 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoSPatS: Video SPatiotemporal Splines for Disentangled Occlusion, Appearance and Motion Modeling and Editing
Apr 08, 2025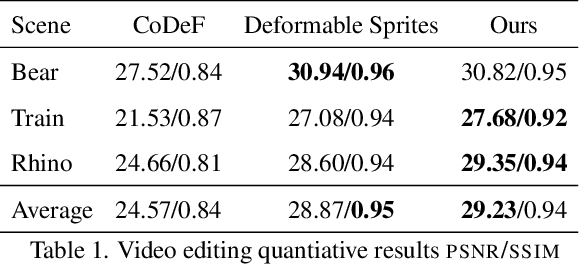
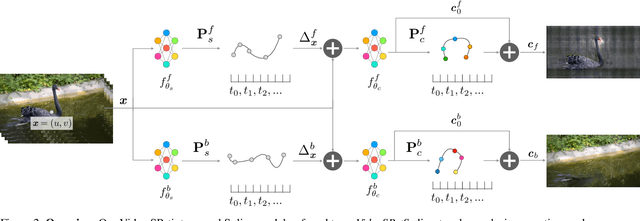
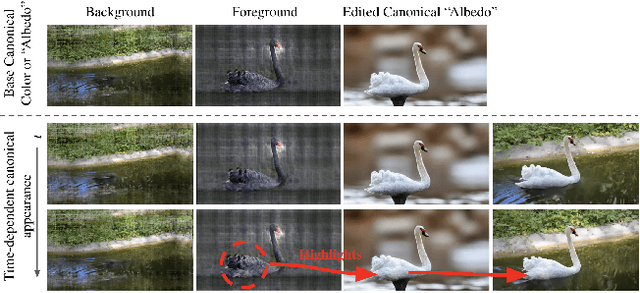

We present an implicit video representation for occlusions, appearance, and motion disentanglement from monocular videos, which we call Video SPatiotemporal Splines (VideoSPatS). Unlike previous methods that map time and coordinates to deformation and canonical colors, our VideoSPatS maps input coordinates into Spatial and Color Spline deformation fields $D_s$ and $D_c$, which disentangle motion and appearance in videos. With spline-based parametrization, our method naturally generates temporally consistent flow and guarantees long-term temporal consistency, which is crucial for convincing video editing. Using multiple prediction branches, our VideoSPatS model also performs layer separation between the latent video and the selected occluder. By disentangling occlusions, appearance, and motion, our method enables better spatiotemporal modeling and editing of diverse videos, including in-the-wild talking head videos with challenging occlusions, shadows, and specularities while maintaining an appropriate canonical space for editing. We also present general video modeling results on the DAVIS and CoDeF datasets, as well as our own talking head video dataset collected from open-source web videos. Extensive ablations show the combination of $D_s$ and $D_c$ under neural splines can overcome motion and appearance ambiguities, paving the way for more advanced video editing models.
Contextual Gesture: Co-Speech Gesture Video Generation through Context-aware Gesture Representation
Feb 11, 2025Co-speech gesture generation is crucial for creating lifelike avatars and enhancing human-computer interactions by synchronizing gestures with speech. Despite recent advancements, existing methods struggle with accurately identifying the rhythmic or semantic triggers from audio for generating contextualized gesture patterns and achieving pixel-level realism. To address these challenges, we introduce Contextual Gesture, a framework that improves co-speech gesture video generation through three innovative components: (1) a chronological speech-gesture alignment that temporally connects two modalities, (2) a contextualized gesture tokenization that incorporate speech context into motion pattern representation through distillation, and (3) a structure-aware refinement module that employs edge connection to link gesture keypoints to improve video generation. Our extensive experiments demonstrate that Contextual Gesture not only produces realistic and speech-aligned gesture videos but also supports long-sequence generation and video gesture editing applications, shown in Fig.1 Project Page: https://andypinxinliu.github.io/Contextual-Gesture/.
KinMo: Kinematic-aware Human Motion Understanding and Generation
Nov 23, 2024



Controlling human motion based on text presents an important challenge in computer vision. Traditional approaches often rely on holistic action descriptions for motion synthesis, which struggle to capture subtle movements of local body parts. This limitation restricts the ability to isolate and manipulate specific movements. To address this, we propose a novel motion representation that decomposes motion into distinct body joint group movements and interactions from a kinematic perspective. We design an automatic dataset collection pipeline that enhances the existing text-motion benchmark by incorporating fine-grained local joint-group motion and interaction descriptions. To bridge the gap between text and motion domains, we introduce a hierarchical motion semantics approach that progressively fuses joint-level interaction information into the global action-level semantics for modality alignment. With this hierarchy, we introduce a coarse-to-fine motion synthesis procedure for various generation and editing downstream applications. Our quantitative and qualitative experiments demonstrate that the proposed formulation enhances text-motion retrieval by improving joint-spatial understanding, and enables more precise joint-motion generation and control. Project Page: {\small\url{https://andypinxinliu.github.io/KinMo/}}
GaussianHeads: End-to-End Learning of Drivable Gaussian Head Avatars from Coarse-to-fine Representations
Sep 18, 2024Real-time rendering of human head avatars is a cornerstone of many computer graphics applications, such as augmented reality, video games, and films, to name a few. Recent approaches address this challenge with computationally efficient geometry primitives in a carefully calibrated multi-view setup. Albeit producing photorealistic head renderings, it often fails to represent complex motion changes such as the mouth interior and strongly varying head poses. We propose a new method to generate highly dynamic and deformable human head avatars from multi-view imagery in real-time. At the core of our method is a hierarchical representation of head models that allows to capture the complex dynamics of facial expressions and head movements. First, with rich facial features extracted from raw input frames, we learn to deform the coarse facial geometry of the template mesh. We then initialize 3D Gaussians on the deformed surface and refine their positions in a fine step. We train this coarse-to-fine facial avatar model along with the head pose as a learnable parameter in an end-to-end framework. This enables not only controllable facial animation via video inputs, but also high-fidelity novel view synthesis of challenging facial expressions, such as tongue deformations and fine-grained teeth structure under large motion changes. Moreover, it encourages the learned head avatar to generalize towards new facial expressions and head poses at inference time. We demonstrate the performance of our method with comparisons against the related methods on different datasets, spanning challenging facial expression sequences across multiple identities. We also show the potential application of our approach by demonstrating a cross-identity facial performance transfer application.
VideoClusterNet: Self-Supervised and Adaptive Clustering For Videos
Jul 16, 2024With the rise of digital media content production, the need for analyzing movies and TV series episodes to locate the main cast of characters precisely is gaining importance.Specifically, Video Face Clustering aims to group together detected video face tracks with common facial identities. This problem is very challenging due to the large range of pose, expression, appearance, and lighting variations of a given face across video frames. Generic pre-trained Face Identification (ID) models fail to adapt well to the video production domain, given its high dynamic range content and also unique cinematic style. Furthermore, traditional clustering algorithms depend on hyperparameters requiring individual tuning across datasets. In this paper, we present a novel video face clustering approach that learns to adapt a generic face ID model to new video face tracks in a fully self-supervised fashion. We also propose a parameter-free clustering algorithm that is capable of automatically adapting to the finetuned model's embedding space for any input video. Due to the lack of comprehensive movie face clustering benchmarks, we also present a first-of-kind movie dataset: MovieFaceCluster. Our dataset is handpicked by film industry professionals and contains extremely challenging face ID scenarios. Experiments show our method's effectiveness in handling difficult mainstream movie scenes on our benchmark dataset and state-of-the-art performance on traditional TV series datasets.
FaceLift: Semi-supervised 3D Facial Landmark Localization
May 30, 2024



3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: https://davidcferman.github.io/FaceLift
Implicit Neural Head Synthesis via Controllable Local Deformation Fields
Apr 21, 2023High-quality reconstruction of controllable 3D head avatars from 2D videos is highly desirable for virtual human applications in movies, games, and telepresence. Neural implicit fields provide a powerful representation to model 3D head avatars with personalized shape, expressions, and facial parts, e.g., hair and mouth interior, that go beyond the linear 3D morphable model (3DMM). However, existing methods do not model faces with fine-scale facial features, or local control of facial parts that extrapolate asymmetric expressions from monocular videos. Further, most condition only on 3DMM parameters with poor(er) locality, and resolve local features with a global neural field. We build on part-based implicit shape models that decompose a global deformation field into local ones. Our novel formulation models multiple implicit deformation fields with local semantic rig-like control via 3DMM-based parameters, and representative facial landmarks. Further, we propose a local control loss and attention mask mechanism that promote sparsity of each learned deformation field. Our formulation renders sharper locally controllable nonlinear deformations than previous implicit monocular approaches, especially mouth interior, asymmetric expressions, and facial details.
Few-shot Geometry-Aware Keypoint Localization
Mar 30, 2023



Supervised keypoint localization methods rely on large manually labeled image datasets, where objects can deform, articulate, or occlude. However, creating such large keypoint labels is time-consuming and costly, and is often error-prone due to inconsistent labeling. Thus, we desire an approach that can learn keypoint localization with fewer yet consistently annotated images. To this end, we present a novel formulation that learns to localize semantically consistent keypoint definitions, even for occluded regions, for varying object categories. We use a few user-labeled 2D images as input examples, which are extended via self-supervision using a larger unlabeled dataset. Unlike unsupervised methods, the few-shot images act as semantic shape constraints for object localization. Furthermore, we introduce 3D geometry-aware constraints to uplift keypoints, achieving more accurate 2D localization. Our general-purpose formulation paves the way for semantically conditioned generative modeling and attains competitive or state-of-the-art accuracy on several datasets, including human faces, eyes, animals, cars, and never-before-seen mouth interior (teeth) localization tasks, not attempted by the previous few-shot methods. Project page: https://xingzhehe.github.io/FewShot3DKP/}{https://xingzhehe.github.io/FewShot3DKP/
* CVPR 2023
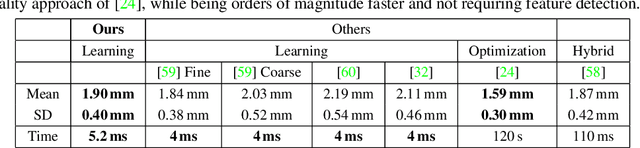
HQ3DAvatar: High Quality Controllable 3D Head Avatar
Mar 25, 2023Multi-view volumetric rendering techniques have recently shown great potential in modeling and synthesizing high-quality head avatars. A common approach to capture full head dynamic performances is to track the underlying geometry using a mesh-based template or 3D cube-based graphics primitives. While these model-based approaches achieve promising results, they often fail to learn complex geometric details such as the mouth interior, hair, and topological changes over time. This paper presents a novel approach to building highly photorealistic digital head avatars. Our method learns a canonical space via an implicit function parameterized by a neural network. It leverages multiresolution hash encoding in the learned feature space, allowing for high-quality, faster training and high-resolution rendering. At test time, our method is driven by a monocular RGB video. Here, an image encoder extracts face-specific features that also condition the learnable canonical space. This encourages deformation-dependent texture variations during training. We also propose a novel optical flow based loss that ensures correspondences in the learned canonical space, thus encouraging artifact-free and temporally consistent renderings. We show results on challenging facial expressions and show free-viewpoint renderings at interactive real-time rates for medium image resolutions. Our method outperforms all existing approaches, both visually and numerically. We will release our multiple-identity dataset to encourage further research. Our Project page is available at: https://vcai.mpi-inf.mpg.de/projects/HQ3DAvatar/
FML: Face Model Learning from Videos
Dec 18, 2018
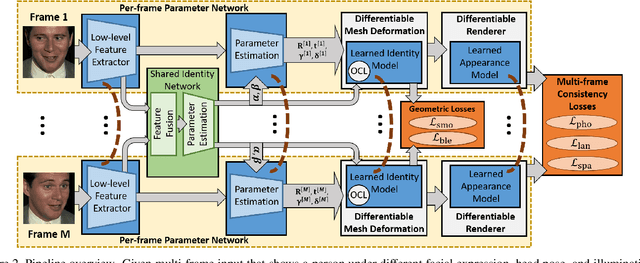
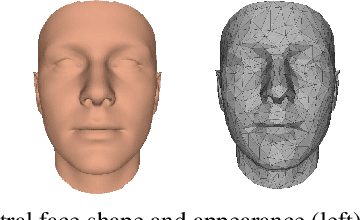
Monocular image-based 3D reconstruction of faces is a long-standing problem in computer vision. Since image data is a 2D projection of a 3D face, the resulting depth ambiguity makes the problem ill-posed. Most existing methods rely on data-driven priors that are built from limited 3D face scans. In contrast, we propose multi-frame video-based self-supervised training of a deep network that (i) learns a face identity model both in shape and appearance while (ii) jointly learning to reconstruct 3D faces. Our face model is learned using only corpora of in-the-wild video clips collected from the Internet. This virtually endless source of training data enables learning of a highly general 3D face model. In order to achieve this, we propose a novel multi-frame consistency loss that ensures consistent shape and appearance across multiple frames of a subject's face, thus minimizing depth ambiguity. At test time we can use an arbitrary number of frames, so that we can perform both monocular as well as multi-frame reconstruction.