 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMON: Local Explanations via Modality-aware OptimizatioN
Feb 02, 2026Multimodal models are ubiquitous, yet existing explainability methods are often single-modal, architecture-dependent, or too computationally expensive to run at scale. We introduce LEMON (Local Explanations via Modality-aware OptimizatioN), a model-agnostic framework for local explanations of multimodal predictions. LEMON fits a single modality-aware surrogate with group-structured sparsity to produce unified explanations that disentangle modality-level contributions and feature-level attributions. The approach treats the predictor as a black box and is computationally efficient, requiring relatively few forward passes while remaining faithful under repeated perturbations. We evaluate LEMON on vision-language question answering and a clinical prediction task with image, text, and tabular inputs, comparing against representative multimodal baselines. Across backbones, LEMON achieves competitive deletion-based faithfulness while reducing black-box evaluations by 35-67 times and runtime by 2-8 times compared to strong multimodal baselines.
Deep in the Jungle: Towards Automating Chimpanzee Population Estimation
Jan 30, 2026The estimation of abundance and density in unmarked populations of great apes relies on statistical frameworks that require animal-to-camera distance measurements. In practice, acquiring these distances depends on labour-intensive manual interpretation of animal observations across large camera trap video corpora. This study introduces and evaluates an only sparsely explored alternative: the integration of computer vision-based monocular depth estimation (MDE) pipelines directly into ecological camera trap workflows for great ape conservation. Using a real-world dataset of 220 camera trap videos documenting a wild chimpanzee population, we combine two MDE models, Dense Prediction Transformers and Depth Anything, with multiple distance sampling strategies. These components are used to generate detection distance estimates, from which population density and abundance are inferred. Comparative analysis against manually derived ground-truth distances shows that calibrated DPT consistently outperforms Depth Anything. This advantage is observed in both distance estimation accuracy and downstream density and abundance inference. Nevertheless, both models exhibit systematic biases. We show that, given complex forest environments, they tend to overestimate detection distances and consequently underestimate density and abundance relative to conventional manual approaches. We further find that failures in animal detection across distance ranges are a primary factor limiting estimation accuracy. Overall, this work provides a case study that shows MDE-driven camera trap distance sampling is a viable and practical alternative to manual distance estimation. The proposed approach yields population estimates within 22% of those obtained using traditional methods.
Skeleton-Snippet Contrastive Learning with Multiscale Feature Fusion for Action Localization
Dec 22, 2025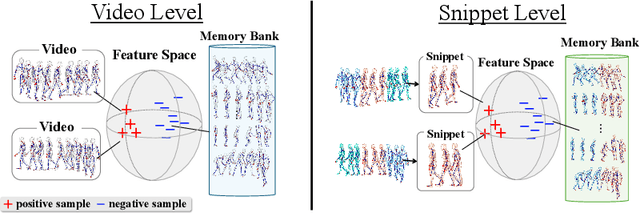
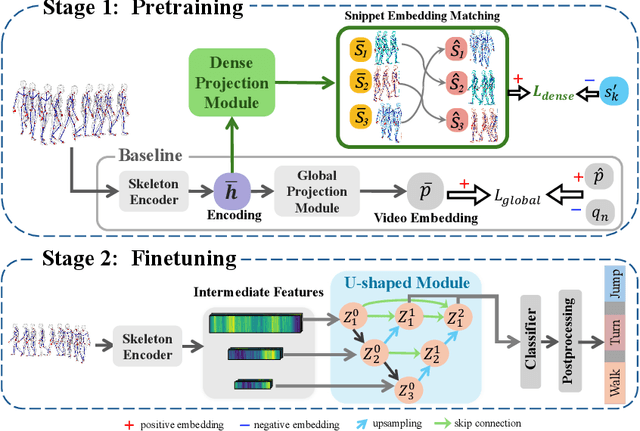
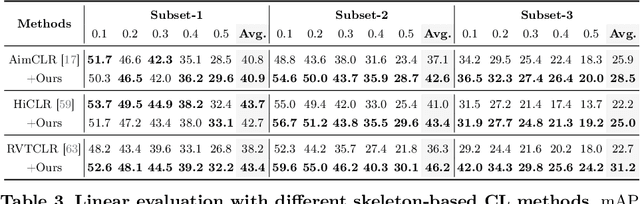
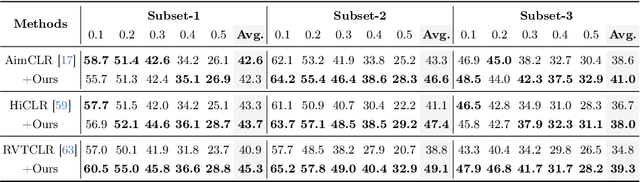
The self-supervised pretraining paradigm has achieved great success in learning 3D action representations for skeleton-based action recognition using contrastive learning. However, learning effective representations for skeleton-based temporal action localization remains challenging and underexplored. Unlike video-level {action} recognition, detecting action boundaries requires temporally sensitive features that capture subtle differences between adjacent frames where labels change. To this end, we formulate a snippet discrimination pretext task for self-supervised pretraining, which densely projects skeleton sequences into non-overlapping segments and promotes features that distinguish them across videos via contrastive learning. Additionally, we build on strong backbones of skeleton-based action recognition models by fusing intermediate features with a U-shaped module to enhance feature resolution for frame-level localization. Our approach consistently improves existing skeleton-based contrastive learning methods for action localization on BABEL across diverse subsets and evaluation protocols. We also achieve state-of-the-art transfer learning performance on PKUMMD with pretraining on NTU RGB+D and BABEL.
Visual-textual Dermatoglyphic Animal Biometrics: A First Case Study on Panthera tigris
Dec 16, 2025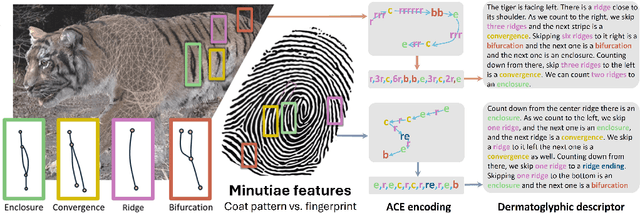
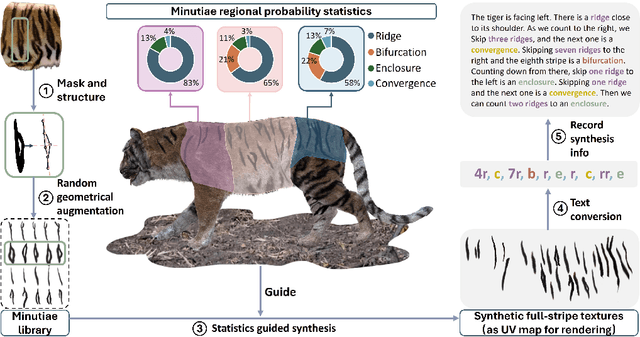
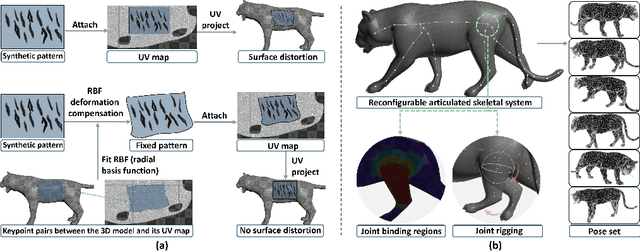
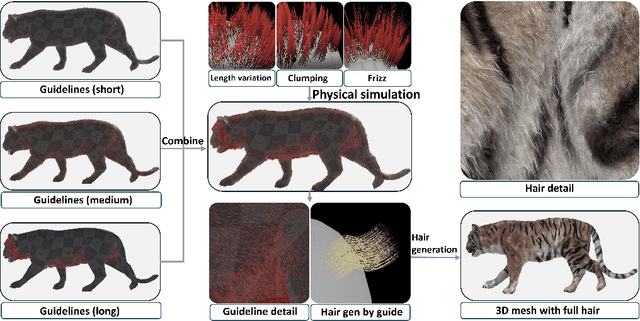
Biologists have long combined visuals with textual field notes to re-identify (Re-ID) animals. Contemporary AI tools automate this for species with distinctive morphological features but remain largely image-based. Here, we extend Re-ID methodologies by incorporating precise dermatoglyphic textual descriptors-an approach used in forensics but new to ecology. We demonstrate that these specialist semantics abstract and encode animal coat topology using human-interpretable language tags. Drawing on 84,264 manually labelled minutiae across 3,355 images of 185 tigers (Panthera tigris), we evaluate this visual-textual methodology, revealing novel capabilities for cross-modal identity retrieval. To optimise performance, we developed a text-image co-synthesis pipeline to generate 'virtual individuals', each comprising dozens of life-like visuals paired with dermatoglyphic text. Benchmarking against real-world scenarios shows this augmentation significantly boosts AI accuracy in cross-modal retrieval while alleviating data scarcity. We conclude that dermatoglyphic language-guided biometrics can overcome vision-only limitations, enabling textual-to-visual identity recovery underpinned by human-verifiable matchings. This represents a significant advance towards explainability in Re-ID and a language-driven unification of descriptive modalities in ecological monitoring.
Learning to Generate Cross-Task Unexploitable Examples
Dec 15, 2025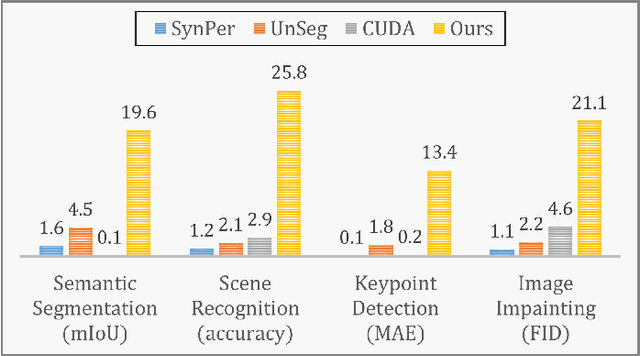
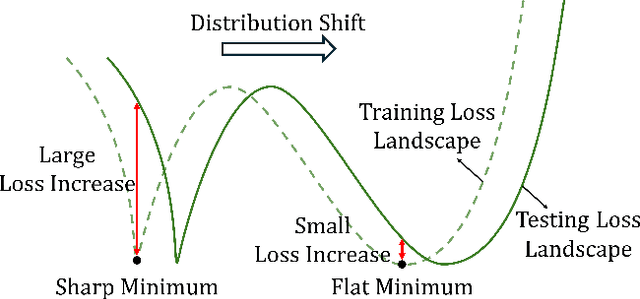

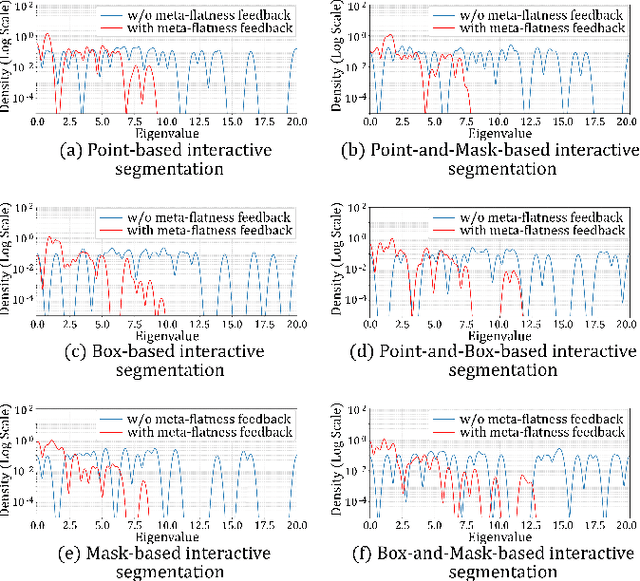
Unexploitable example generation aims to transform personal images into their unexploitable (unlearnable) versions before they are uploaded online, thereby preventing unauthorized exploitation of online personal images. Recently, this task has garnered significant research attention due to its critical relevance to personal data privacy. Yet, despite recent progress, existing methods for this task can still suffer from limited practical applicability, as they can fail to generate examples that are broadly unexploitable across different real-world computer vision tasks. To deal with this problem, in this work, we propose a novel Meta Cross-Task Unexploitable Example Generation (MCT-UEG) framework. At the core of our framework, to optimize the unexploitable example generator for effectively producing broadly unexploitable examples, we design a flat-minima-oriented meta training and testing scheme. Extensive experiments show the efficacy of our framework.
The SA-FARI Dataset: Segment Anything in Footage of Animals for Recognition and Identification
Nov 19, 2025Automated video analysis is critical for wildlife conservation. A foundational task in this domain is multi-animal tracking (MAT), which underpins applications such as individual re-identification and behavior recognition. However, existing datasets are limited in scale, constrained to a few species, or lack sufficient temporal and geographical diversity - leaving no suitable benchmark for training general-purpose MAT models applicable across wild animal populations. To address this, we introduce SA-FARI, the largest open-source MAT dataset for wild animals. It comprises 11,609 camera trap videos collected over approximately 10 years (2014-2024) from 741 locations across 4 continents, spanning 99 species categories. Each video is exhaustively annotated culminating in ~46 hours of densely annotated footage containing 16,224 masklet identities and 942,702 individual bounding boxes, segmentation masks, and species labels. Alongside the task-specific annotations, we publish anonymized camera trap locations for each video. Finally, we present comprehensive benchmarks on SA-FARI using state-of-the-art vision-language models for detection and tracking, including SAM 3, evaluated with both species-specific and generic animal prompts. We also compare against vision-only methods developed specifically for wildlife analysis. SA-FARI is the first large-scale dataset to combine high species diversity, multi-region coverage, and high-quality spatio-temporal annotations, offering a new foundation for advancing generalizable multianimal tracking in the wild. The dataset is available at $\href{https://www.conservationxlabs.com/sa-fari}{\text{conservationxlabs.com/SA-FARI}}$.
Clinically-aligned Multi-modal Chest X-ray Classification
Nov 12, 2025Radiology is essential to modern healthcare, yet rising demand and staffing shortages continue to pose major challenges. Recent advances in artificial intelligence have the potential to support radiologists and help address these challenges. Given its widespread use and clinical importance, chest X-ray classification is well suited to augment radiologists' workflows. However, most existing approaches rely solely on single-view, image-level inputs, ignoring the structured clinical information and multi-image studies available at the time of reporting. In this work, we introduce CaMCheX, a multimodal transformer-based framework that aligns multi-view chest X-ray studies with structured clinical data to better reflect how clinicians make diagnostic decisions. Our architecture employs view-specific ConvNeXt encoders for frontal and lateral chest radiographs, whose features are fused with clinical indications, history, and vital signs using a transformer fusion module. This design enables the model to generate context-aware representations that mirror reasoning in clinical practice. Our results exceed the state of the art for both the original MIMIC-CXR dataset and the more recent CXR-LT benchmarks, highlighting the value of clinically grounded multimodal alignment for advancing chest X-ray classification.
CARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025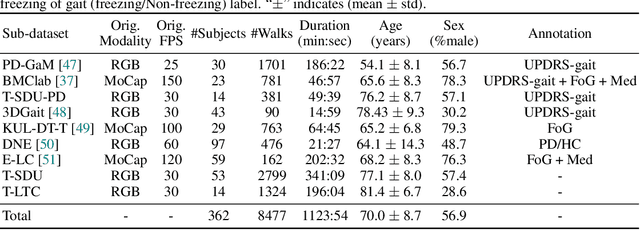
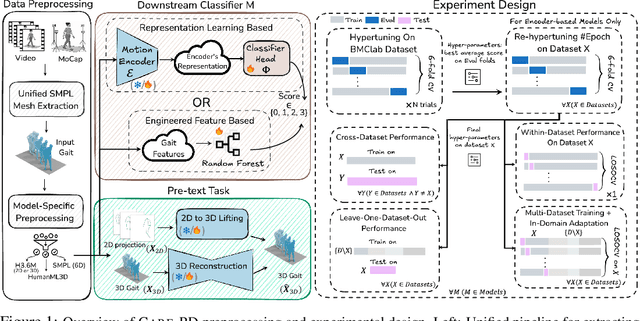
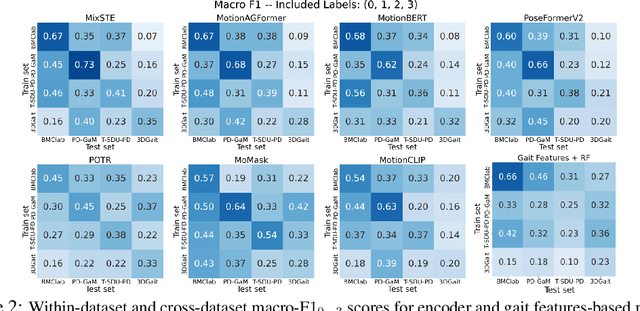
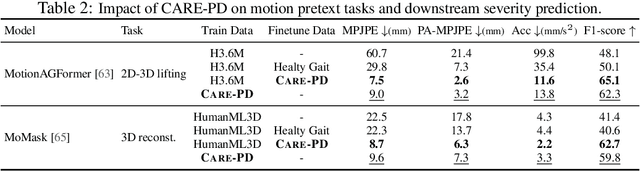
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
Towards Application-Specific Evaluation of Vision Models: Case Studies in Ecology and Biology
May 05, 2025Computer vision methods have demonstrated considerable potential to streamline ecological and biological workflows, with a growing number of datasets and models becoming available to the research community. However, these resources focus predominantly on evaluation using machine learning metrics, with relatively little emphasis on how their application impacts downstream analysis. We argue that models should be evaluated using application-specific metrics that directly represent model performance in the context of its final use case. To support this argument, we present two disparate case studies: (1) estimating chimpanzee abundance and density with camera trap distance sampling when using a video-based behaviour classifier and (2) estimating head rotation in pigeons using a 3D posture estimator. We show that even models with strong machine learning performance (e.g., 87% mAP) can yield data that leads to discrepancies in abundance estimates compared to expert-derived data. Similarly, the highest-performing models for posture estimation do not produce the most accurate inferences of gaze direction in pigeons. Motivated by these findings, we call for researchers to integrate application-specific metrics in ecological/biological datasets, allowing for models to be benchmarked in the context of their downstream application and to facilitate better integration of models into application workflows.
Unsupervised Cross-Domain 3D Human Pose Estimation via Pseudo-Label-Guided Global Transforms
Apr 17, 2025Existing 3D human pose estimation methods often suffer in performance, when applied to cross-scenario inference, due to domain shifts in characteristics such as camera viewpoint, position, posture, and body size. Among these factors, camera viewpoints and locations {have been shown} to contribute significantly to the domain gap by influencing the global positions of human poses. To address this, we propose a novel framework that explicitly conducts global transformations between pose positions in the camera coordinate systems of source and target domains. We start with a Pseudo-Label Generation Module that is applied to the 2D poses of the target dataset to generate pseudo-3D poses. Then, a Global Transformation Module leverages a human-centered coordinate system as a novel bridging mechanism to seamlessly align the positional orientations of poses across disparate domains, ensuring consistent spatial referencing. To further enhance generalization, a Pose Augmentor is incorporated to address variations in human posture and body size. This process is iterative, allowing refined pseudo-labels to progressively improve guidance for domain adaptation. Our method is evaluated on various cross-dataset benchmarks, including Human3.6M, MPI-INF-3DHP, and 3DPW. The proposed method outperforms state-of-the-art approaches and even outperforms the target-trained model.