 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedNLP: A Research Platform for Federated Learning in Natural Language Processing
Apr 18, 2021
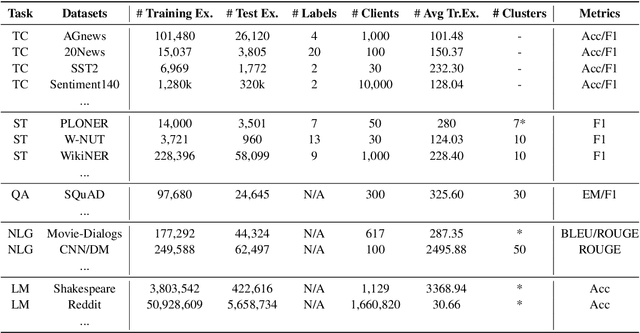
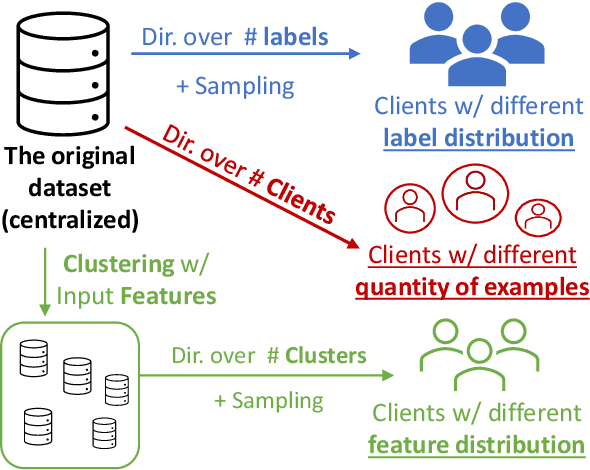
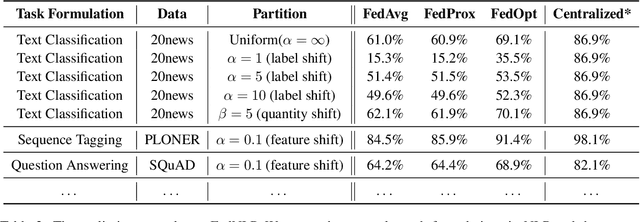
Increasing concerns and regulations about data privacy, necessitate the study of privacy-preserving methods for natural language processing (NLP) applications. Federated learning (FL) provides promising methods for a large number of clients (i.e., personal devices or organizations) to collaboratively learn a shared global model to benefit all clients, while allowing users to keep their data locally. To facilitate FL research in NLP, we present the FedNLP, a research platform for federated learning in NLP. FedNLP supports various popular task formulations in NLP such as text classification, sequence tagging, question answering, seq2seq generation, and language modeling. We also implement an interface between Transformer language models (e.g., BERT) and FL methods (e.g., FedAvg, FedOpt, etc.) for distributed training. The evaluation protocol of this interface supports a comprehensive collection of non-IID partitioning strategies. Our preliminary experiments with FedNLP reveal that there exists a large performance gap between learning on decentralized and centralized datasets -- opening intriguing and exciting future research directions aimed at developing FL methods suited to NLP tasks.
Do People Prefer "Natural" code?
Oct 08, 2019
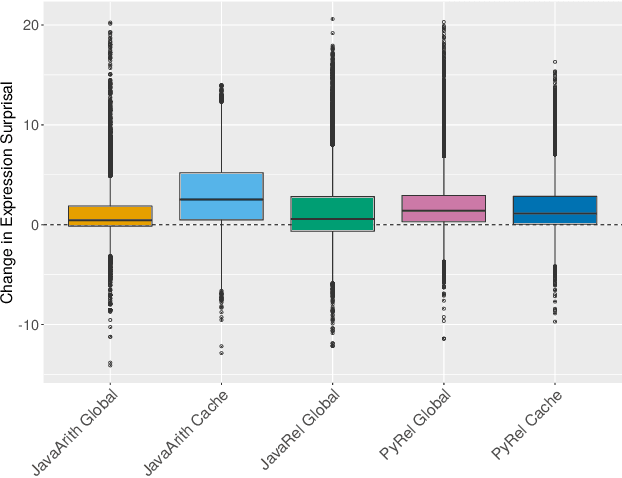
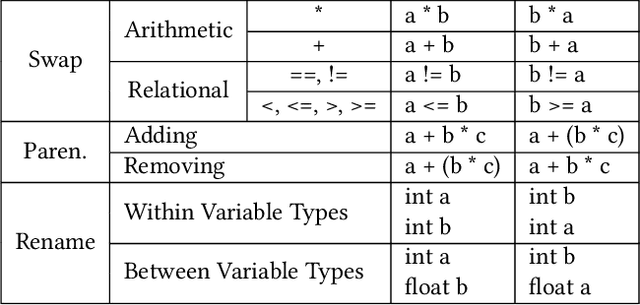
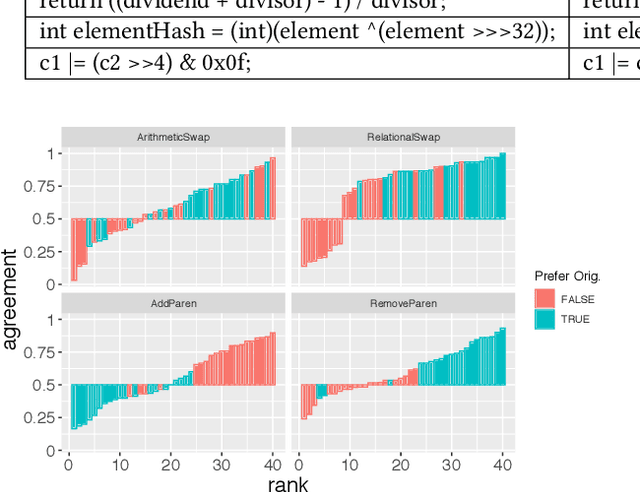
Natural code is known to be very repetitive (much more so than natural language corpora); furthermore, this repetitiveness persists, even after accounting for the simpler syntax of code. However, programming languages are very expressive, allowing a great many different ways (all clear and unambiguous) to express even very simple computations. So why is natural code repetitive? We hypothesize that the reasons for this lie in fact that code is bimodal: it is executed by machines, but also read by humans. This bimodality, we argue, leads developers to write code in certain preferred ways that would be familiar to code readers. To test this theory, we 1) model familiarity using a language model estimated over a large training corpus and 2) run an experiment applying several meaning preserving transformations to Java and Python expressions in a distinct test corpus to see if forms more familiar to readers (as predicted by the language models) are in fact the ones actually written. We find that these transformations generally produce program structures that are less common in practice, supporting the theory that the high repetitiveness in code is a matter of deliberate preference. Finally, 3) we use a human subject study to show alignment between language model score and human preference for the first time in code, providing support for using this measure to improve code.