 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoeGlass: Simple In-Context Learning Is Enough for Red Teaming Audio Deepfake Detectors
Jun 03, 2026Audio deepfake detection (ADD) models are critical for countering the malicious use of text-to-speech (TTS) models. Evaluating and strengthening ADD models requires developing datasets that span the space of generated audio and highlight high-error regions. Existing dataset development strategies face two challenges: (i) manual collection, and (ii) inefficient discovery of blind spots in the ADD models. To address these challenges, we propose FoeGlass, the first black-box automated red-teaming method for ADDs, which effectively discovers ADD failure modes in the space of generated audio underexplored by state-of-the-art deepfake benchmarks. FoeGlass uses the in-context learning capabilities of an LLM to explore the input space of a TTS model, generating audio samples that fool the target ADD using only black-box access to all components. By using a carefully designed context based on diversity measurements, FoeGlass mitigates the common problem of mode collapse in automated red-teaming systems. Empirical evaluations on several open-source ADD and TTS models demonstrate that data generated from FoeGlass substantially improves the false negative rates over unconditional sampling baselines and recent spoofing datasets by up to 94%, while requiring no manual supervision. Furthermore, we show that the attacks generated by FoeGlass are transferable across different target ADDs, demonstrating its broad applicability and ease of use for the automated red teaming of ADD systems. Finally, fine-tuning ADD models on FoeGlass-generated samples notably enhances the robustness of the detectors (up 41%).
PolyJuice Makes It Real: Black-Box, Universal Red Teaming for Synthetic Image Detectors
Sep 19, 2025Synthetic image detectors (SIDs) are a key defense against the risks posed by the growing realism of images from text-to-image (T2I) models. Red teaming improves SID's effectiveness by identifying and exploiting their failure modes via misclassified synthetic images. However, existing red-teaming solutions (i) require white-box access to SIDs, which is infeasible for proprietary state-of-the-art detectors, and (ii) generate image-specific attacks through expensive online optimization. To address these limitations, we propose PolyJuice, the first black-box, image-agnostic red-teaming method for SIDs, based on an observed distribution shift in the T2I latent space between samples correctly and incorrectly classified by the SID. PolyJuice generates attacks by (i) identifying the direction of this shift through a lightweight offline process that only requires black-box access to the SID, and (ii) exploiting this direction by universally steering all generated images towards the SID's failure modes. PolyJuice-steered T2I models are significantly more effective at deceiving SIDs (up to 84%) compared to their unsteered counterparts. We also show that the steering directions can be estimated efficiently at lower resolutions and transferred to higher resolutions using simple interpolation, reducing computational overhead. Finally, tuning SID models on PolyJuice-augmented datasets notably enhances the performance of the detectors (up to 30%).
X-Edit: Detecting and Localizing Edits in Images Altered by Text-Guided Diffusion Models
May 16, 2025Text-guided diffusion models have significantly advanced image editing, enabling highly realistic and local modifications based on textual prompts. While these developments expand creative possibilities, their malicious use poses substantial challenges for detection of such subtle deepfake edits. To this end, we introduce Explain Edit (X-Edit), a novel method for localizing diffusion-based edits in images. To localize the edits for an image, we invert the image using a pretrained diffusion model, then use these inverted features as input to a segmentation network that explicitly predicts the edited masked regions via channel and spatial attention. Further, we finetune the model using a combined segmentation and relevance loss. The segmentation loss ensures accurate mask prediction by balancing pixel-wise errors and perceptual similarity, while the relevance loss guides the model to focus on low-frequency regions and mitigate high-frequency artifacts, enhancing the localization of subtle edits. To the best of our knowledge, we are the first to address and model the problem of localizing diffusion-based modified regions in images. We additionally contribute a new dataset of paired original and edited images addressing the current lack of resources for this task. Experimental results demonstrate that X-Edit accurately localizes edits in images altered by text-guided diffusion models, outperforming baselines in PSNR and SSIM metrics. This highlights X-Edit's potential as a robust forensic tool for detecting and pinpointing manipulations introduced by advanced image editing techniques.
What Does an Audio Deepfake Detector Focus on? A Study in the Time Domain
Jan 27, 2025



Adding explanations to audio deepfake detection (ADD) models will boost their real-world application by providing insight on the decision making process. In this paper, we propose a relevancy-based explainable AI (XAI) method to analyze the predictions of transformer-based ADD models. We compare against standard Grad-CAM and SHAP-based methods, using quantitative faithfulness metrics as well as a partial spoof test, to comprehensively analyze the relative importance of different temporal regions in an audio. We consider large datasets, unlike previous works where only limited utterances are studied, and find that the XAI methods differ in their explanations. The proposed relevancy-based XAI method performs the best overall on a variety of metrics. Further investigation on the relative importance of speech/non-speech, phonetic content, and voice onsets/offsets suggest that the XAI results obtained from analyzing limited utterances don't necessarily hold when evaluated on large datasets.
Learn from Real: Reality Defender's Submission to ASVspoof5 Challenge
Oct 09, 2024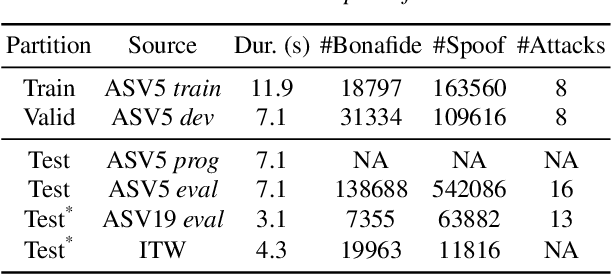
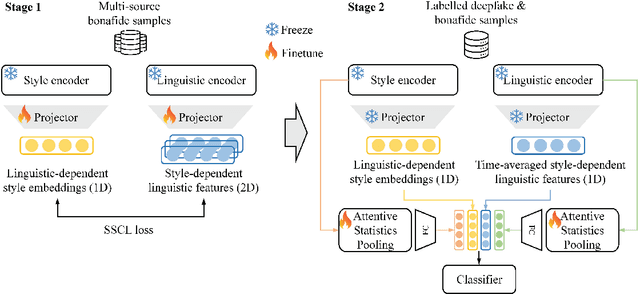
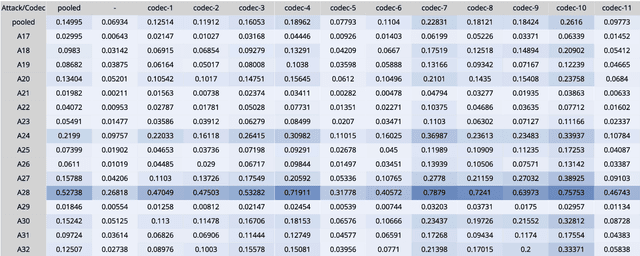
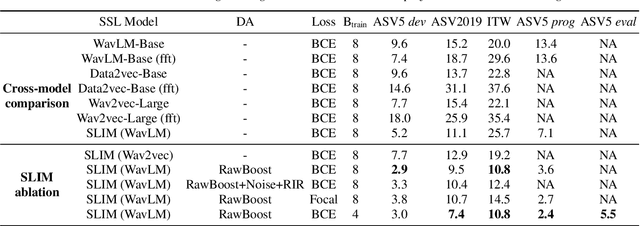
Audio deepfake detection is crucial to combat the malicious use of AI-synthesized speech. Among many efforts undertaken by the community, the ASVspoof challenge has become one of the benchmarks to evaluate the generalizability and robustness of detection models. In this paper, we present Reality Defender's submission to the ASVspoof5 challenge, highlighting a novel pretraining strategy which significantly improves generalizability while maintaining low computational cost during training. Our system SLIM learns the style-linguistics dependency embeddings from various types of bonafide speech using self-supervised contrastive learning. The learned embeddings help to discriminate spoof from bonafide speech by focusing on the relationship between the style and linguistics aspects. We evaluated our system on ASVspoof5, ASV2019, and In-the-wild. Our submission achieved minDCF of 0.1499 and EER of 5.5% on ASVspoof5 Track 1, and EER of 7.4% and 10.8% on ASV2019 and In-the-wild respectively.
Content and Style Aware Audio-Driven Facial Animation
Aug 14, 2024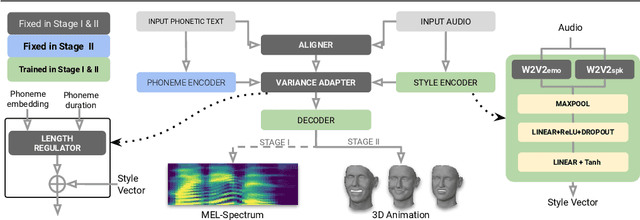
Audio-driven 3D facial animation has several virtual humans applications for content creation and editing. While several existing methods provide solutions for speech-driven animation, precise control over content (what) and style (how) of the final performance is still challenging. We propose a novel approach that takes as input an audio, and the corresponding text to extract temporally-aligned content and disentangled style representations, in order to provide controls over 3D facial animation. Our method is trained in two stages, that evolves from audio prominent styles (how it sounds) to visual prominent styles (how it looks). We leverage a high-resource audio dataset in stage I to learn styles that control speech generation in a self-supervised learning framework, and then fine-tune this model with low-resource audio/3D mesh pairs in stage II to control 3D vertex generation. We employ a non-autoregressive seq2seq formulation to model sentence-level dependencies, and better mouth articulations. Our method provides flexibility that the style of a reference audio and the content of a source audio can be combined to enable audio style transfer. Similarly, the content can be modified, e.g. muting or swapping words, that enables style-preserving content editing.
SLIM: Style-Linguistics Mismatch Model for Generalized Audio Deepfake Detection
Jul 26, 2024
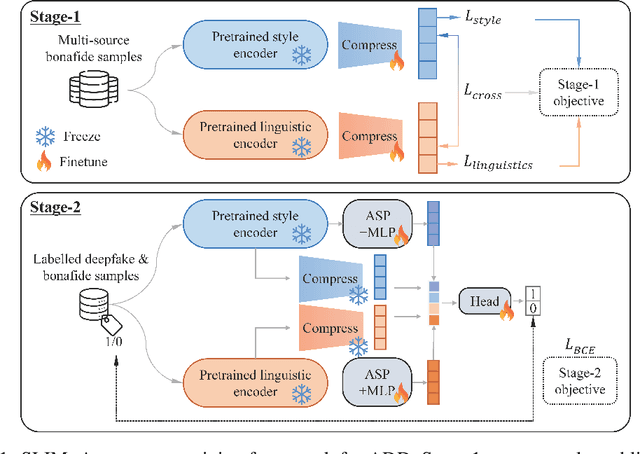
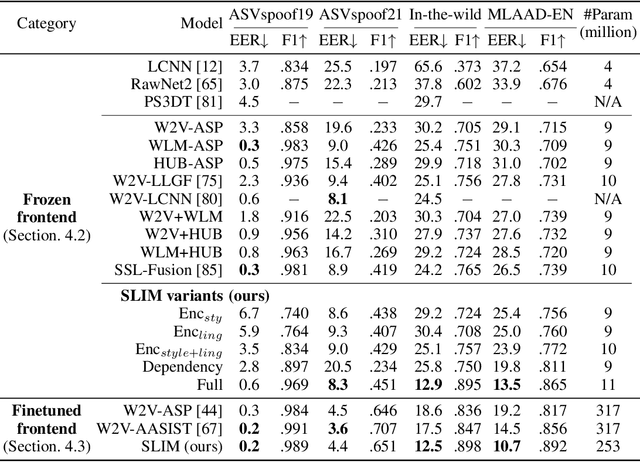
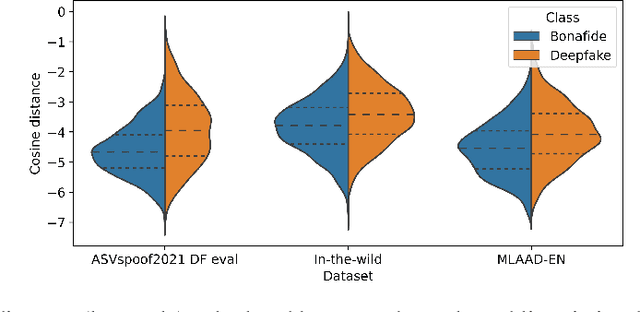
Audio deepfake detection (ADD) is crucial to combat the misuse of speech synthesized from generative AI models. Existing ADD models suffer from generalization issues, with a large performance discrepancy between in-domain and out-of-domain data. Moreover, the black-box nature of existing models limits their use in real-world scenarios, where explanations are required for model decisions. To alleviate these issues, we introduce a new ADD model that explicitly uses the StyleLInguistics Mismatch (SLIM) in fake speech to separate them from real speech. SLIM first employs self-supervised pretraining on only real samples to learn the style-linguistics dependency in the real class. The learned features are then used in complement with standard pretrained acoustic features (e.g., Wav2vec) to learn a classifier on the real and fake classes. When the feature encoders are frozen, SLIM outperforms benchmark methods on out-of-domain datasets while achieving competitive results on in-domain data. The features learned by SLIM allow us to quantify the (mis)match between style and linguistic content in a sample, hence facilitating an explanation of the model decision.
Towards Attention-based Contrastive Learning for Audio Spoof Detection
Jul 03, 2024Vision transformers (ViT) have made substantial progress for classification tasks in computer vision. Recently, Gong et. al. '21, introduced attention-based modeling for several audio tasks. However, relatively unexplored is the use of a ViT for audio spoof detection task. We bridge this gap and introduce ViTs for this task. A vanilla baseline built on fine-tuning the SSAST (Gong et. al. '22) audio ViT model achieves sub-optimal equal error rates (EERs). To improve performance, we propose a novel attention-based contrastive learning framework (SSAST-CL) that uses cross-attention to aid the representation learning. Experiments show that our framework successfully disentangles the bonafide and spoof classes and helps learn better classifiers for the task. With appropriate data augmentations policy, a model trained on our framework achieves competitive performance on the ASVSpoof 2021 challenge. We provide comparisons and ablation studies to justify our claim.
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Jun 05, 2024



With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
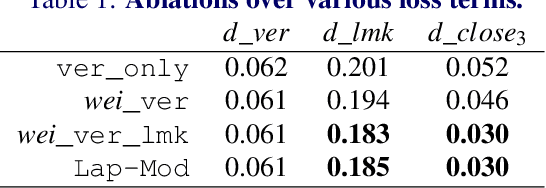
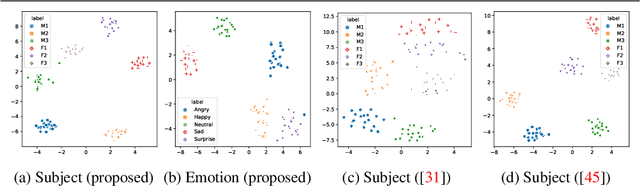
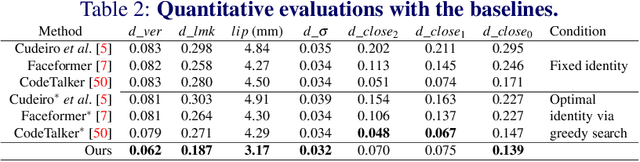
FaceLift: Semi-supervised 3D Facial Landmark Localization
May 30, 2024



3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: https://davidcferman.github.io/FaceLift