 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models and Simple, Stupid Bugs
Mar 20, 2023With the advent of powerful neural language models, AI-based systems to assist developers in coding tasks are becoming widely available; Copilot is one such system. Copilot uses Codex, a large language model (LLM), to complete code conditioned on a preceding "prompt". Codex, however, is trained on public GitHub repositories, viz., on code that may include bugs and vulnerabilities. Previous studies [1], [2] show Codex reproduces vulnerabilities seen in training. In this study, we examine how prone Codex is to generate an interesting bug category, single statement bugs, commonly referred to as simple, stupid bugs or SStuBs in the MSR community. We find that Codex and similar LLMs do help avoid some SStuBs, but do produce known, verbatim SStuBs as much as 2x as likely than known, verbatim correct code. We explore the consequences of the Codex generated SStuBs and propose avoidance strategies that suggest the possibility of reducing the production of known, verbatim SStubs, and increase the possibility of producing known, verbatim fixes.
Do People Prefer "Natural" code?
Oct 08, 2019
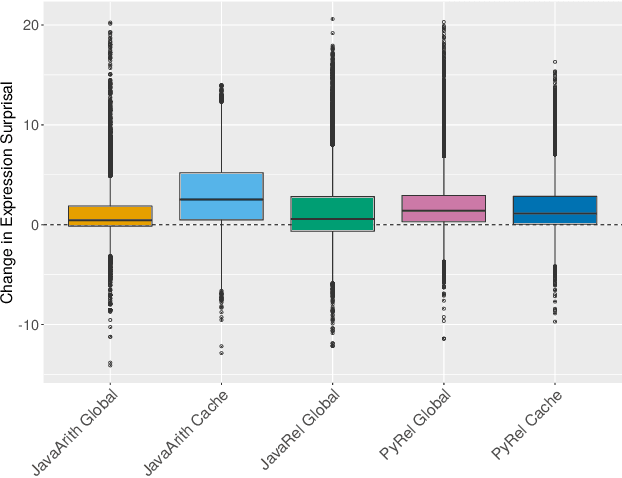
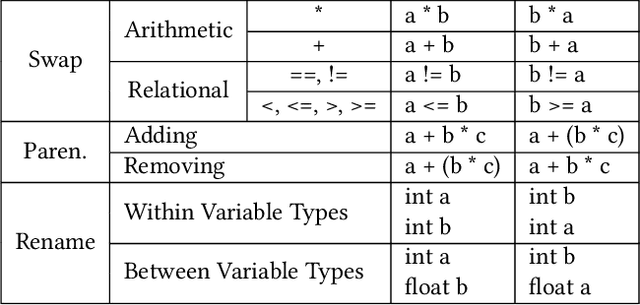
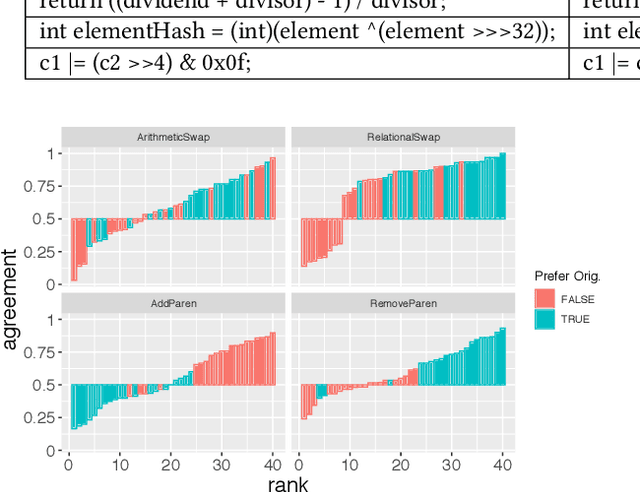
Natural code is known to be very repetitive (much more so than natural language corpora); furthermore, this repetitiveness persists, even after accounting for the simpler syntax of code. However, programming languages are very expressive, allowing a great many different ways (all clear and unambiguous) to express even very simple computations. So why is natural code repetitive? We hypothesize that the reasons for this lie in fact that code is bimodal: it is executed by machines, but also read by humans. This bimodality, we argue, leads developers to write code in certain preferred ways that would be familiar to code readers. To test this theory, we 1) model familiarity using a language model estimated over a large training corpus and 2) run an experiment applying several meaning preserving transformations to Java and Python expressions in a distinct test corpus to see if forms more familiar to readers (as predicted by the language models) are in fact the ones actually written. We find that these transformations generally produce program structures that are less common in practice, supporting the theory that the high repetitiveness in code is a matter of deliberate preference. Finally, 3) we use a human subject study to show alignment between language model score and human preference for the first time in code, providing support for using this measure to improve code.