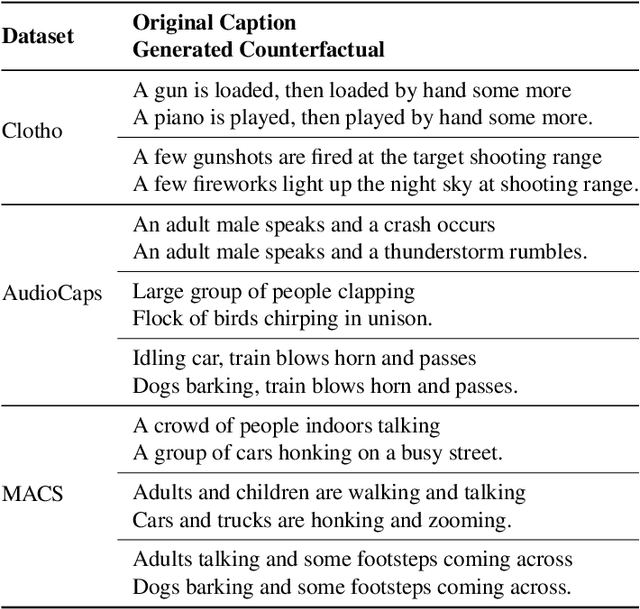

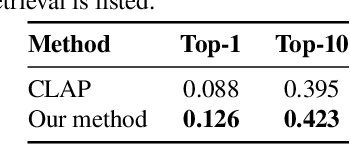
Conventional audio classification relied on predefined classes, lacking the ability to learn from free-form text. Recent methods unlock learning joint audio-text embeddings from raw audio-text pairs describing audio in natural language. Despite recent advancements, there is little exploration of systematic methods to train models for recognizing sound events and sources in alternative scenarios, such as distinguishing fireworks from gunshots at outdoor events in similar situations. This study introduces causal reasoning and counterfactual analysis in the audio domain. We use counterfactual instances and include them in our model across different aspects. Our model considers acoustic characteristics and sound source information from human-annotated reference texts. To validate the effectiveness of our model, we conducted pre-training utilizing multiple audio captioning datasets. We then evaluate with several common downstream tasks, demonstrating the merits of the proposed method as one of the first works leveraging counterfactual information in audio domain. Specifically, the top-1 accuracy in open-ended language-based audio retrieval task increased by more than 43%.
Two vs. Four-Channel Sound Event Localization and Detection
Sep 23, 2023Sound event localization and detection (SELD) systems estimate both the direction-of-arrival (DOA) and class of sound sources over time. In the DCASE 2022 SELD Challenge (Task 3), models are designed to operate in a 4-channel setting. While beneficial to further the development of SELD systems using a multichannel recording setup such as first-order Ambisonics (FOA), most consumer electronics devices rarely are able to record using more than two channels. For this reason, in this work we investigate the performance of the DCASE 2022 SELD baseline model using three audio input representations: FOA, binaural, and stereo. We perform a novel comparative analysis illustrating the effect of these audio input representations on SELD performance. Crucially, we show that binaural and stereo (i.e. 2-channel) audio-based SELD models are still able to localize and detect sound sources laterally quite well, despite overall performance degrading as less audio information is provided. Further, we segment our analysis by scenes containing varying degrees of sound source polyphony to better understand the effect of audio input representation on localization and detection performance as scene conditions become increasingly complex.
Knowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation
Dec 21, 2022



Generalisation to unseen contexts remains a challenge for embodied navigation agents. In the context of semantic audio-visual navigation (SAVi) tasks, the notion of generalisation should include both generalising to unseen indoor visual scenes as well as generalising to unheard sounding objects. However, previous SAVi task definitions do not include evaluation conditions on truly novel sounding objects, resorting instead to evaluating agents on unheard sound clips of known objects; meanwhile, previous SAVi methods do not include explicit mechanisms for incorporating domain knowledge about object and region semantics. These weaknesses limit the development and assessment of models' abilities to generalise their learned experience. In this work, we introduce the use of knowledge-driven scene priors in the semantic audio-visual embodied navigation task: we combine semantic information from our novel knowledge graph that encodes object-region relations, spatial knowledge from dual Graph Encoder Networks, and background knowledge from a series of pre-training tasks -- all within a reinforcement learning framework for audio-visual navigation. We also define a new audio-visual navigation sub-task, where agents are evaluated on novel sounding objects, as opposed to unheard clips of known objects. We show improvements over strong baselines in generalisation to unseen regions and novel sounding objects, within the Habitat-Matterport3D simulation environment, under the SoundSpaces task.
Learning to Adapt to Domain Shifts with Few-shot Samples in Anomalous Sound Detection
Apr 05, 2022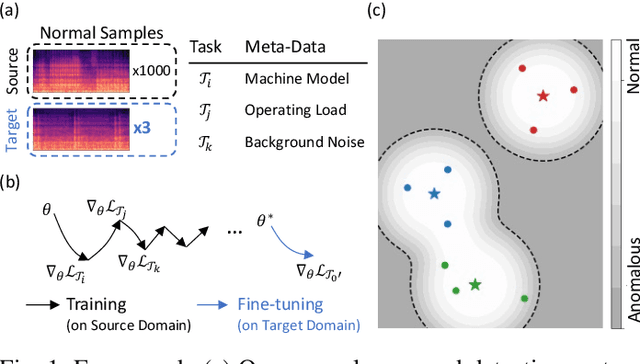


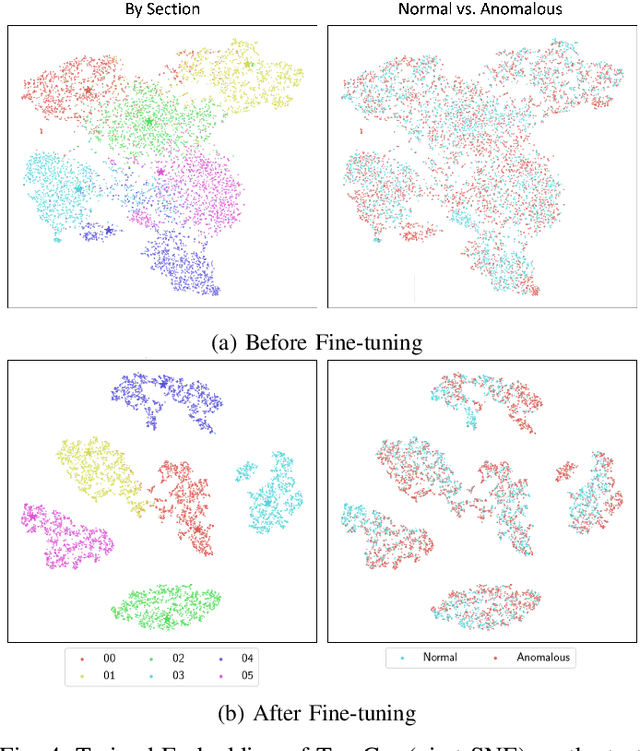
Anomaly detection has many important applications, such as monitoring industrial equipment. Despite recent advances in anomaly detection with deep-learning methods, it is unclear how existing solutions would perform under out-of-distribution scenarios, e.g., due to shifts in machine load or environmental noise. Grounded in the application of machine health monitoring, we propose a framework that adapts to new conditions with few-shot samples. Building upon prior work, we adopt a classification-based approach for anomaly detection and show its equivalence to mixture density estimation of the normal samples. We incorporate an episodic training procedure to match the few-shot setting during inference. We define multiple auxiliary classification tasks based on meta-information and leverage gradient-based meta-learning to improve generalization to different shifts. We evaluate our proposed method on a recently-released dataset of audio measurements from different machine types. It improved upon two baselines by around 10% and is on par with best-performing model reported on the dataset.
Training Strategies and Data Augmentations in CNN-based DeepFake Video Detection
Nov 16, 2020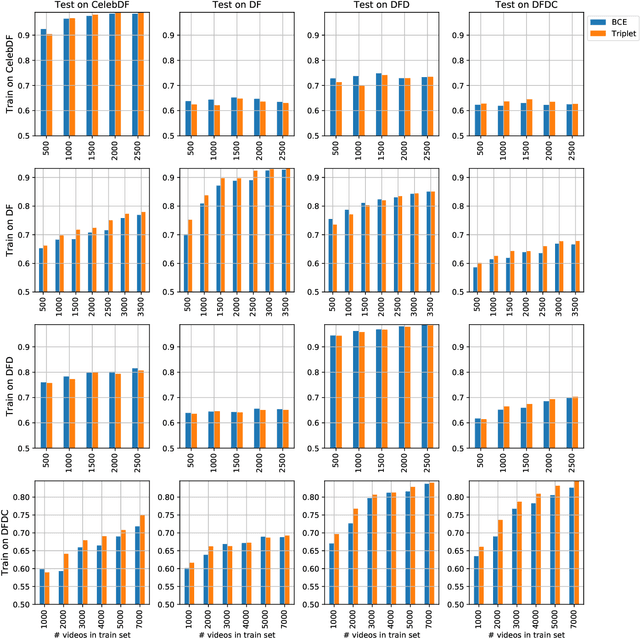
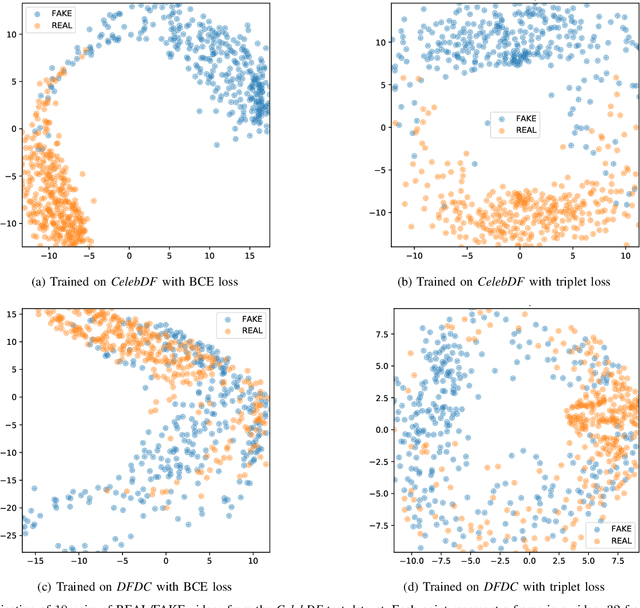
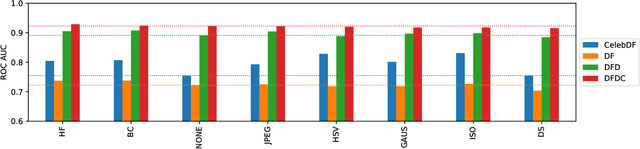
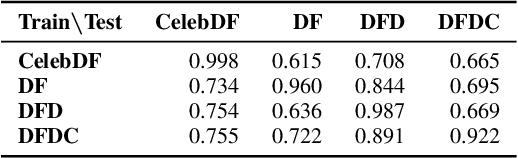
The fast and continuous growth in number and quality of deepfake videos calls for the development of reliable detection systems capable of automatically warning users on social media and on the Internet about the potential untruthfulness of such contents. While algorithms, software, and smartphone apps are getting better every day in generating manipulated videos and swapping faces, the accuracy of automated systems for face forgery detection in videos is still quite limited and generally biased toward the dataset used to design and train a specific detection system. In this paper we analyze how different training strategies and data augmentation techniques affect CNN-based deepfake detectors when training and testing on the same dataset or across different datasets.
Video Face Manipulation Detection Through Ensemble of CNNs
Apr 16, 2020
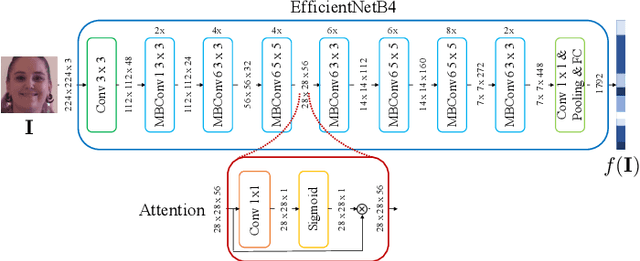

In the last few years, several techniques for facial manipulation in videos have been successfully developed and made available to the masses (i.e., FaceSwap, deepfake, etc.). These methods enable anyone to easily edit faces in video sequences with incredibly realistic results and a very little effort. Despite the usefulness of these tools in many fields, if used maliciously, they can have a significantly bad impact on society (e.g., fake news spreading, cyber bullying through fake revenge porn). The ability of objectively detecting whether a face has been manipulated in a video sequence is then a task of utmost importance. In this paper, we tackle the problem of face manipulation detection in video sequences targeting modern facial manipulation techniques. In particular, we study the ensembling of different trained Convolutional Neural Network (CNN) models. In the proposed solution, different models are obtained starting from a base network (i.e., EfficientNetB4) making use of two different concepts: (i) attention layers; (ii) siamese training. We show that combining these networks leads to promising face manipulation detection results on two publicly available datasets with more than 119000 videos.
An In-Depth Study on Open-Set Camera Model Identification
Apr 11, 2019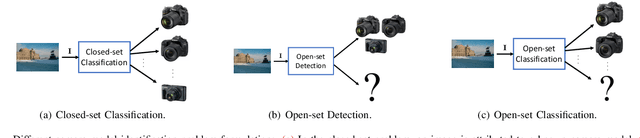
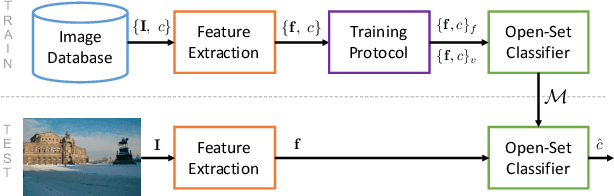
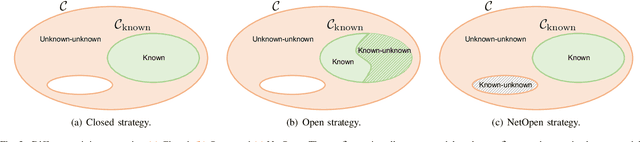
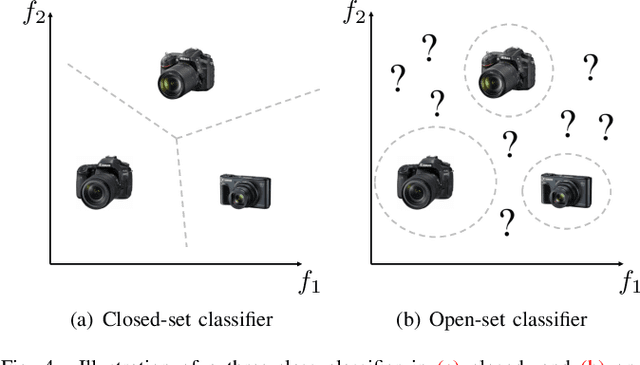
Camera model identification refers to the problem of linking a picture to the camera model used to shoot it. As this might be an enabling factor in different forensic applications to single out possible suspects (e.g., detecting the author of child abuse or terrorist propaganda material), many accurate camera model attribution methods have been developed in the literature. One of their main drawbacks, however, is the typical closed-set assumption of the problem. This means that an investigated photograph is always assigned to one camera model within a set of known ones present during investigation, i.e., training time, and the fact that the picture can come from a completely unrelated camera model during actual testing is usually ignored. Under realistic conditions, it is not possible to assume that every picture under analysis belongs to one of the available camera models. To deal with this issue, in this paper, we present the first in-depth study on the possibility of solving the camera model identification problem in open-set scenarios. Given a photograph, we aim at detecting whether it comes from one of the known camera models of interest or from an unknown device. We compare different feature extraction algorithms and classifiers specially targeting open-set recognition. We also evaluate possible open-set training protocols that can be applied along with any open-set classifier. More specifically, we evaluate one training protocol targeted for open-set classifiers with deep features. We observe that a simpler version of those training protocols works with similar results to the one that requires extra data, which can be useful in many applications in which deep features are employed. Thorough testing on independent datasets shows that it is possible to leverage a recently proposed convolutional neural network as feature extractor paired with a properly trained open-set classifier...
A Counter-Forensic Method for CNN-Based Camera Model Identification
May 06, 2018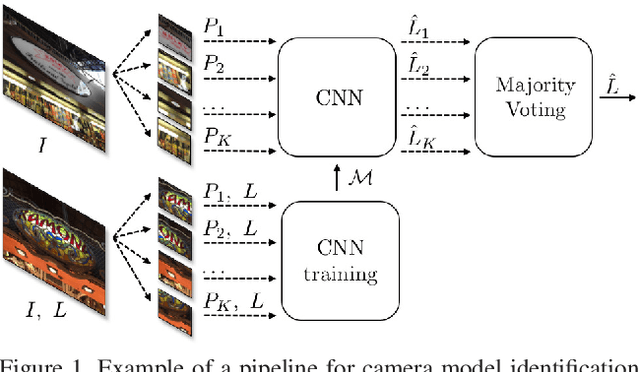
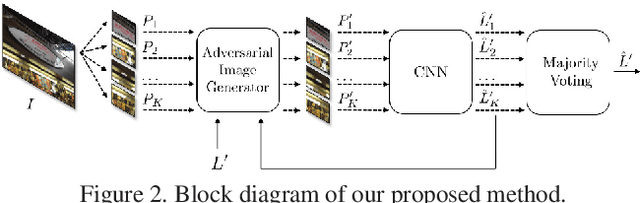

An increasing number of digital images are being shared and accessed through websites, media, and social applications. Many of these images have been modified and are not authentic. Recent advances in the use of deep convolutional neural networks (CNNs) have facilitated the task of analyzing the veracity and authenticity of largely distributed image datasets. We examine in this paper the problem of identifying the camera model or type that was used to take an image and that can be spoofed. Due to the linear nature of CNNs and the high-dimensionality of images, neural networks are vulnerable to attacks with adversarial examples. These examples are imperceptibly different from correctly classified images but are misclassified with high confidence by CNNs. In this paper, we describe a counter-forensic method capable of subtly altering images to change their estimated camera model when they are analyzed by any CNN-based camera model detector. Our method can use both the Fast Gradient Sign Method (FGSM) or the Jacobian-based Saliency Map Attack (JSMA) to craft these adversarial images and does not require direct access to the CNN. Our results show that even advanced deep learning architectures trained to analyze images and obtain camera model information are still vulnerable to our proposed method.