 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Jun 05, 2024



With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
Detecting GAN-generated Images by Orthogonal Training of Multiple CNNs
Mar 04, 2022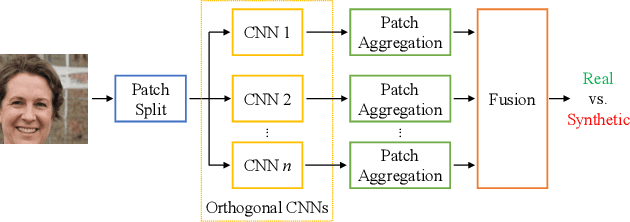
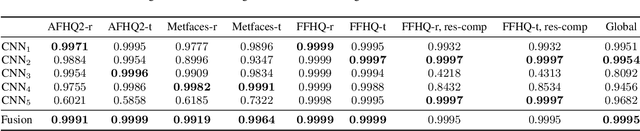
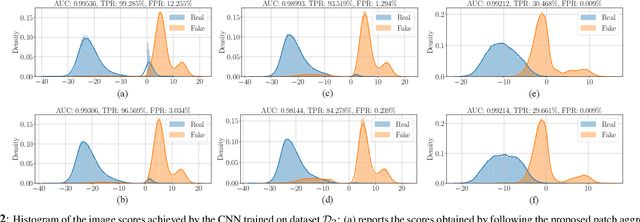
In the last few years, we have witnessed the rise of a series of deep learning methods to generate synthetic images that look extremely realistic. These techniques prove useful in the movie industry and for artistic purposes. However, they also prove dangerous if used to spread fake news or to generate fake online accounts. For this reason, detecting if an image is an actual photograph or has been synthetically generated is becoming an urgent necessity. This paper proposes a detector of synthetic images based on an ensemble of Convolutional Neural Networks (CNNs). We consider the problem of detecting images generated with techniques not available at training time. This is a common scenario, given that new image generators are published more and more frequently. To solve this issue, we leverage two main ideas: (i) CNNs should provide orthogonal results to better contribute to the ensemble; (ii) original images are better defined than synthetic ones, thus they should be better trusted at testing time. Experiments show that pursuing these two ideas improves the detector accuracy on NVIDIA's newly generated StyleGAN3 images, never used in training.
Amplitude SAR Imagery Splicing Localization
Jan 07, 2022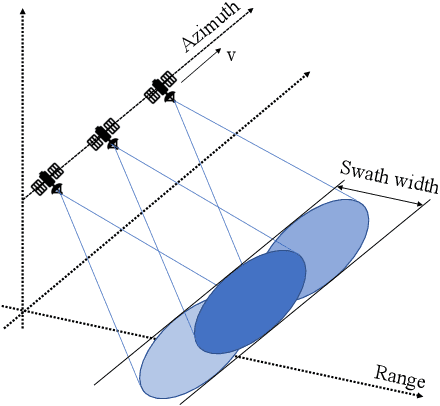



Synthetic Aperture Radar (SAR) images are a valuable asset for a wide variety of tasks. In the last few years, many websites have been offering them for free in the form of easy to manage products, favoring their widespread diffusion and research work in the SAR field. The drawback of these opportunities is that such images might be exposed to forgeries and manipulations by malicious users, raising new concerns about their integrity and trustworthiness. Up to now, the multimedia forensics literature has proposed various techniques to localize manipulations in natural photographs, but the integrity assessment of SAR images was never investigated. This task poses new challenges, since SAR images are generated with a processing chain completely different from that of natural photographs. This implies that many forensics methods developed for natural images are not guaranteed to succeed. In this paper, we investigate the problem of amplitude SAR imagery splicing localization. Our goal is to localize regions of an amplitude SAR image that have been copied and pasted from another image, possibly undergoing some kind of editing in the process. To do so, we leverage a Convolutional Neural Network (CNN) to extract a fingerprint highlighting inconsistencies in the processing traces of the analyzed input. Then, we examine this fingerprint to produce a binary tampering mask indicating the pixel region under splicing attack. Results show that our proposed method, tailored to the nature of SAR signals, provides better performances than state-of-the-art forensic tools developed for natural images.
Training CNNs in Presence of JPEG Compression: Multimedia Forensics vs Computer Vision
Sep 25, 2020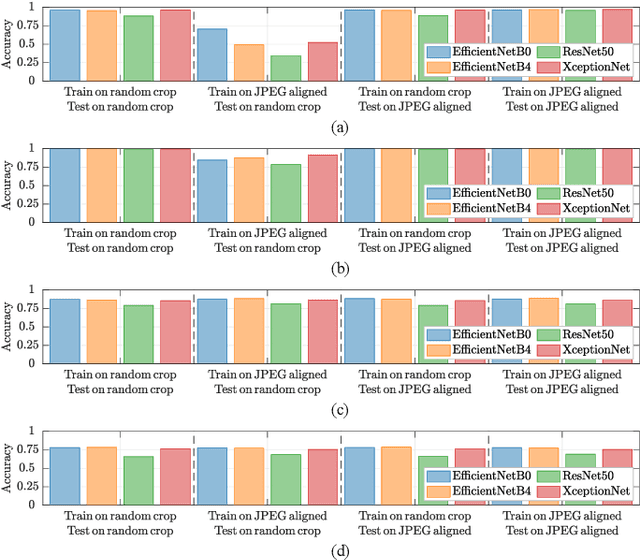
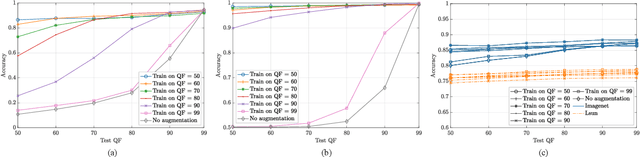
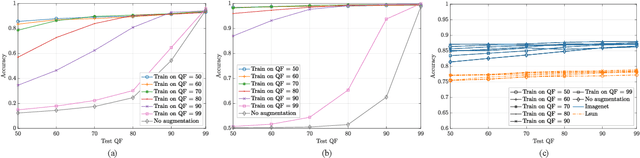
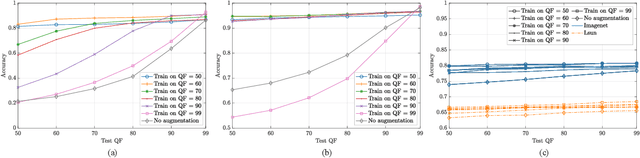
Convolutional Neural Networks (CNNs) have proved very accurate in multiple computer vision image classification tasks that required visual inspection in the past (e.g., object recognition, face detection, etc.). Motivated by these astonishing results, researchers have also started using CNNs to cope with image forensic problems (e.g., camera model identification, tampering detection, etc.). However, in computer vision, image classification methods typically rely on visual cues easily detectable by human eyes. Conversely, forensic solutions rely on almost invisible traces that are often very subtle and lie in the fine details of the image under analysis. For this reason, training a CNN to solve a forensic task requires some special care, as common processing operations (e.g., resampling, compression, etc.) can strongly hinder forensic traces. In this work, we focus on the effect that JPEG has on CNN training considering different computer vision and forensic image classification problems. Specifically, we consider the issues that rise from JPEG compression and misalignment of the JPEG grid. We show that it is necessary to consider these effects when generating a training dataset in order to properly train a forensic detector not losing generalization capability, whereas it is almost possible to ignore these effects for computer vision tasks.
On the use of Benford's law to detect GAN-generated images
Apr 16, 2020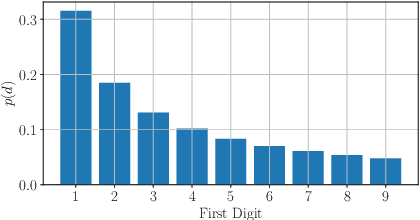
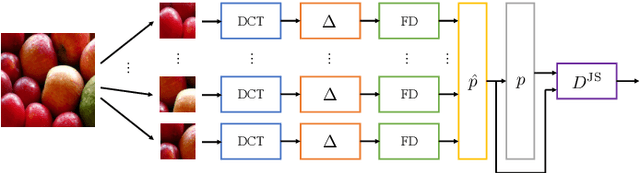
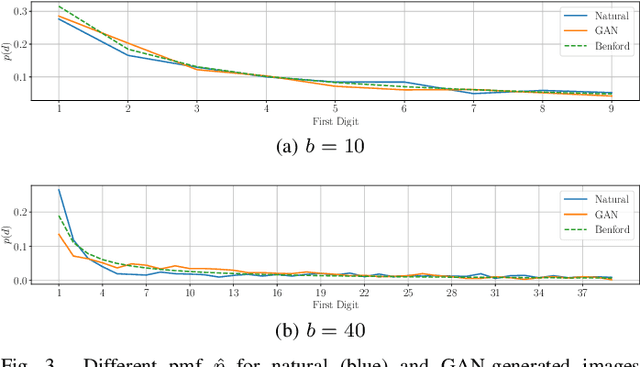

The advent of Generative Adversarial Network (GAN) architectures has given anyone the ability of generating incredibly realistic synthetic imagery. The malicious diffusion of GAN-generated images may lead to serious social and political consequences (e.g., fake news spreading, opinion formation, etc.). It is therefore important to regulate the widespread distribution of synthetic imagery by developing solutions able to detect them. In this paper, we study the possibility of using Benford's law to discriminate GAN-generated images from natural photographs. Benford's law describes the distribution of the most significant digit for quantized Discrete Cosine Transform (DCT) coefficients. Extending and generalizing this property, we show that it is possible to extract a compact feature vector from an image. This feature vector can be fed to an extremely simple classifier for GAN-generated image detection purpose.
Video Face Manipulation Detection Through Ensemble of CNNs
Apr 16, 2020
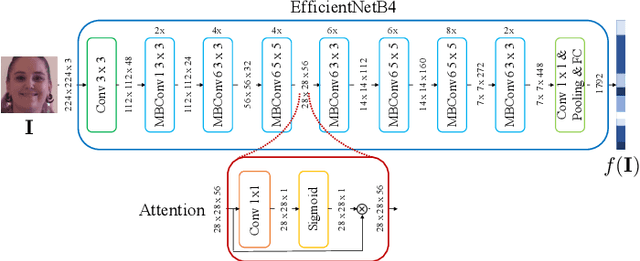

In the last few years, several techniques for facial manipulation in videos have been successfully developed and made available to the masses (i.e., FaceSwap, deepfake, etc.). These methods enable anyone to easily edit faces in video sequences with incredibly realistic results and a very little effort. Despite the usefulness of these tools in many fields, if used maliciously, they can have a significantly bad impact on society (e.g., fake news spreading, cyber bullying through fake revenge porn). The ability of objectively detecting whether a face has been manipulated in a video sequence is then a task of utmost importance. In this paper, we tackle the problem of face manipulation detection in video sequences targeting modern facial manipulation techniques. In particular, we study the ensembling of different trained Convolutional Neural Network (CNN) models. In the proposed solution, different models are obtained starting from a base network (i.e., EfficientNetB4) making use of two different concepts: (i) attention layers; (ii) siamese training. We show that combining these networks leads to promising face manipulation detection results on two publicly available datasets with more than 119000 videos.