 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoClusterNet: Self-Supervised and Adaptive Clustering For Videos
Jul 16, 2024With the rise of digital media content production, the need for analyzing movies and TV series episodes to locate the main cast of characters precisely is gaining importance.Specifically, Video Face Clustering aims to group together detected video face tracks with common facial identities. This problem is very challenging due to the large range of pose, expression, appearance, and lighting variations of a given face across video frames. Generic pre-trained Face Identification (ID) models fail to adapt well to the video production domain, given its high dynamic range content and also unique cinematic style. Furthermore, traditional clustering algorithms depend on hyperparameters requiring individual tuning across datasets. In this paper, we present a novel video face clustering approach that learns to adapt a generic face ID model to new video face tracks in a fully self-supervised fashion. We also propose a parameter-free clustering algorithm that is capable of automatically adapting to the finetuned model's embedding space for any input video. Due to the lack of comprehensive movie face clustering benchmarks, we also present a first-of-kind movie dataset: MovieFaceCluster. Our dataset is handpicked by film industry professionals and contains extremely challenging face ID scenarios. Experiments show our method's effectiveness in handling difficult mainstream movie scenes on our benchmark dataset and state-of-the-art performance on traditional TV series datasets.
Online Ensemble Model Compression using Knowledge Distillation
Nov 15, 2020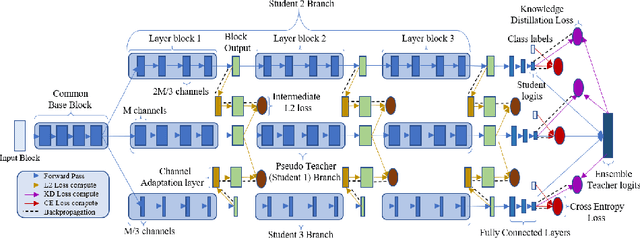
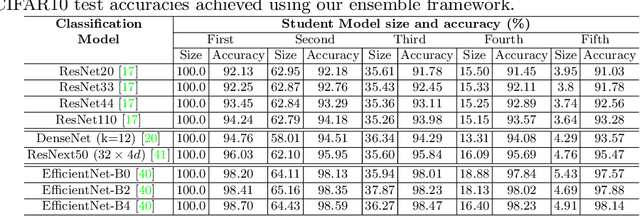
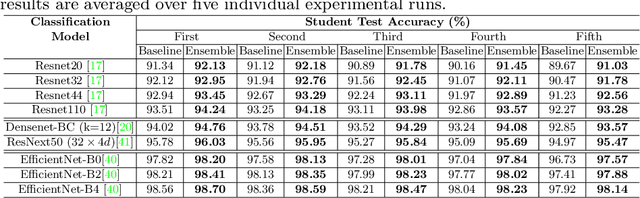

This paper presents a novel knowledge distillation based model compression framework consisting of a student ensemble. It enables distillation of simultaneously learnt ensemble knowledge onto each of the compressed student models. Each model learns unique representations from the data distribution due to its distinct architecture. This helps the ensemble generalize better by combining every model's knowledge. The distilled students and ensemble teacher are trained simultaneously without requiring any pretrained weights. Moreover, our proposed method can deliver multi-compressed students with single training, which is efficient and flexible for different scenarios. We provide comprehensive experiments using state-of-the-art classification models to validate our framework's effectiveness. Notably, using our framework a 97% compressed ResNet110 student model managed to produce a 10.64% relative accuracy gain over its individual baseline training on CIFAR100 dataset. Similarly a 95% compressed DenseNet-BC(k=12) model managed a 8.17% relative accuracy gain.
Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification
Apr 05, 2020
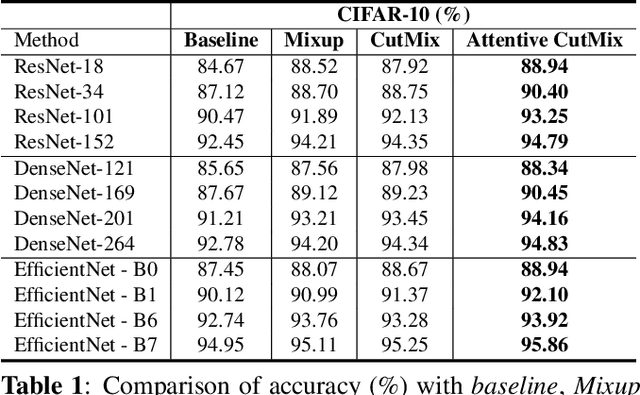
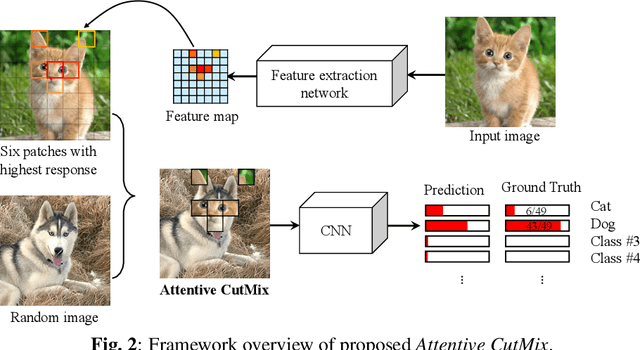
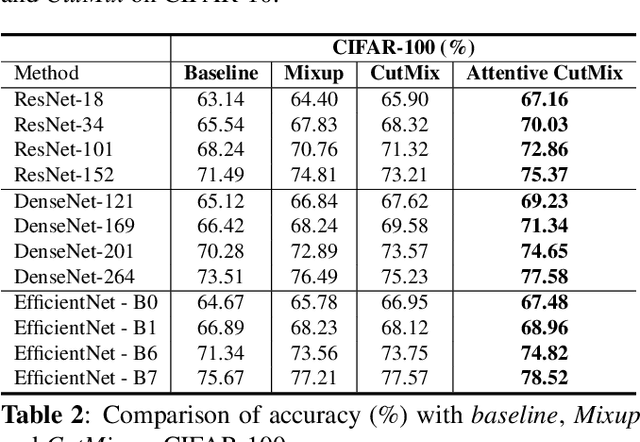
Convolutional neural networks (CNN) are capable of learning robust representation with different regularization methods and activations as convolutional layers are spatially correlated. Based on this property, a large variety of regional dropout strategies have been proposed, such as Cutout, DropBlock, CutMix, etc. These methods aim to promote the network to generalize better by partially occluding the discriminative parts of objects. However, all of them perform this operation randomly, without capturing the most important region(s) within an object. In this paper, we propose Attentive CutMix, a naturally enhanced augmentation strategy based on CutMix. In each training iteration, we choose the most descriptive regions based on the intermediate attention maps from a feature extractor, which enables searching for the most discriminative parts in an image. Our proposed method is simple yet effective, easy to implement and can boost the baseline significantly. Extensive experiments on CIFAR-10/100, ImageNet datasets with various CNN architectures (in a unified setting) demonstrate the effectiveness of our proposed method, which consistently outperforms the baseline CutMix and other methods by a significant margin.
O-MedAL: Online Active Deep Learning for Medical Image Analysis
Aug 28, 2019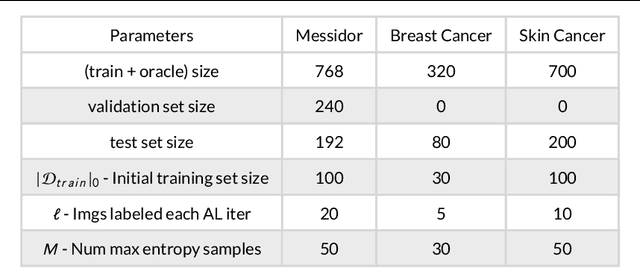
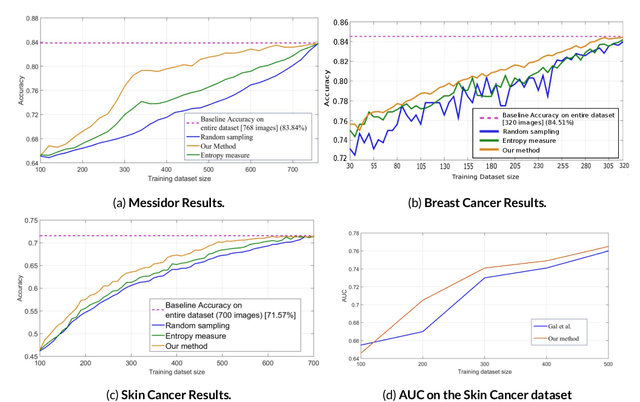
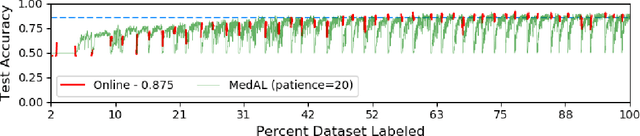
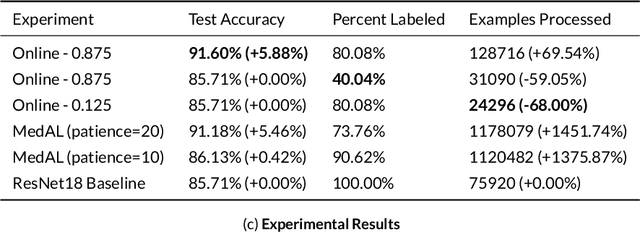
Active Learning methods create an optimized and labeled training set from unlabeled data. We introduce a novel Online Active Deep Learning method for Medical Image Analysis. We extend our MedAL active learning framework to present new results in this paper. Experiments on three medical image datasets show that our novel online active learning model requires significantly less labelings, is more accurate, and is more robust to class imbalances than existing methods. Our method is also more accurate and computationally efficient than the baseline model. Compared to random sampling and uncertainty sampling, the method uses 275 and 200 (out of 768) fewer labeled examples, respectively. For Diabetic Retinopathy detection, our method attains a 5.88% accuracy improvement over the baseline model when 80% of the dataset is labeled, and the model reaches baseline accuracy when only 40% is labeled.
An Empirical Analysis of Deep Audio-Visual Models for Speech Recognition
Dec 21, 2018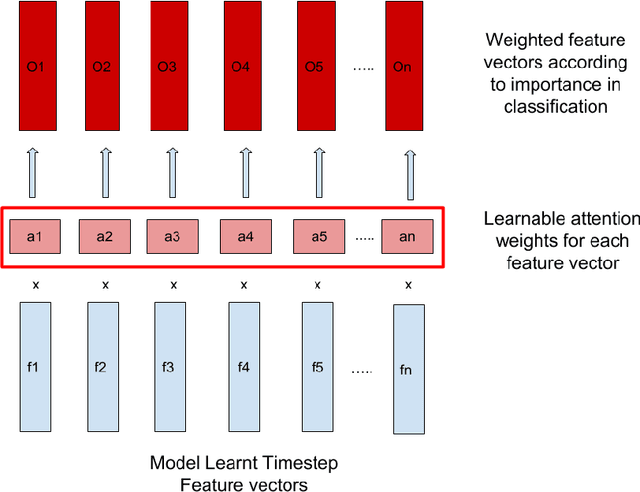

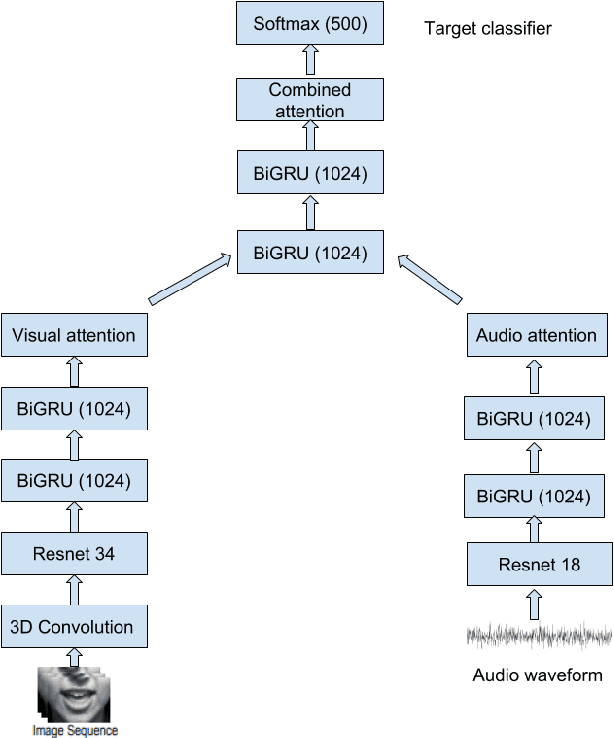
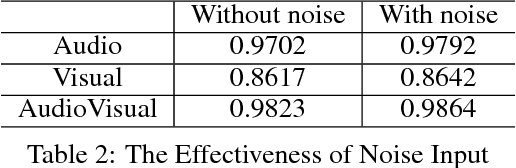
In this project, we worked on speech recognition, specifically predicting individual words based on both the video frames and audio. Empowered by convolutional neural networks, the recent speech recognition and lip reading models are comparable to human level performance. We re-implemented and made derivations of the state-of-the-art model. Then, we conducted rich experiments including the effectiveness of attention mechanism, more accurate residual network as the backbone with pre-trained weights and the sensitivity of our model with respect to audio input with/without noise.
MedAL: Deep Active Learning Sampling Method for Medical Image Analysis
Sep 28, 2018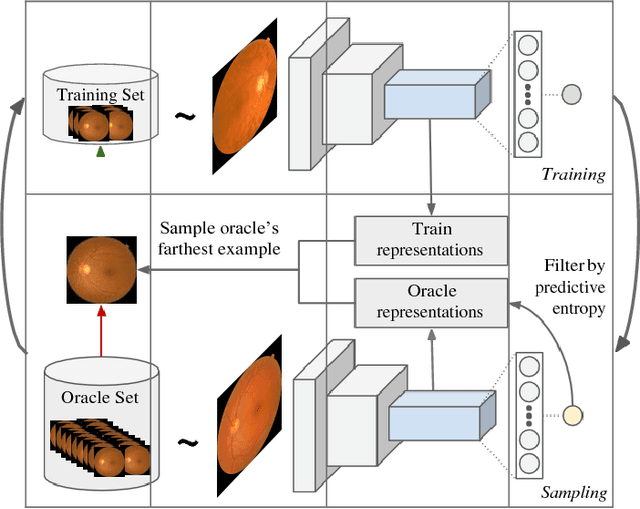
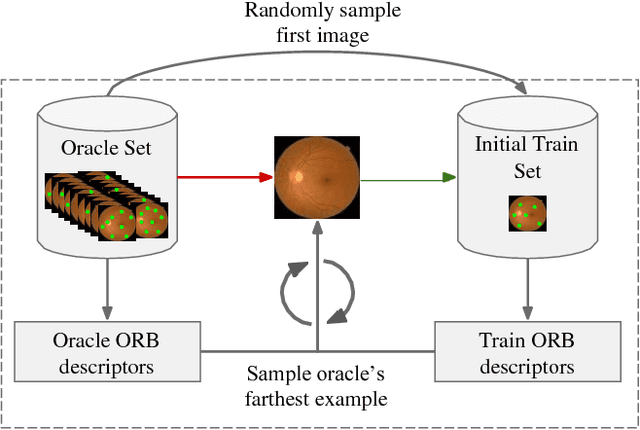
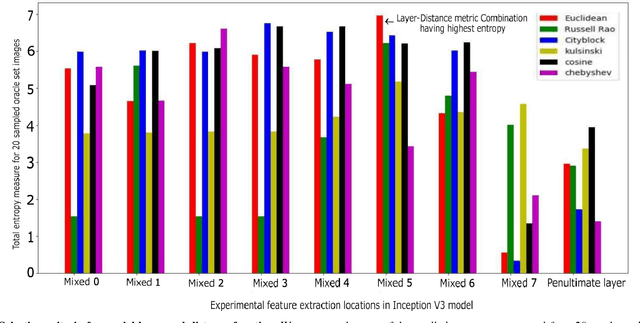
Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance.Deep learning models have been successfully used in medical image analysis problems but they require a large amount of labeled images to obtain good performance. However, such large labeled datasets are costly to acquire. Active learning techniques can be used to minimize the number of required training labels while maximizing the model's performance.In this work, we propose a novel sampling method that queries the unlabeled examples that maximize the average distance to all training set examples in a learned feature space. We then extend our sampling method to define a better initial training set, without the need for a trained model, by using ORB feature descriptors. We validate MedAL on 3 medical image datasets and show that our method is robust to different dataset properties. MedAL is also efficient, achieving 80% accuracy on the task of Diabetic Retinopathy detection using only 425 labeled images, corresponding to a 32% reduction in the number of required labeled examples compared to the standard uncertainty sampling technique, and a 40% reduction compared to random sampling.
A fully automated framework for lung tumour detection, segmentation and analysis
Jan 04, 2018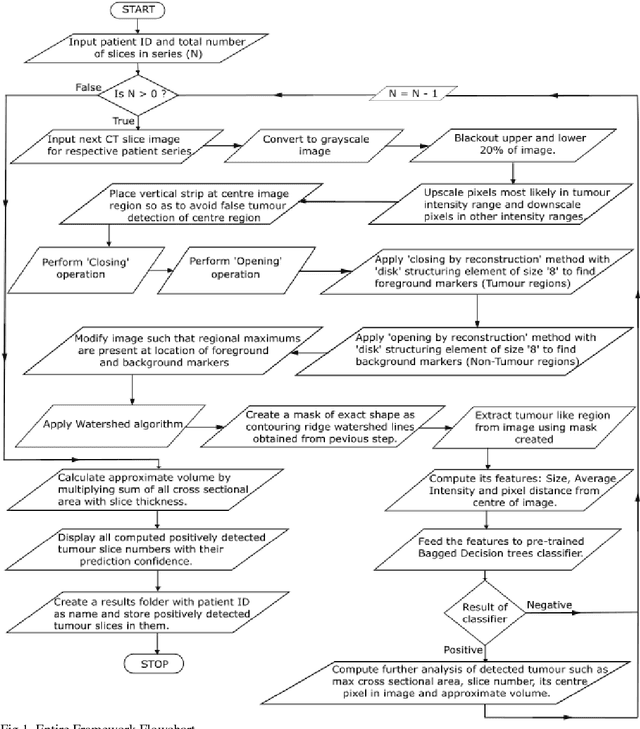
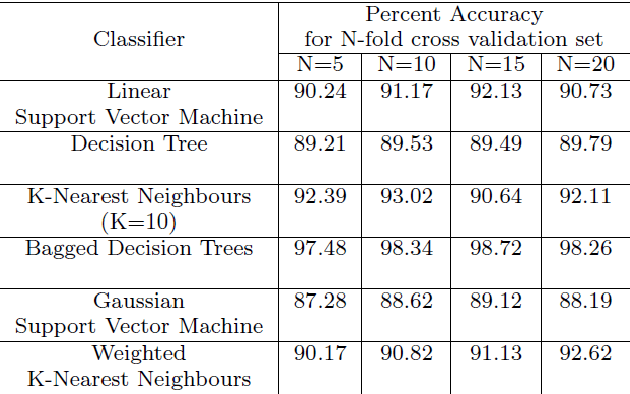
Early and correct diagnosis is a very important aspect of cancer treatment. Detection of tumour in Computed Tomography scan is a tedious and tricky task which requires expert knowledge and a lot of human working hours. As small human error is present in any work he does, it is possible that a CT scan could be misdiagnosed causing the patient to become terminal. This paper introduces a novel fully automated framework which helps to detect and segment tumour, if present in a lung CT scan series. It also provides useful analysis of the detected tumour such as its approximate volume, centre location and more. The framework provides a single click solution which analyses all CT images of a single patient series in one go. It helps to reduce the work of manually going through each CT slice and provides quicker and more accurate tumour diagnosis. It makes use of customized image processing and image segmentation methods, to detect and segment the prospective tumour region from the CT scan. It then uses a trained ensemble classifier to correctly classify the segmented region as being tumour or not. Tumour analysis further computed can then be used to determine malignity of the tumour. With an accuracy of 98.14%, the implemented framework can be used in various practical scenarios, capable of eliminating need of any expert pathologist intervention.
Grammatical facial expression recognition using customized deep neural network architecture
Nov 16, 2017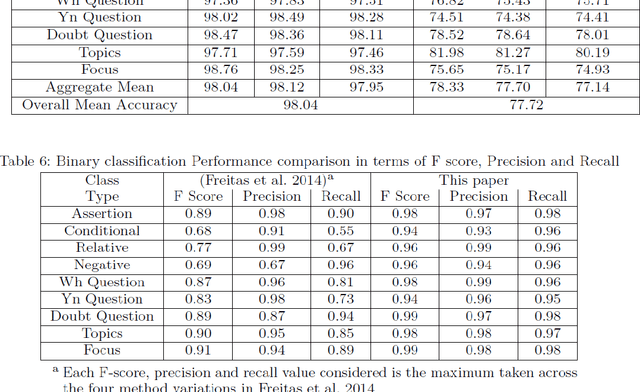
This paper proposes to expand the visual understanding capacity of computers by helping it recognize human sign language more efficiently. This is carried out through recognition of facial expressions, which accompany the hand signs used in this language. This paper specially focuses on the popular Brazilian sign language (LIBRAS). While classifying different hand signs into their respective word meanings has already seen much literature dedicated to it, the emotions or intention with which the words are expressed haven't primarily been taken into consideration. As from our normal human experience, words expressed with different emotions or mood can have completely different meanings attached to it. Lending computers the ability of classifying these facial expressions, can help add another level of deep understanding of what the deaf person exactly wants to communicate. The proposed idea is implemented through a deep neural network having a customized architecture. This helps learning specific patterns in individual expressions much better as compared to a generic approach. With an overall accuracy of 98.04%, the implemented deep network performs excellently well and thus is fit to be used in any given practical scenario.