 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Feb 27, 2026GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, large language models (LLMs) remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100\%, 100\%, and 92\% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40\% on the hardest Level-3 setting.
Fake-HR1: Rethinking Reasoning of Vision Language Model for Synthetic Image Detection
Feb 11, 2026Recent studies have demonstrated that incorporating Chain-of-Thought (CoT) reasoning into the detection process can enhance a model's ability to detect synthetic images. However, excessively lengthy reasoning incurs substantial resource overhead, including token consumption and latency, which is particularly redundant when handling obviously generated forgeries. To address this issue, we propose Fake-HR1, a large-scale hybrid-reasoning model that, to the best of our knowledge, is the first to adaptively determine whether reasoning is necessary based on the characteristics of the generative detection task. To achieve this, we design a two-stage training framework: we first perform Hybrid Fine-Tuning (HFT) for cold-start initialization, followed by online reinforcement learning with Hybrid-Reasoning Grouped Policy Optimization (HGRPO) to implicitly learn when to select an appropriate reasoning mode. Experimental results show that Fake-HR1 adaptively performs reasoning across different types of queries, surpassing existing LLMs in both reasoning ability and generative detection performance, while significantly improving response efficiency.
Dichotomous Diffusion Policy Optimization
Dec 31, 2025Diffusion-based policies have gained growing popularity in solving a wide range of decision-making tasks due to their superior expressiveness and controllable generation during inference. However, effectively training large diffusion policies using reinforcement learning (RL) remains challenging. Existing methods either suffer from unstable training due to directly maximizing value objectives, or face computational issues due to relying on crude Gaussian likelihood approximation, which requires a large amount of sufficiently small denoising steps. In this work, we propose DIPOLE (Dichotomous diffusion Policy improvement), a novel RL algorithm designed for stable and controllable diffusion policy optimization. We begin by revisiting the KL-regularized objective in RL, which offers a desirable weighted regression objective for diffusion policy extraction, but often struggles to balance greediness and stability. We then formulate a greedified policy regularization scheme, which naturally enables decomposing the optimal policy into a pair of stably learned dichotomous policies: one aims at reward maximization, and the other focuses on reward minimization. Under such a design, optimized actions can be generated by linearly combining the scores of dichotomous policies during inference, thereby enabling flexible control over the level of greediness.Evaluations in offline and offline-to-online RL settings on ExORL and OGBench demonstrate the effectiveness of our approach. We also use DIPOLE to train a large vision-language-action (VLA) model for end-to-end autonomous driving (AD) and evaluate it on the large-scale real-world AD benchmark NAVSIM, highlighting its potential for complex real-world applications.
Skeleton-Snippet Contrastive Learning with Multiscale Feature Fusion for Action Localization
Dec 22, 2025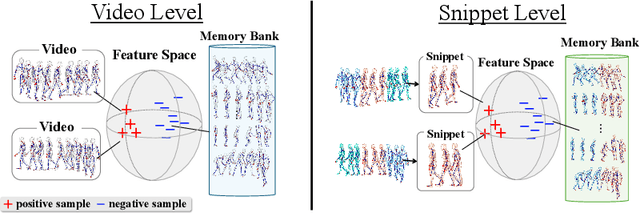
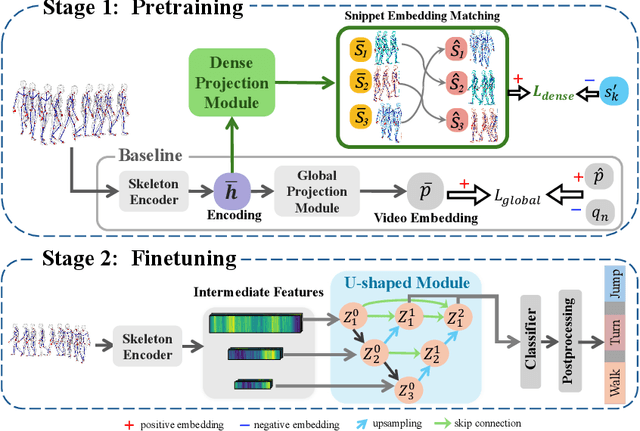
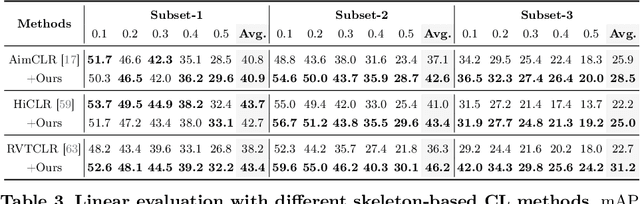
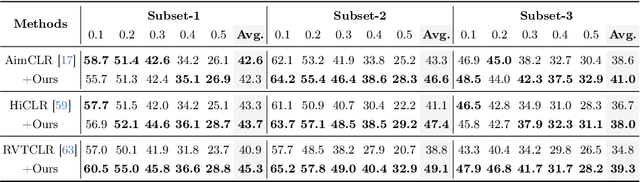
The self-supervised pretraining paradigm has achieved great success in learning 3D action representations for skeleton-based action recognition using contrastive learning. However, learning effective representations for skeleton-based temporal action localization remains challenging and underexplored. Unlike video-level {action} recognition, detecting action boundaries requires temporally sensitive features that capture subtle differences between adjacent frames where labels change. To this end, we formulate a snippet discrimination pretext task for self-supervised pretraining, which densely projects skeleton sequences into non-overlapping segments and promotes features that distinguish them across videos via contrastive learning. Additionally, we build on strong backbones of skeleton-based action recognition models by fusing intermediate features with a U-shaped module to enhance feature resolution for frame-level localization. Our approach consistently improves existing skeleton-based contrastive learning methods for action localization on BABEL across diverse subsets and evaluation protocols. We also achieve state-of-the-art transfer learning performance on PKUMMD with pretraining on NTU RGB+D and BABEL.
TCM-Eval: An Expert-Level Dynamic and Extensible Benchmark for Traditional Chinese Medicine
Nov 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in modern medicine, yet their application in Traditional Chinese Medicine (TCM) remains severely limited by the absence of standardized benchmarks and the scarcity of high-quality training data. To address these challenges, we introduce TCM-Eval, the first dynamic and extensible benchmark for TCM, meticulously curated from national medical licensing examinations and validated by TCM experts. Furthermore, we construct a large-scale training corpus and propose Self-Iterative Chain-of-Thought Enhancement (SI-CoTE) to autonomously enrich question-answer pairs with validated reasoning chains through rejection sampling, establishing a virtuous cycle of data and model co-evolution. Using this enriched training data, we develop ZhiMingTang (ZMT), a state-of-the-art LLM specifically designed for TCM, which significantly exceeds the passing threshold for human practitioners. To encourage future research and development, we release a public leaderboard, fostering community engagement and continuous improvement.
Learn More, Forget Less: A Gradient-Aware Data Selection Approach for LLM
Nov 07, 2025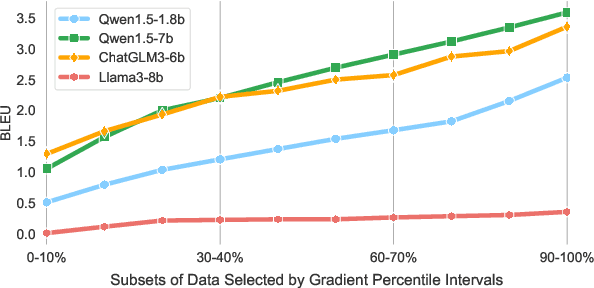
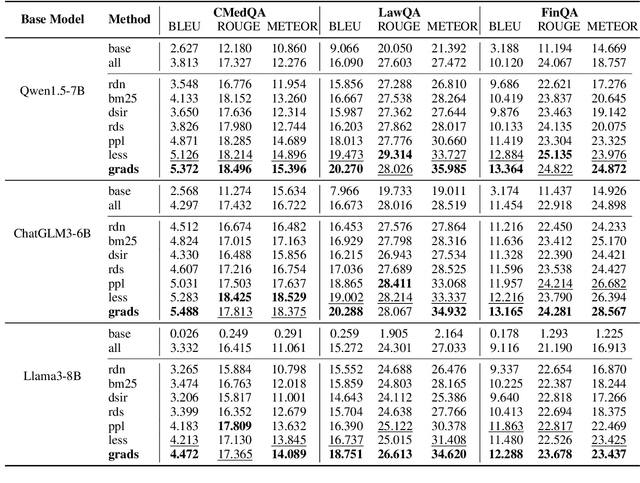
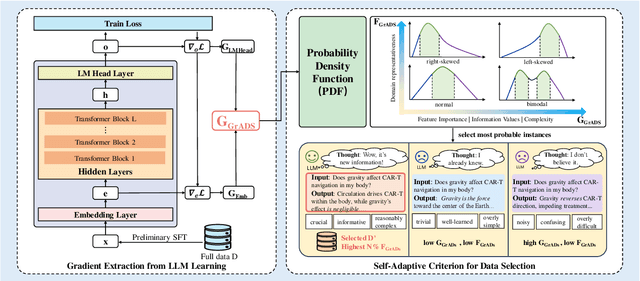
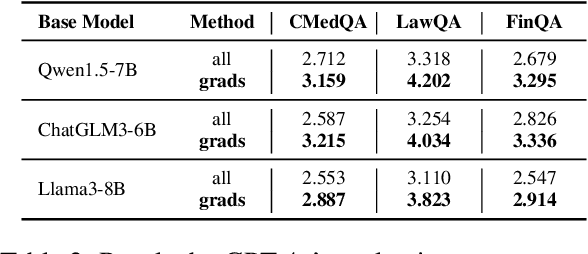
Despite large language models (LLMs) have achieved impressive achievements across numerous tasks, supervised fine-tuning (SFT) remains essential for adapting these models to specialized domains. However, SFT for domain specialization can be resource-intensive and sometimes leads to a deterioration in performance over general capabilities due to catastrophic forgetting (CF). To address these issues, we propose a self-adaptive gradient-aware data selection approach (GrADS) for supervised fine-tuning of LLMs, which identifies effective subsets of training data by analyzing gradients obtained from a preliminary training phase. Specifically, we design self-guided criteria that leverage the magnitude and statistical distribution of gradients to prioritize examples that contribute the most to the model's learning process. This approach enables the acquisition of representative samples that enhance LLMs understanding of domain-specific tasks. Through extensive experimentation with various LLMs across diverse domains such as medicine, law, and finance, GrADS has demonstrated significant efficiency and cost-effectiveness. Remarkably, utilizing merely 5% of the selected GrADS data, LLMs already surpass the performance of those fine-tuned on the entire dataset, and increasing to 50% of the data results in significant improvements! With catastrophic forgetting substantially mitigated simultaneously. We will release our code for GrADS later.
Lightweight Deep Unfolding Networks with Enhanced Robustness for Infrared Small Target Detection
Sep 10, 2025Infrared small target detection (ISTD) is one of the key techniques in image processing. Although deep unfolding networks (DUNs) have demonstrated promising performance in ISTD due to their model interpretability and data adaptability, existing methods still face significant challenges in parameter lightweightness and noise robustness. In this regard, we propose a highly lightweight framework based on robust principal component analysis (RPCA) called L-RPCANet. Technically, a hierarchical bottleneck structure is constructed to reduce and increase the channel dimension in the single-channel input infrared image to achieve channel-wise feature refinement, with bottleneck layers designed in each module to extract features. This reduces the number of channels in feature extraction and improves the lightweightness of network parameters. Furthermore, a noise reduction module is embedded to enhance the robustness against complex noise. In addition, squeeze-and-excitation networks (SENets) are leveraged as a channel attention mechanism to focus on the varying importance of different features across channels, thereby achieving excellent performance while maintaining both lightweightness and robustness. Extensive experiments on the ISTD datasets validate the superiority of our proposed method compared with state-of-the-art methods covering RPCANet, DRPCANet, and RPCANet++. The code will be available at https://github.com/xianchaoxiu/L-RPCANet.
RepoDebug: Repository-Level Multi-Task and Multi-Language Debugging Evaluation of Large Language Models
Sep 04, 2025Large Language Models (LLMs) have exhibited significant proficiency in code debugging, especially in automatic program repair, which may substantially reduce the time consumption of developers and enhance their efficiency. Significant advancements in debugging datasets have been made to promote the development of code debugging. However, these datasets primarily focus on assessing the LLM's function-level code repair capabilities, neglecting the more complex and realistic repository-level scenarios, which leads to an incomplete understanding of the LLM's challenges in repository-level debugging. While several repository-level datasets have been proposed, they often suffer from limitations such as limited diversity of tasks, languages, and error types. To mitigate this challenge, this paper introduces RepoDebug, a multi-task and multi-language repository-level code debugging dataset with 22 subtypes of errors that supports 8 commonly used programming languages and 3 debugging tasks. Furthermore, we conduct evaluation experiments on 10 LLMs, where Claude 3.5 Sonnect, the best-performing model, still cannot perform well in repository-level debugging.
ShortListing Model: A Streamlined SimplexDiffusion for Discrete Variable Generation
Aug 24, 2025Generative modeling of discrete variables is challenging yet crucial for applications in natural language processing and biological sequence design. We introduce the Shortlisting Model (SLM), a novel simplex-based diffusion model inspired by progressive candidate pruning. SLM operates on simplex centroids, reducing generation complexity and enhancing scalability. Additionally, SLM incorporates a flexible implementation of classifier-free guidance, enhancing unconditional generation performance. Extensive experiments on DNA promoter and enhancer design, protein design, character-level and large-vocabulary language modeling demonstrate the competitive performance and strong potential of SLM. Our code can be found at https://github.com/GenSI-THUAIR/SLM
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Jul 03, 2025

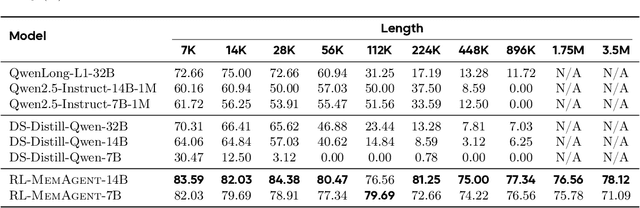
Despite improvements by length extrapolation, efficient attention and memory modules, handling infinitely long documents with linear complexity without performance degradation during extrapolation remains the ultimate challenge in long-text processing. We directly optimize for long-text tasks in an end-to-end fashion and introduce a novel agent workflow, MemAgent, which reads text in segments and updates the memory using an overwrite strategy. We extend the DAPO algorithm to facilitate training via independent-context multi-conversation generation. MemAgent has demonstrated superb long-context capabilities, being able to extrapolate from an 8K context trained on 32K text to a 3.5M QA task with performance loss < 5% and achieves 95%+ in 512K RULER test.