 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies and Data Augmentations in CNN-based DeepFake Video Detection
Paper and Code
Nov 16, 2020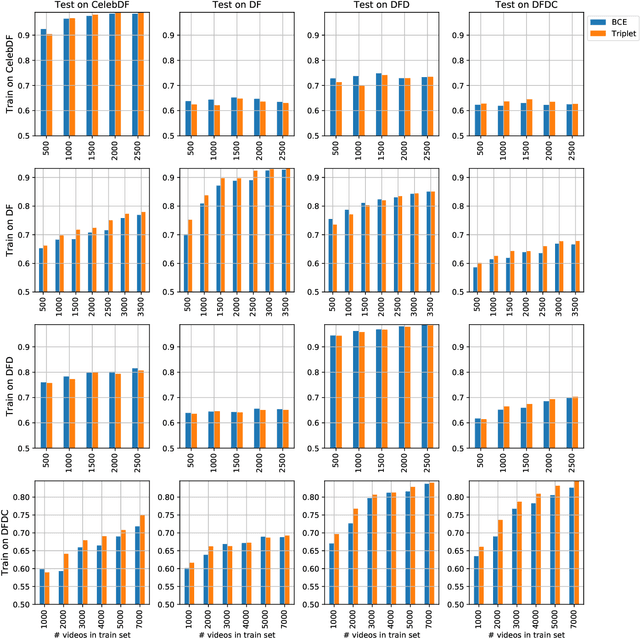
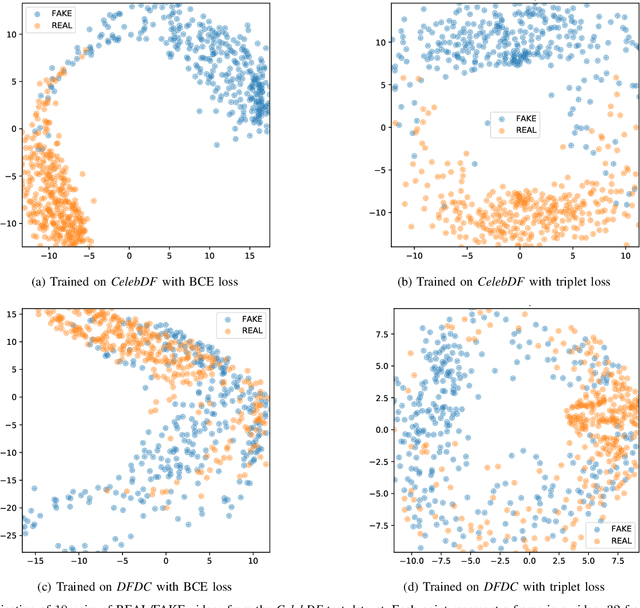
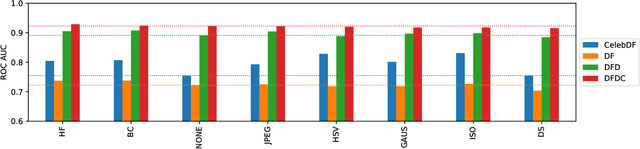
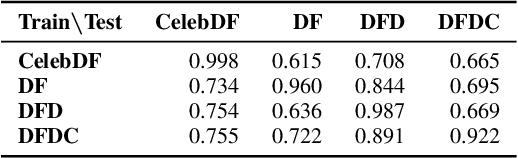
The fast and continuous growth in number and quality of deepfake videos calls for the development of reliable detection systems capable of automatically warning users on social media and on the Internet about the potential untruthfulness of such contents. While algorithms, software, and smartphone apps are getting better every day in generating manipulated videos and swapping faces, the accuracy of automated systems for face forgery detection in videos is still quite limited and generally biased toward the dataset used to design and train a specific detection system. In this paper we analyze how different training strategies and data augmentation techniques affect CNN-based deepfake detectors when training and testing on the same dataset or across different datasets.