 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Super Agent System with Hybrid AI Routers
Apr 11, 2025AI Agents powered by Large Language Models are transforming the world through enormous applications. A super agent has the potential to fulfill diverse user needs, such as summarization, coding, and research, by accurately understanding user intent and leveraging the appropriate tools to solve tasks. However, to make such an agent viable for real-world deployment and accessible at scale, significant optimizations are required to ensure high efficiency and low cost. This paper presents a design of the Super Agent System. Upon receiving a user prompt, the system first detects the intent of the user, then routes the request to specialized task agents with the necessary tools or automatically generates agentic workflows. In practice, most applications directly serve as AI assistants on edge devices such as phones and robots. As different language models vary in capability and cloud-based models often entail high computational costs, latency, and privacy concerns, we then explore the hybrid mode where the router dynamically selects between local and cloud models based on task complexity. Finally, we introduce the blueprint of an on-device super agent enhanced with cloud. With advances in multi-modality models and edge hardware, we envision that most computations can be handled locally, with cloud collaboration only as needed. Such architecture paves the way for super agents to be seamlessly integrated into everyday life in the near future.
Bridging the Safety Gap: A Guardrail Pipeline for Trustworthy LLM Inferences
Feb 12, 2025We present Wildflare GuardRail, a guardrail pipeline designed to enhance the safety and reliability of Large Language Model (LLM) inferences by systematically addressing risks across the entire processing workflow. Wildflare GuardRail integrates several core functional modules, including Safety Detector that identifies unsafe inputs and detects hallucinations in model outputs while generating root-cause explanations, Grounding that contextualizes user queries with information retrieved from vector databases, Customizer that adjusts outputs in real time using lightweight, rule-based wrappers, and Repairer that corrects erroneous LLM outputs using hallucination explanations provided by Safety Detector. Results show that our unsafe content detection model in Safety Detector achieves comparable performance with OpenAI API, though trained on a small dataset constructed with several public datasets. Meanwhile, the lightweight wrappers can address malicious URLs in model outputs in 1.06s per query with 100% accuracy without costly model calls. Moreover, the hallucination fixing model demonstrates effectiveness in reducing hallucinations with an accuracy of 80.7%.
Fox-1 Technical Report
Nov 08, 2024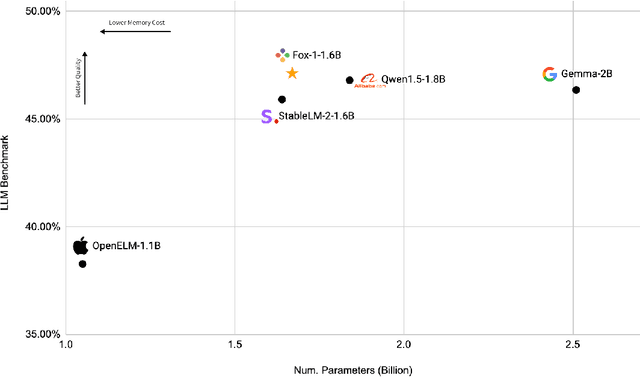

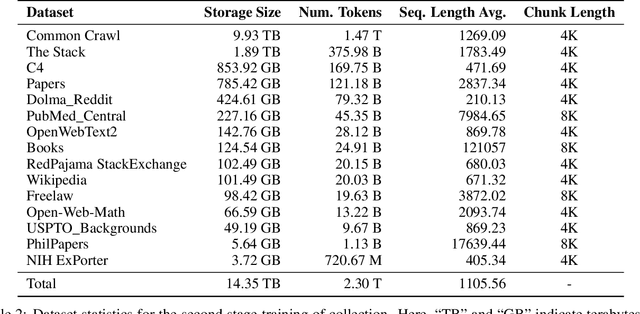
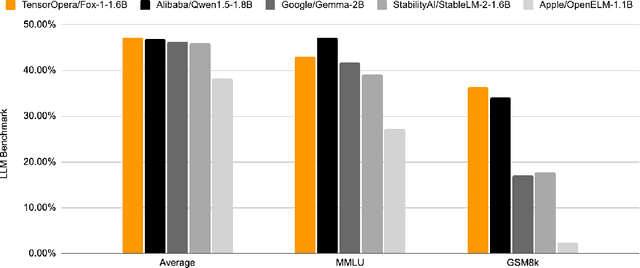
We present Fox-1, a series of small language models (SLMs) consisting of Fox-1-1.6B and Fox-1-1.6B-Instruct-v0.1. These models are pre-trained on 3 trillion tokens of web-scraped document data and fine-tuned with 5 billion tokens of instruction-following and multi-turn conversation data. Aiming to improve the pre-training efficiency, Fox-1-1.6B model introduces a novel 3-stage data curriculum across all the training data with 2K-8K sequence length. In architecture design, Fox-1 features a deeper layer structure, an expanded vocabulary, and utilizes Grouped Query Attention (GQA), offering a performant and efficient architecture compared to other SLMs. Fox-1 achieves better or on-par performance in various benchmarks compared to StableLM-2-1.6B, Gemma-2B, Qwen1.5-1.8B, and OpenELM1.1B, with competitive inference speed and throughput. The model weights have been released under the Apache 2.0 license, where we aim to promote the democratization of LLMs and make them fully accessible to the whole open-source community.
Alopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.
PolyRouter: A Multi-LLM Querying System
Aug 26, 2024



With the rapid growth of Large Language Models (LLMs) across various domains, numerous new LLMs have emerged, each possessing domain-specific expertise. This proliferation has highlighted the need for quick, high-quality, and cost-effective LLM query response methods. Yet, no single LLM exists to efficiently balance this trilemma. Some models are powerful but extremely costly, while others are fast and inexpensive but qualitatively inferior. To address this challenge, we present PolyRouter, a non-monolithic LLM querying system that seamlessly integrates various LLM experts into a single query interface and dynamically routes incoming queries to the most high-performant expert based on query's requirements. Through extensive experiments, we demonstrate that when compared to standalone expert models, PolyRouter improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Jul 23, 2024Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.
TorchOpera: A Compound AI System for LLM Safety
Jun 16, 2024We introduce TorchOpera, a compound AI system for enhancing the safety and quality of prompts and responses for Large Language Models. TorchOpera ensures that all user prompts are safe, contextually grounded, and effectively processed, while enhancing LLM responses to be relevant and high quality. TorchOpera utilizes the vector database for contextual grounding, rule-based wrappers for flexible modifications, and specialized mechanisms for detecting and adjusting unsafe or incorrect content. We also provide a view of the compound AI system to reduce the computational cost. Extensive experiments show that TorchOpera ensures the safety, reliability, and applicability of LLMs in real-world settings while maintaining the efficiency of LLM responses.
LLM Multi-Agent Systems: Challenges and Open Problems
Feb 05, 2024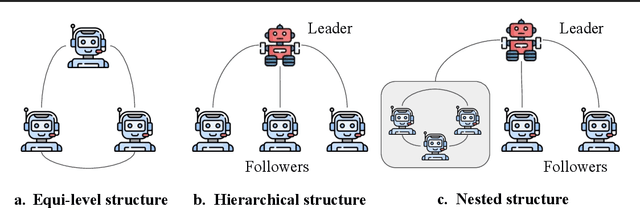
This paper explores existing works of multi-agent systems and identifies challenges that remain inadequately addressed. By leveraging the diverse capabilities and roles of individual agents within a multi-agent system, these systems can tackle complex tasks through collaboration. We discuss optimizing task allocation, fostering robust reasoning through iterative debates, managing complex and layered context information, and enhancing memory management to support the intricate interactions within multi-agent systems. We also explore the potential application of multi-agent systems in blockchain systems to shed light on their future development and application in real-world distributed systems.
A Data-Free Approach to Mitigate Catastrophic Forgetting in Federated Class Incremental Learning for Vision Tasks
Nov 21, 2023



Deep learning models often suffer from forgetting previously learned information when trained on new data. This problem is exacerbated in federated learning (FL), where the data is distributed and can change independently for each user. Many solutions are proposed to resolve this catastrophic forgetting in a centralized setting. However, they do not apply directly to FL because of its unique complexities, such as privacy concerns and resource limitations. To overcome these challenges, this paper presents a framework for $\textbf{federated class incremental learning}$ that utilizes a generative model to synthesize samples from past distributions. This data can be later exploited alongside the training data to mitigate catastrophic forgetting. To preserve privacy, the generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Moreover, our solution does not demand the users to store old data or models, which gives them the freedom to join/leave the training at any time. Additionally, we introduce SuperImageNet, a new regrouping of the ImageNet dataset specifically tailored for federated continual learning. We demonstrate significant improvements compared to existing baselines through extensive experiments on multiple datasets.
Kick Bad Guys Out! Zero-Knowledge-Proof-Based Anomaly Detection in Federated Learning
Oct 06, 2023

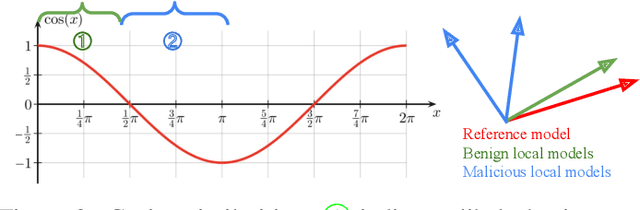
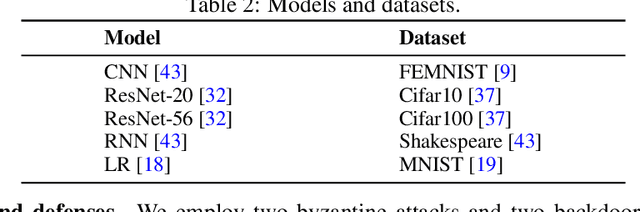
Federated learning (FL) systems are vulnerable to malicious clients that submit poisoned local models to achieve their adversarial goals, such as preventing the convergence of the global model or inducing the global model to misclassify some data. Many existing defense mechanisms are impractical in real-world FL systems, as they require prior knowledge of the number of malicious clients or rely on re-weighting or modifying submissions. This is because adversaries typically do not announce their intentions before attacking, and re-weighting might change aggregation results even in the absence of attacks. To address these challenges in real FL systems, this paper introduces a cutting-edge anomaly detection approach with the following features: i) Detecting the occurrence of attacks and performing defense operations only when attacks happen; ii) Upon the occurrence of an attack, further detecting the malicious client models and eliminating them without harming the benign ones; iii) Ensuring honest execution of defense mechanisms at the server by leveraging a zero-knowledge proof mechanism. We validate the superior performance of the proposed approach with extensive experiments.