 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
Jun 08, 2021

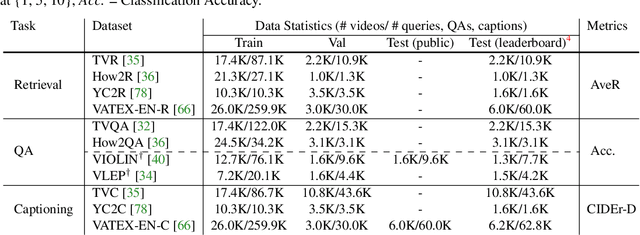
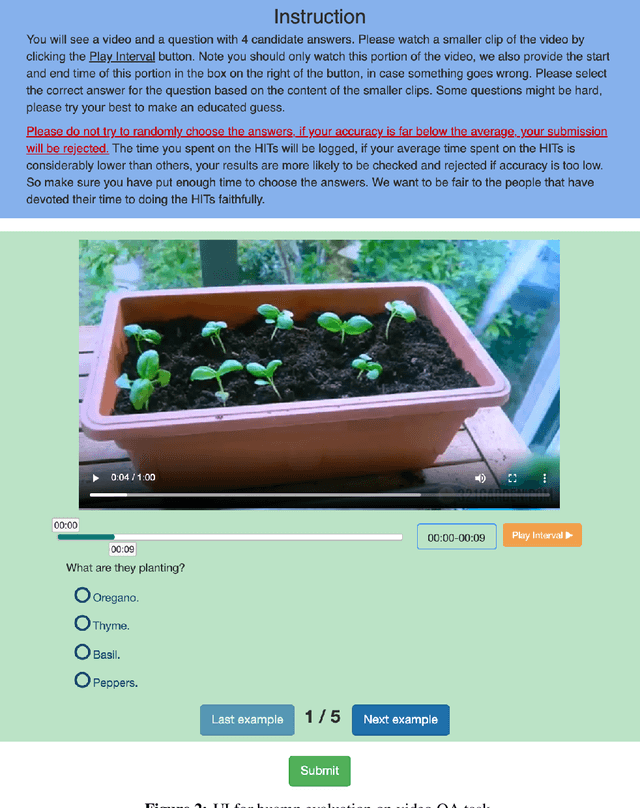
Most existing video-and-language (VidL) research focuses on a single dataset, or multiple datasets of a single task. In reality, a truly useful VidL system is expected to be easily generalizable to diverse tasks, domains, and datasets. To facilitate the evaluation of such systems, we introduce Video-And-Language Understanding Evaluation (VALUE) benchmark, an assemblage of 11 VidL datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks. We evaluate various baseline methods with and without large-scale VidL pre-training, and systematically investigate the impact of video input channels, fusion methods, and different video representations. We also study the transferability between tasks, and conduct multi-task learning under different settings. The significant gap between our best model and human performance calls for future study for advanced VidL models. VALUE is available at https://value-leaderboard.github.io/.
Hierarchical Graph Network for Multi-hop Question Answering
Nov 09, 2019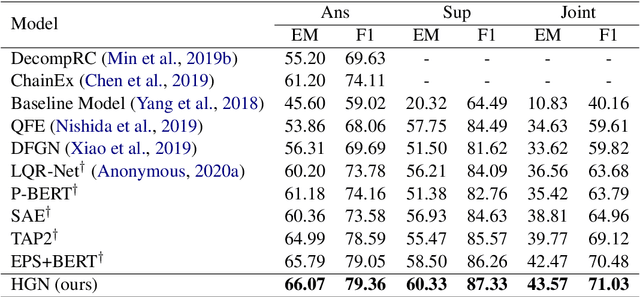
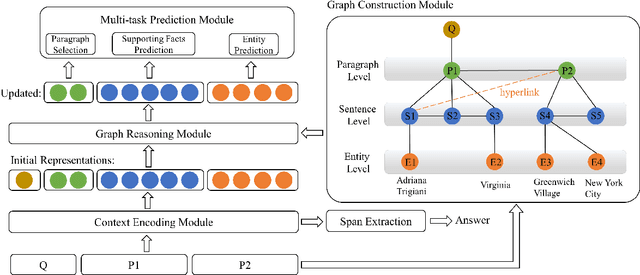
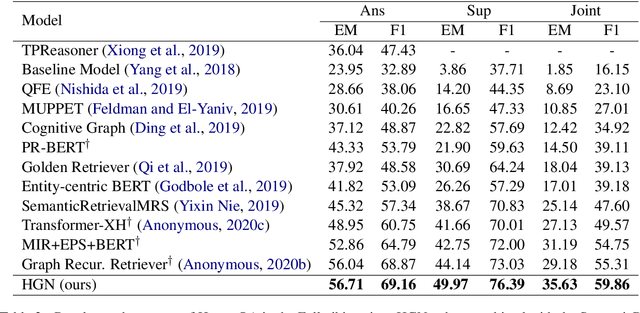
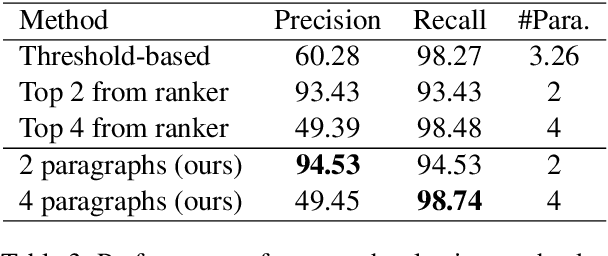
In this paper, we present Hierarchical Graph Network (HGN) for multi-hop question answering. To aggregate clues from scattered texts across multiple paragraphs, a hierarchical graph is created by constructing nodes from different levels of granularity (i.e., questions, paragraphs, sentences, and entities), the representations of which are initialized with BERT-based context encoders. By weaving heterogeneous nodes in an integral unified graph, this characteristic hierarchical differentiation of node granularity enables HGN to support different question answering sub-tasks simultaneously (e.g., paragraph selection, supporting facts extraction, and answer prediction). Given a constructed hierarchical graph for each question, the initial node representations are updated through graph propagation; and for each sub-task, multi-hop reasoning is performed by traversing through graph edges. Extensive experiments on the HotpotQA benchmark demonstrate that the proposed HGN approach significantly outperforms prior state-of-the-art methods by a large margin in both Distractor and Fullwiki settings.
An Empirical Analysis of Deep Audio-Visual Models for Speech Recognition
Dec 21, 2018

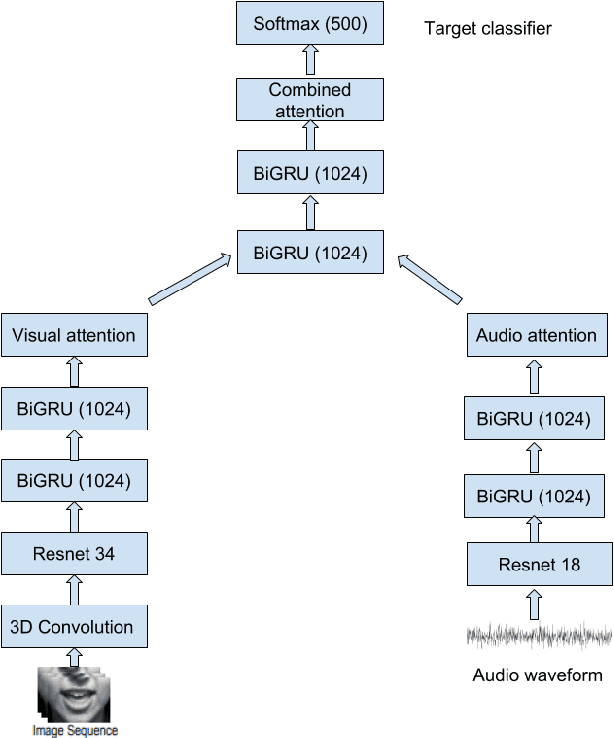
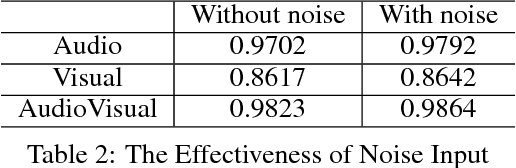
In this project, we worked on speech recognition, specifically predicting individual words based on both the video frames and audio. Empowered by convolutional neural networks, the recent speech recognition and lip reading models are comparable to human level performance. We re-implemented and made derivations of the state-of-the-art model. Then, we conducted rich experiments including the effectiveness of attention mechanism, more accurate residual network as the backbone with pre-trained weights and the sensitivity of our model with respect to audio input with/without noise.