 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Traffic Lights for Multi-Robot Navigation: Decentralized Planning with Centralized Conflict Resolution
Nov 11, 2025We present a hybrid multi-robot coordination framework that combines decentralized path planning with centralized conflict resolution. In our approach, each robot autonomously plans its path and shares this information with a centralized node. The centralized system detects potential conflicts and allows only one of the conflicting robots to proceed at a time, instructing others to stop outside the conflicting area to avoid deadlocks. Unlike traditional centralized planning methods, our system does not dictate robot paths but instead provides stop commands, functioning as a virtual traffic light. In simulation experiments with multiple robots, our approach increased the success rate of robots reaching their goals while reducing deadlocks. Furthermore, we successfully validated the system in real-world experiments with two quadruped robots and separately with wheeled Duckiebots.
The PanAf-FGBG Dataset: Understanding the Impact of Backgrounds in Wildlife Behaviour Recognition
Feb 28, 2025



Computer vision analysis of camera trap video footage is essential for wildlife conservation, as captured behaviours offer some of the earliest indicators of changes in population health. Recently, several high-impact animal behaviour datasets and methods have been introduced to encourage their use; however, the role of behaviour-correlated background information and its significant effect on out-of-distribution generalisation remain unexplored. In response, we present the PanAf-FGBG dataset, featuring 20 hours of wild chimpanzee behaviours, recorded at over 350 individual camera locations. Uniquely, it pairs every video with a chimpanzee (referred to as a foreground video) with a corresponding background video (with no chimpanzee) from the same camera location. We present two views of the dataset: one with overlapping camera locations and one with disjoint locations. This setup enables, for the first time, direct evaluation of in-distribution and out-of-distribution conditions, and for the impact of backgrounds on behaviour recognition models to be quantified. All clips come with rich behavioural annotations and metadata including unique camera IDs and detailed textual scene descriptions. Additionally, we establish several baselines and present a highly effective latent-space normalisation technique that boosts out-of-distribution performance by +5.42% mAP for convolutional and +3.75% mAP for transformer-based models. Finally, we provide an in-depth analysis on the role of backgrounds in out-of-distribution behaviour recognition, including the so far unexplored impact of background durations (i.e., the count of background frames within foreground videos).
Iterative Encoding-Decoding VAEs Anomaly Detection in NOAA's DART Time Series: A Machine Learning Approach for Enhancing Data Integrity for NASA's GRACE-FO Verification and Validation
Dec 20, 2024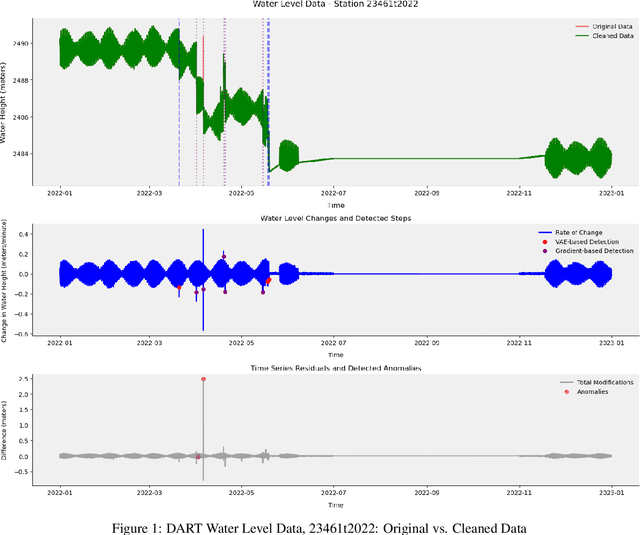
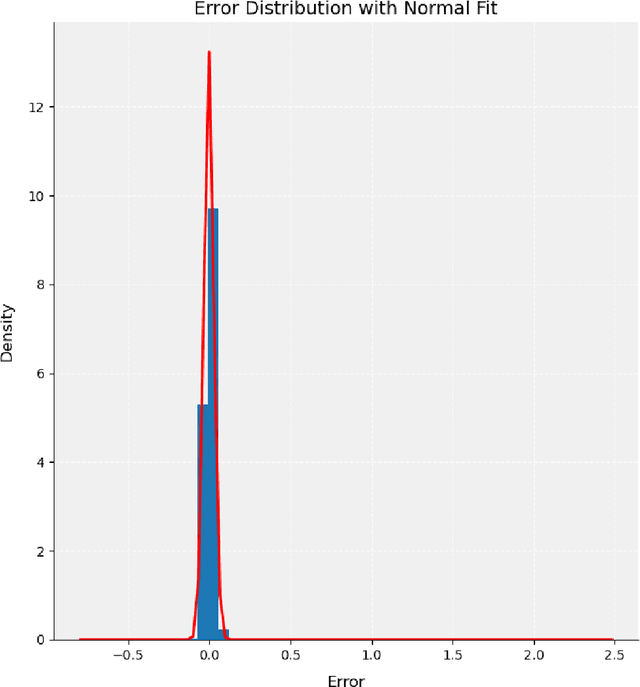


NOAA's Deep-ocean Assessment and Reporting of Tsunamis (DART) data are critical for NASA-JPL's tsunami detection, real-time operations, and oceanographic research. However, these time-series data often contain spikes, steps, and drifts that degrade data quality and obscure essential oceanographic features. To address these anomalies, the work introduces an Iterative Encoding-Decoding Variational Autoencoders (Iterative Encoding-Decoding VAEs) model to improve the quality of DART time series. Unlike traditional filtering and thresholding methods that risk distorting inherent signal characteristics, Iterative Encoding-Decoding VAEs progressively remove anomalies while preserving the data's latent structure. A hybrid thresholding approach further retains genuine oceanographic features near boundaries. Applied to complex DART datasets, this approach yields reconstructions that better maintain key oceanic properties compared to classical statistical techniques, offering improved robustness against spike removal and subtle step changes. The resulting high-quality data supports critical verification and validation efforts for the GRACE-FO mission at NASA-JPL, where accurate surface measurements are essential to modeling Earth's gravitational field and global water dynamics. Ultimately, this data processing method enhances tsunami detection and underpins future climate modeling with improved interpretability and reliability.
Assessment of LLM Responses to End-user Security Questions
Nov 21, 2024
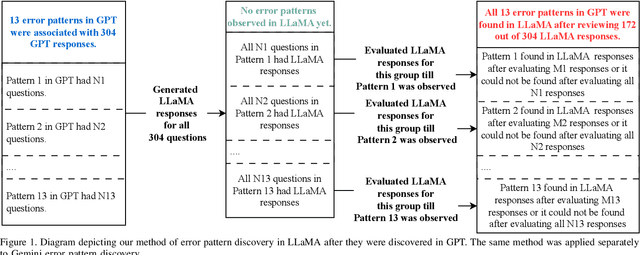


Answering end user security questions is challenging. While large language models (LLMs) like GPT, LLAMA, and Gemini are far from error-free, they have shown promise in answering a variety of questions outside of security. We studied LLM performance in the area of end user security by qualitatively evaluating 3 popular LLMs on 900 systematically collected end user security questions. While LLMs demonstrate broad generalist ``knowledge'' of end user security information, there are patterns of errors and limitations across LLMs consisting of stale and inaccurate answers, and indirect or unresponsive communication styles, all of which impacts the quality of information received. Based on these patterns, we suggest directions for model improvement and recommend user strategies for interacting with LLMs when seeking assistance with security.
PanAf20K: A Large Video Dataset for Wild Ape Detection and Behaviour Recognition
Jan 31, 2024
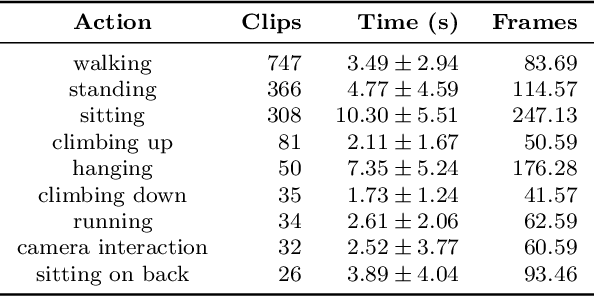

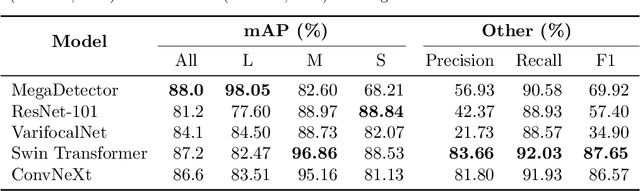
We present the PanAf20K dataset, the largest and most diverse open-access annotated video dataset of great apes in their natural environment. It comprises more than 7 million frames across ~20,000 camera trap videos of chimpanzees and gorillas collected at 14 field sites in tropical Africa as part of the Pan African Programme: The Cultured Chimpanzee. The footage is accompanied by a rich set of annotations and benchmarks making it suitable for training and testing a variety of challenging and ecologically important computer vision tasks including ape detection and behaviour recognition. Furthering AI analysis of camera trap information is critical given the International Union for Conservation of Nature now lists all species in the great ape family as either Endangered or Critically Endangered. We hope the dataset can form a solid basis for engagement of the AI community to improve performance, efficiency, and result interpretation in order to support assessments of great ape presence, abundance, distribution, and behaviour and thereby aid conservation efforts.
Adversarial Attacks on Speech Recognition Systems for Mission-Critical Applications: A Survey
Feb 22, 2022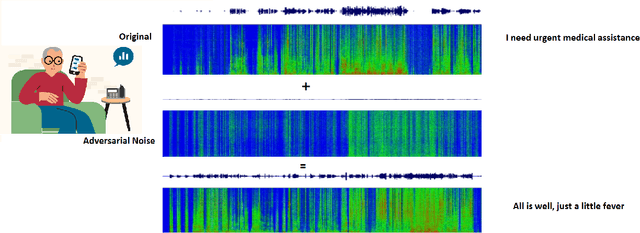
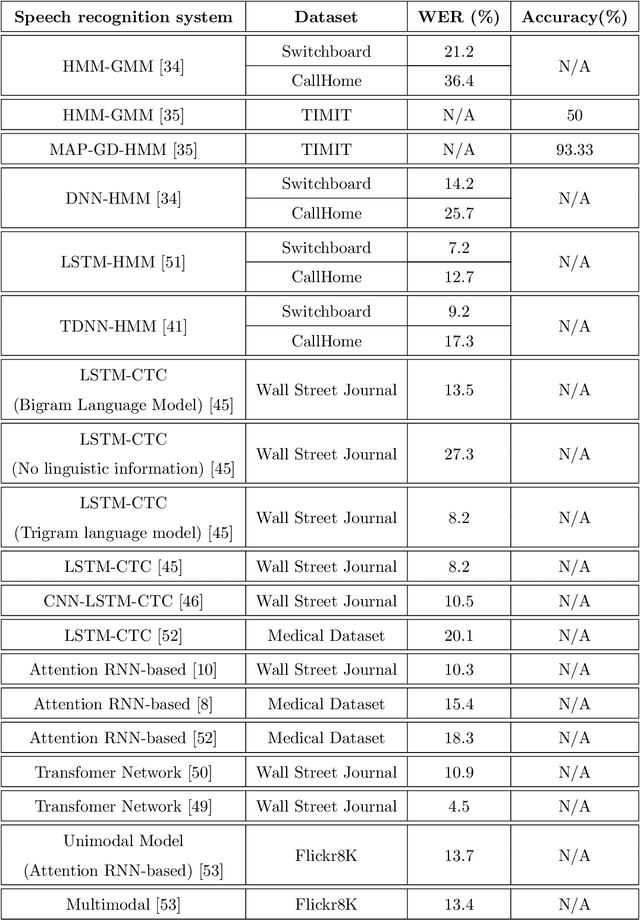
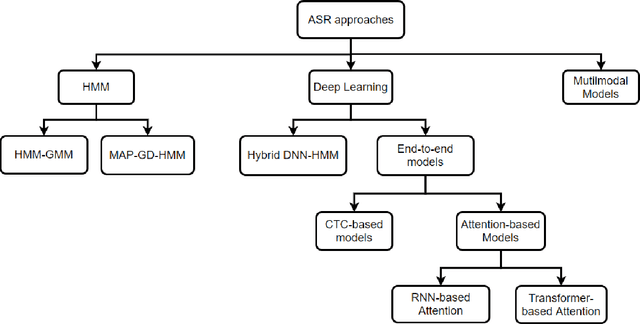
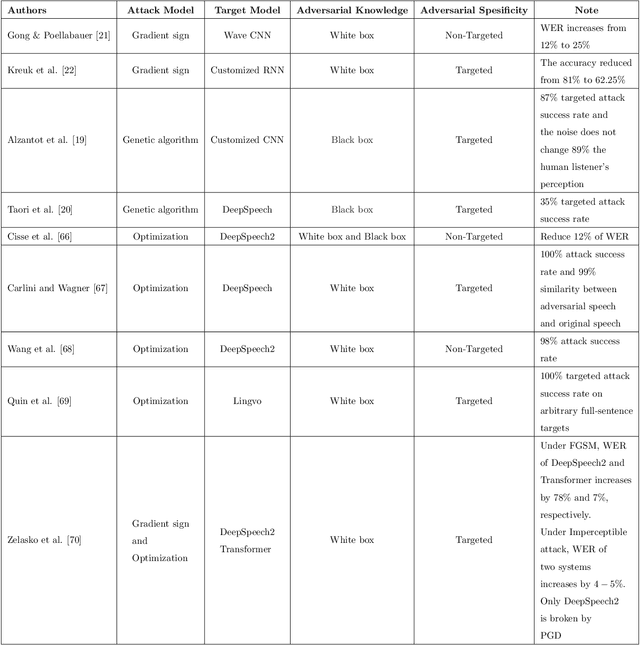
A Machine-Critical Application is a system that is fundamentally necessary to the success of specific and sensitive operations such as search and recovery, rescue, military, and emergency management actions. Recent advances in Machine Learning, Natural Language Processing, voice recognition, and speech processing technologies have naturally allowed the development and deployment of speech-based conversational interfaces to interact with various machine-critical applications. While these conversational interfaces have allowed users to give voice commands to carry out strategic and critical activities, their robustness to adversarial attacks remains uncertain and unclear. Indeed, Adversarial Artificial Intelligence (AI) which refers to a set of techniques that attempt to fool machine learning models with deceptive data, is a growing threat in the AI and machine learning research community, in particular for machine-critical applications. The most common reason of adversarial attacks is to cause a malfunction in a machine learning model. An adversarial attack might entail presenting a model with inaccurate or fabricated samples as it's training data, or introducing maliciously designed data to deceive an already trained model. While focusing on speech recognition for machine-critical applications, in this paper, we first review existing speech recognition techniques, then, we investigate the effectiveness of adversarial attacks and defenses against these systems, before outlining research challenges, defense recommendations, and future work. This paper is expected to serve researchers and practitioners as a reference to help them in understanding the challenges, position themselves and, ultimately, help them to improve existing models of speech recognition for mission-critical applications. Keywords: Mission-Critical Applications, Adversarial AI, Speech Recognition Systems.
Do People Prefer "Natural" code?
Oct 08, 2019
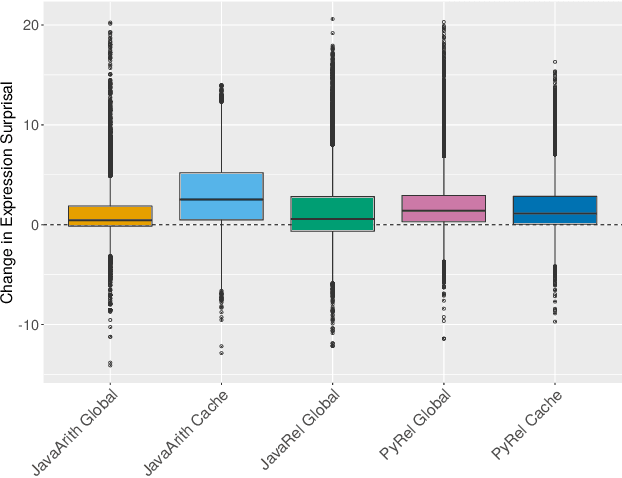
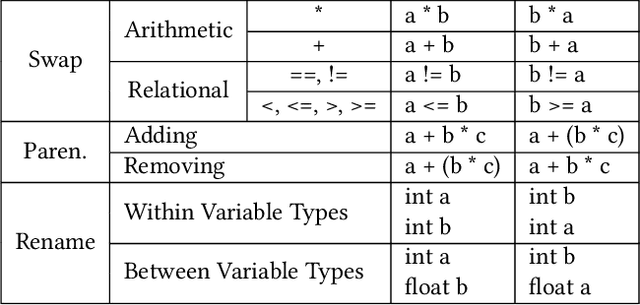
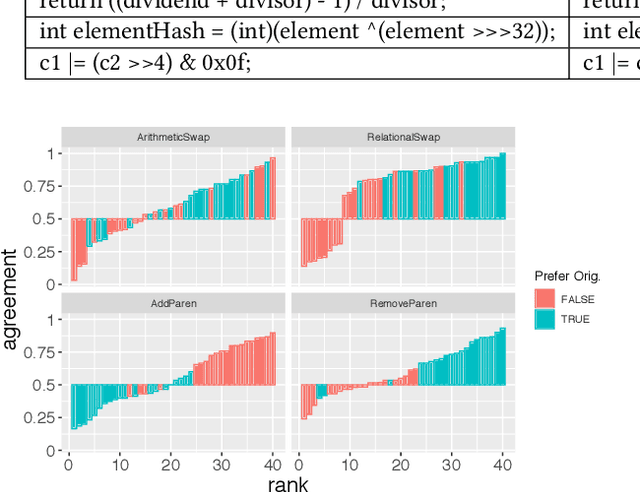
Natural code is known to be very repetitive (much more so than natural language corpora); furthermore, this repetitiveness persists, even after accounting for the simpler syntax of code. However, programming languages are very expressive, allowing a great many different ways (all clear and unambiguous) to express even very simple computations. So why is natural code repetitive? We hypothesize that the reasons for this lie in fact that code is bimodal: it is executed by machines, but also read by humans. This bimodality, we argue, leads developers to write code in certain preferred ways that would be familiar to code readers. To test this theory, we 1) model familiarity using a language model estimated over a large training corpus and 2) run an experiment applying several meaning preserving transformations to Java and Python expressions in a distinct test corpus to see if forms more familiar to readers (as predicted by the language models) are in fact the ones actually written. We find that these transformations generally produce program structures that are less common in practice, supporting the theory that the high repetitiveness in code is a matter of deliberate preference. Finally, 3) we use a human subject study to show alignment between language model score and human preference for the first time in code, providing support for using this measure to improve code.
Enabling Intuitive Human-Robot Teaming Using Augmented Reality and Gesture Control
Sep 13, 2019

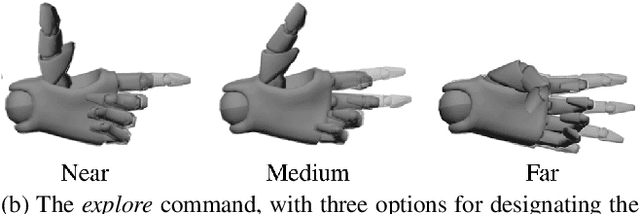

Human-robot teaming offers great potential because of the opportunities to combine strengths of heterogeneous agents. However, one of the critical challenges in realizing an effective human-robot team is efficient information exchange - both from the human to the robot as well as from the robot to the human. In this work, we present and analyze an augmented reality-enabled, gesture-based system that supports intuitive human-robot teaming through improved information exchange. Our proposed system requires no external instrumentation aside from human-wearable devices and shows promise of real-world applicability for service-oriented missions. Additionally, we present preliminary results from a pilot study with human participants, and highlight lessons learned and open research questions that may help direct future development, fielding, and experimentation of autonomous HRI systems.
* Proceedings of the Artificial Intelligence for Human-Robot Interaction AAAI Symposium Series (AI-HRI 2019)
Nonparametric mixture of Gaussian graphical models
Dec 31, 2015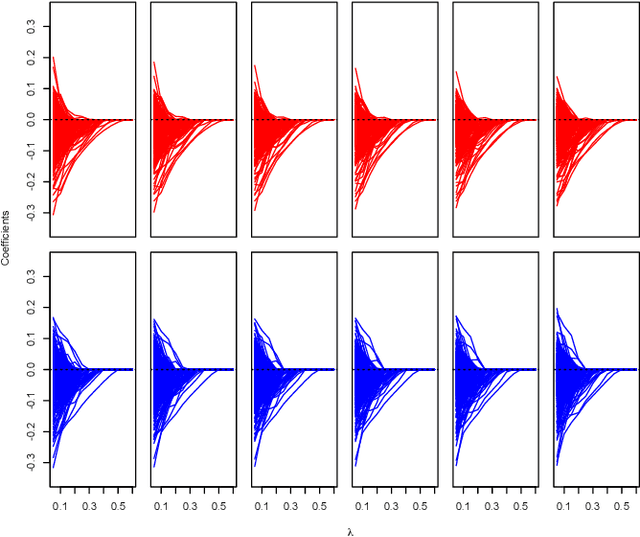
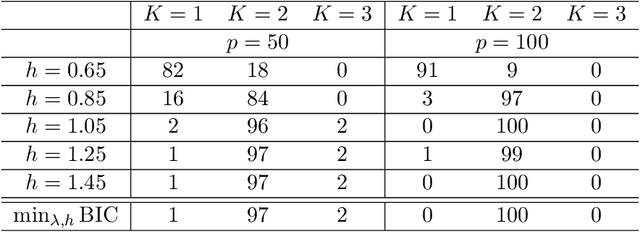
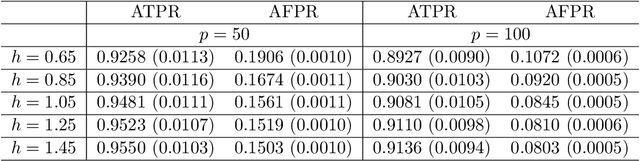
Graphical model has been widely used to investigate the complex dependence structure of high-dimensional data, and it is common to assume that observed data follow a homogeneous graphical model. However, observations usually come from different resources and have heterogeneous hidden commonality in real-world applications. Thus, it is of great importance to estimate heterogeneous dependencies and discover subpopulation with certain commonality across the whole population. In this work, we introduce a novel regularized estimation scheme for learning nonparametric mixture of Gaussian graphical models, which extends the methodology and applicability of Gaussian graphical models and mixture models. We propose a unified penalized likelihood approach to effectively estimate nonparametric functional parameters and heterogeneous graphical parameters. We further design an efficient generalized effective EM algorithm to address three significant challenges: high-dimensionality, non-convexity, and label switching. Theoretically, we study both the algorithmic convergence of our proposed algorithm and the asymptotic properties of our proposed estimators. Numerically, we demonstrate the performance of our method in simulation studies and a real application to estimate human brain functional connectivity from ADHD imaging data, where two heterogeneous conditional dependencies are explained through profiling demographic variables and supported by existing scientific findings.