 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-IMM: A Dataset and Benchmark for Irregular Multimodal Multivariate Time Series
Jun 12, 2025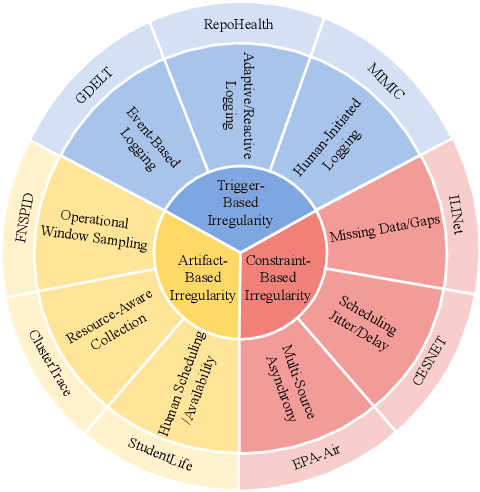
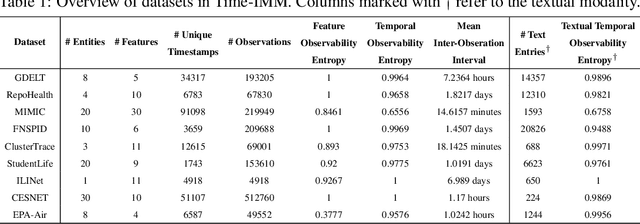
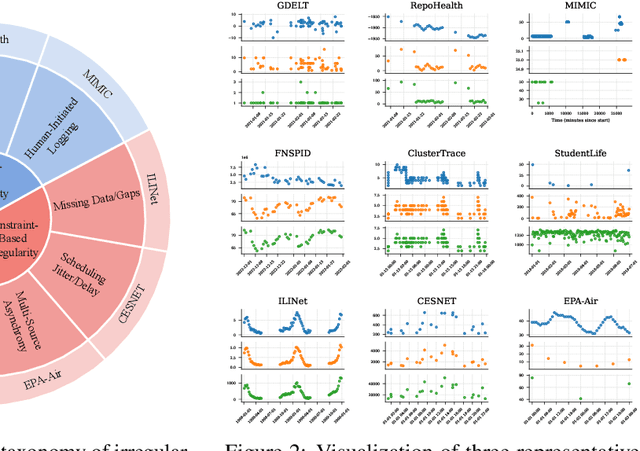
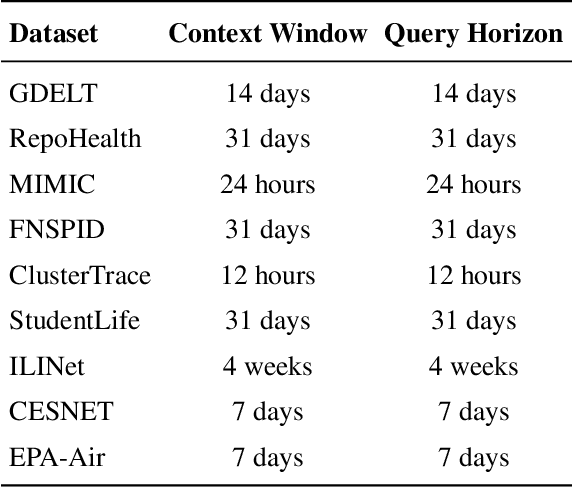
Time series data in real-world applications such as healthcare, climate modeling, and finance are often irregular, multimodal, and messy, with varying sampling rates, asynchronous modalities, and pervasive missingness. However, existing benchmarks typically assume clean, regularly sampled, unimodal data, creating a significant gap between research and real-world deployment. We introduce Time-IMM, a dataset specifically designed to capture cause-driven irregularity in multimodal multivariate time series. Time-IMM represents nine distinct types of time series irregularity, categorized into trigger-based, constraint-based, and artifact-based mechanisms. Complementing the dataset, we introduce IMM-TSF, a benchmark library for forecasting on irregular multimodal time series, enabling asynchronous integration and realistic evaluation. IMM-TSF includes specialized fusion modules, including a timestamp-to-text fusion module and a multimodality fusion module, which support both recency-aware averaging and attention-based integration strategies. Empirical results demonstrate that explicitly modeling multimodality on irregular time series data leads to substantial gains in forecasting performance. Time-IMM and IMM-TSF provide a foundation for advancing time series analysis under real-world conditions. The dataset is publicly available at https://www.kaggle.com/datasets/blacksnail789521/time-imm/data, and the benchmark library can be accessed at https://anonymous.4open.science/r/IMMTSF_NeurIPS2025.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
FD-Bench: A Modular and Fair Benchmark for Data-driven Fluid Simulation
May 25, 2025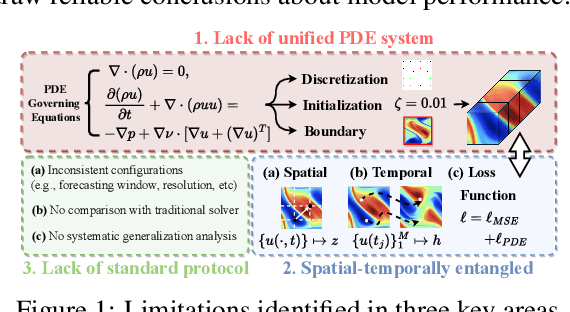

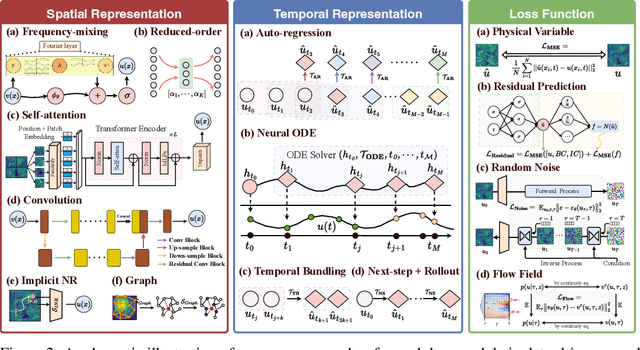
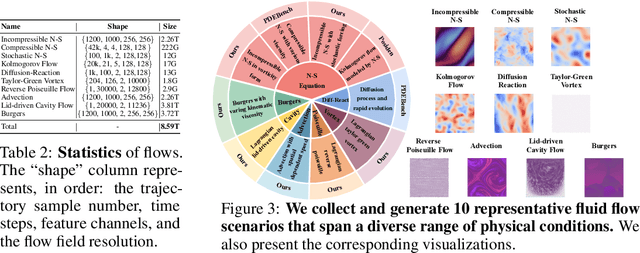
Data-driven modeling of fluid dynamics has advanced rapidly with neural PDE solvers, yet a fair and strong benchmark remains fragmented due to the absence of unified PDE datasets and standardized evaluation protocols. Although architectural innovations are abundant, fair assessment is further impeded by the lack of clear disentanglement between spatial, temporal and loss modules. In this paper, we introduce FD-Bench, the first fair, modular, comprehensive and reproducible benchmark for data-driven fluid simulation. FD-Bench systematically evaluates 85 baseline models across 10 representative flow scenarios under a unified experimental setup. It provides four key contributions: (1) a modular design enabling fair comparisons across spatial, temporal, and loss function modules; (2) the first systematic framework for direct comparison with traditional numerical solvers; (3) fine-grained generalization analysis across resolutions, initial conditions, and temporal windows; and (4) a user-friendly, extensible codebase to support future research. Through rigorous empirical studies, FD-Bench establishes the most comprehensive leaderboard to date, resolving long-standing issues in reproducibility and comparability, and laying a foundation for robust evaluation of future data-driven fluid models. The code is open-sourced at https://anonymous.4open.science/r/FD-Bench-15BC.
CellVerse: Do Large Language Models Really Understand Cell Biology?
May 09, 2025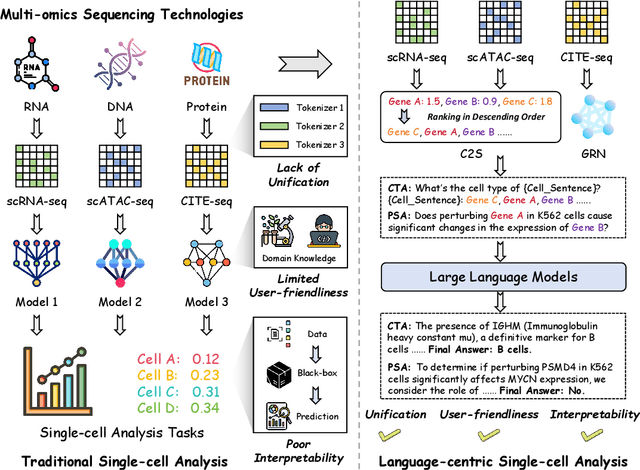
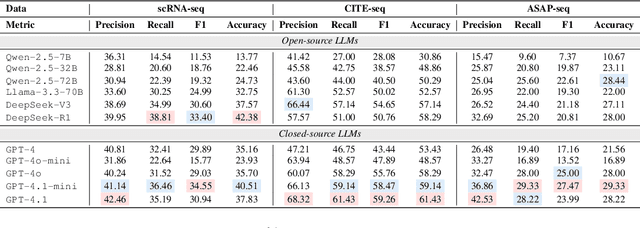
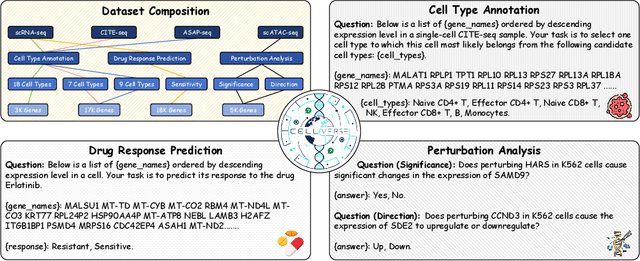
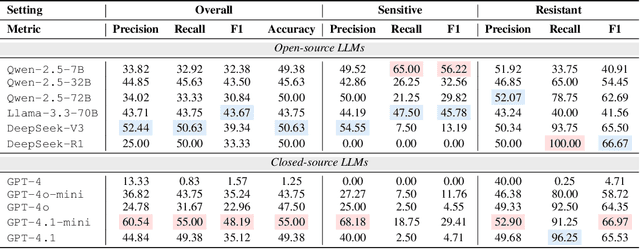
Recent studies have demonstrated the feasibility of modeling single-cell data as natural languages and the potential of leveraging powerful large language models (LLMs) for understanding cell biology. However, a comprehensive evaluation of LLMs' performance on language-driven single-cell analysis tasks still remains unexplored. Motivated by this challenge, we introduce CellVerse, a unified language-centric question-answering benchmark that integrates four types of single-cell multi-omics data and encompasses three hierarchical levels of single-cell analysis tasks: cell type annotation (cell-level), drug response prediction (drug-level), and perturbation analysis (gene-level). Going beyond this, we systematically evaluate the performance across 14 open-source and closed-source LLMs ranging from 160M to 671B on CellVerse. Remarkably, the experimental results reveal: (1) Existing specialist models (C2S-Pythia) fail to make reasonable decisions across all sub-tasks within CellVerse, while generalist models such as Qwen, Llama, GPT, and DeepSeek family models exhibit preliminary understanding capabilities within the realm of cell biology. (2) The performance of current LLMs falls short of expectations and has substantial room for improvement. Notably, in the widely studied drug response prediction task, none of the evaluated LLMs demonstrate significant performance improvement over random guessing. CellVerse offers the first large-scale empirical demonstration that significant challenges still remain in applying LLMs to cell biology. By introducing CellVerse, we lay the foundation for advancing cell biology through natural languages and hope this paradigm could facilitate next-generation single-cell analysis.
Toward Super Agent System with Hybrid AI Routers
Apr 11, 2025AI Agents powered by Large Language Models are transforming the world through enormous applications. A super agent has the potential to fulfill diverse user needs, such as summarization, coding, and research, by accurately understanding user intent and leveraging the appropriate tools to solve tasks. However, to make such an agent viable for real-world deployment and accessible at scale, significant optimizations are required to ensure high efficiency and low cost. This paper presents a design of the Super Agent System. Upon receiving a user prompt, the system first detects the intent of the user, then routes the request to specialized task agents with the necessary tools or automatically generates agentic workflows. In practice, most applications directly serve as AI assistants on edge devices such as phones and robots. As different language models vary in capability and cloud-based models often entail high computational costs, latency, and privacy concerns, we then explore the hybrid mode where the router dynamically selects between local and cloud models based on task complexity. Finally, we introduce the blueprint of an on-device super agent enhanced with cloud. With advances in multi-modality models and edge hardware, we envision that most computations can be handled locally, with cloud collaboration only as needed. Such architecture paves the way for super agents to be seamlessly integrated into everyday life in the near future.
Protein Large Language Models: A Comprehensive Survey
Feb 21, 2025Protein-specific large language models (Protein LLMs) are revolutionizing protein science by enabling more efficient protein structure prediction, function annotation, and design. While existing surveys focus on specific aspects or applications, this work provides the first comprehensive overview of Protein LLMs, covering their architectures, training datasets, evaluation metrics, and diverse applications. Through a systematic analysis of over 100 articles, we propose a structured taxonomy of state-of-the-art Protein LLMs, analyze how they leverage large-scale protein sequence data for improved accuracy, and explore their potential in advancing protein engineering and biomedical research. Additionally, we discuss key challenges and future directions, positioning Protein LLMs as essential tools for scientific discovery in protein science. Resources are maintained at https://github.com/Yijia-Xiao/Protein-LLM-Survey.
Omni-Mol: Exploring Universal Convergent Space for Omni-Molecular Tasks
Feb 03, 2025



Building generalist models has recently demonstrated remarkable capabilities in diverse scientific domains. Within the realm of molecular learning, several studies have explored unifying diverse tasks across diverse domains. However, negative conflicts and interference between molecules and knowledge from different domain may have a worse impact in threefold. First, conflicting molecular representations can lead to optimization difficulties for the models. Second, mixing and scaling up training data across diverse tasks is inherently challenging. Third, the computational cost of refined pretraining is prohibitively high. To address these limitations, this paper presents Omni-Mol, a scalable and unified LLM-based framework for direct instruction tuning. Omni-Mol builds on three key components to tackles conflicts: (1) a unified encoding mechanism for any task input; (2) an active-learning-driven data selection strategy that significantly reduces dataset size; (3) a novel design of the adaptive gradient stabilization module and anchor-and-reconcile MoE framework that ensures stable convergence. Experimentally, Omni-Mol achieves state-of-the-art performance across 15 molecular tasks, demonstrates the presence of scaling laws in the molecular domain, and is supported by extensive ablation studies and analyses validating the effectiveness of its design. The code and weights of the powerful AI-driven chemistry generalist are open-sourced at: https://anonymous.4open.science/r/Omni-Mol-8EDB.
Graph Fourier Neural ODEs: Bridging Spatial and Temporal Multiscales in Molecular Dynamics
Nov 03, 2024



Molecular dynamics simulations are crucial for understanding complex physical, chemical, and biological processes at the atomic level. However, accurately capturing interactions across multiple spatial and temporal scales remains a significant challenge. We present a novel framework that jointly models spatial and temporal multiscale interactions in molecular dynamics. Our approach leverages Graph Fourier Transforms to decompose molecular structures into different spatial scales and employs Neural Ordinary Differential Equations to model the temporal dynamics in a curated manner influenced by the spatial modes. This unified framework links spatial structures with temporal evolution in a flexible manner, enabling more accurate and comprehensive simulations of molecular systems. We evaluate our model on the MD17 dataset, demonstrating consistent performance improvements over state-of-the-art baselines across multiple molecules, particularly under challenging conditions such as irregular timestep sampling and long-term prediction horizons. Ablation studies confirm the significant contributions of both spatial and temporal multiscale modeling components. Our method advances the simulation of complex molecular systems, potentially accelerating research in computational chemistry, drug discovery, and materials science.
Graph Masked Autoencoder for Spatio-Temporal Graph Learning
Oct 14, 2024Effective spatio-temporal prediction frameworks play a crucial role in urban sensing applications, including traffic analysis, human mobility behavior modeling, and citywide crime prediction. However, the presence of data noise and label sparsity in spatio-temporal data presents significant challenges for existing neural network models in learning effective and robust region representations. To address these challenges, we propose a novel spatio-temporal graph masked autoencoder paradigm that explores generative self-supervised learning for effective spatio-temporal data augmentation. Our proposed framework introduces a spatial-temporal heterogeneous graph neural encoder that captures region-wise dependencies from heterogeneous data sources, enabling the modeling of diverse spatial dependencies. In our spatio-temporal self-supervised learning paradigm, we incorporate a masked autoencoding mechanism on node representations and structures. This mechanism automatically distills heterogeneous spatio-temporal dependencies across regions over time, enhancing the learning process of dynamic region-wise spatial correlations. To validate the effectiveness of our STGMAE framework, we conduct extensive experiments on various spatio-temporal mining tasks. We compare our approach against state-of-the-art baselines. The results of these evaluations demonstrate the superiority of our proposed framework in terms of performance and its ability to address the challenges of spatial and temporal data noise and sparsity in practical urban sensing scenarios.
A Survey on Point-of-Interest Recommendation: Models, Architectures, and Security
Oct 03, 2024



The widespread adoption of smartphones and Location-Based Social Networks has led to a massive influx of spatio-temporal data, creating unparalleled opportunities for enhancing Point-of-Interest (POI) recommendation systems. These advanced POI systems are crucial for enriching user experiences, enabling personalized interactions, and optimizing decision-making processes in the digital landscape. However, existing surveys tend to focus on traditional approaches and few of them delve into cutting-edge developments, emerging architectures, as well as security considerations in POI recommendations. To address this gap, our survey stands out by offering a comprehensive, up-to-date review of POI recommendation systems, covering advancements in models, architectures, and security aspects. We systematically examine the transition from traditional models to advanced techniques such as large language models. Additionally, we explore the architectural evolution from centralized to decentralized and federated learning systems, highlighting the improvements in scalability and privacy. Furthermore, we address the increasing importance of security, examining potential vulnerabilities and privacy-preserving approaches. Our taxonomy provides a structured overview of the current state of POI recommendation, while we also identify promising directions for future research in this rapidly advancing field.