 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Distribution-assisted Evolutionary Dynamic Optimization as an Online Calibrator for Complex Social Simulations
Jan 27, 2026The calibration of simulators for complex social systems aims to identify the optimal parameter that drives the output of the simulator best matching the target data observed from the system. As many social systems may change internally over time, calibration naturally becomes an online task, requiring parameters to be updated continuously to maintain the simulator's fidelity. In this work, the online setting is first formulated as a dynamic optimization problem (DOP), requiring the search for a sequence of optimal parameters that fit the simulator to real system changes. However, in contrast to traditional DOP formulations, online calibration explicitly incorporates the observational data as the driver of environmental dynamics. Due to this fundamental difference, existing Evolutionary Dynamic Optimization (EDO) methods, despite being extensively studied for black-box DOPs, are ill-equipped to handle such a scenario. As a result, online calibration problems constitute a new set of challenging DOPs. Here, we propose to explicitly learn the posterior distributions of the parameters and the observational data, thereby facilitating both change detection and environmental adaptation of existing EDOs for this scenario. We thus present a pretrained posterior model for implementation, and fine-tune it during the optimization. Extensive tests on both economic and financial simulators verify that the posterior distribution strongly promotes EDOs in such DOPs widely existed in social science.
Enhancing Text-to-Image Generation via End-Edge Collaborative Hybrid Super-Resolution
Jan 21, 2026Artificial Intelligence-Generated Content (AIGC) has made significant strides, with high-resolution text-to-image (T2I) generation becoming increasingly critical for improving users' Quality of Experience (QoE). Although resource-constrained edge computing adequately supports fast low-resolution T2I generations, achieving high-resolution output still faces the challenge of ensuring image fidelity at the cost of latency. To address this, we first investigate the performance of super-resolution (SR) methods for image enhancement, confirming a fundamental trade-off that lightweight learning-based SR struggles to recover fine details, while diffusion-based SR achieves higher fidelity at a substantial computational cost. Motivated by these observations, we propose an end-edge collaborative generation-enhancement framework. Upon receiving a T2I generation task, the system first generates a low-resolution image based on adaptively selected denoising steps and super-resolution scales at the edge side, which is then partitioned into patches and processed by a region-aware hybrid SR policy. This policy applies a diffusion-based SR model to foreground patches for detail recovery and a lightweight learning-based SR model to background patches for efficient upscaling, ultimately stitching the enhanced ones into the high-resolution image. Experiments show that our system reduces service latency by 33% compared with baselines while maintaining competitive image quality.
SecMoE: Communication-Efficient Secure MoE Inference via Select-Then-Compute
Jan 11, 2026Privacy-preserving Transformer inference has gained attention due to the potential leakage of private information. Despite recent progress, existing frameworks still fall short of practical model scales, with gaps up to a hundredfold. A possible way to close this gap is the Mixture of Experts (MoE) architecture, which has emerged as a promising technique to scale up model capacity with minimal overhead. However, given that the current secure two-party (2-PC) protocols allow the server to homomorphically compute the FFN layer with its plaintext model weight, under the MoE setting, this could reveal which expert is activated to the server, exposing token-level privacy about the client's input. While naively evaluating all the experts before selection could protect privacy, it nullifies MoE sparsity and incurs the heavy computational overhead that sparse MoE seeks to avoid. To address the privacy and efficiency limitations above, we propose a 2-PC privacy-preserving inference framework, \SecMoE. Unifying per-entry circuits in both the MoE layer and piecewise polynomial functions, \SecMoE obliviously selects the extracted parameters from circuits and only computes one encrypted entry, which we refer to as Select-Then-Compute. This makes the model for private inference scale to 63$\times$ larger while only having a 15.2$\times$ increase in end-to-end runtime. Extensive experiments show that, under 5 expert settings, \SecMoE lowers the end-to-end private inference communication by 1.8$\sim$7.1$\times$ and achieves 1.3$\sim$3.8$\times$ speedup compared to the state-of-the-art (SOTA) protocols.
Calibrating Agent-Based Financial Markets Simulators with Pretrainable Automatic Posterior Transformation-Based Surrogates
Jan 11, 2026Calibrating Agent-Based Models (ABMs) is an important optimization problem for simulating the complex social systems, where the goal is to identify the optimal parameter of a given ABM by minimizing the discrepancy between the simulated data and the real-world observations. Unfortunately, it suffers from the extensive computational costs of iterative evaluations, which involves the expensive simulation with the candidate parameter. While Surrogate-Assisted Evolutionary Algorithms (SAEAs) have been widely adopted to alleviate the computational burden, existing methods face two key limitations: 1) surrogating the original evaluation function is hard due the nonlinear yet multi-modal nature of the ABMs, and 2) the commonly used surrogates cannot share the optimization experience among multiple calibration tasks, making the batched calibration less effective. To address these issues, this work proposes Automatic posterior transformation with Negatively Correlated Search and Adaptive Trust-Region (ANTR). ANTR first replaces the traditional surrogates with a pretrainable neural density estimator that directly models the posterior distribution of the parameters given observed data, thereby aligning the optimization objective with parameter-space accuracy. Furthermore, we incorporate a diversity-preserving search strategy to prevent premature convergence and an adaptive trust-region method to efficiently allocate computational resources. We take two representative ABM-based financial market simulators as the test bench as due to the high non-linearity. Experiments demonstrate that the proposed ANTR significantly outperforms conventional metaheuristics and state-of-the-art SAEAs in both calibration accuracy and computational efficiency, particularly in batch calibration scenarios across multiple market conditions.
Advanced Multimodal Learning for Seizure Detection and Prediction: Concept, Challenges, and Future Directions
Jan 08, 2026Epilepsy is a chronic neurological disorder characterized by recurrent unprovoked seizures, affects over 50 million people worldwide, and poses significant risks, including sudden unexpected death in epilepsy (SUDEP). Conventional unimodal approaches, primarily reliant on electroencephalography (EEG), face several key challenges, including low SNR, nonstationarity, inter- and intrapatient heterogeneity, portability, and real-time applicability in clinical settings. To address these issues, a comprehensive survey highlights the concept of advanced multimodal learning for epileptic seizure detection and prediction (AMLSDP). The survey presents the evolution of epileptic seizure detection (ESD) and prediction (ESP) technologies across different eras. The survey also explores the core challenges of multimodal and non-EEG-based ESD and ESP. To overcome the key challenges of the multimodal system, the survey introduces the advanced processing strategies for efficient AMLSDP. Furthermore, this survey highlights future directions for researchers and practitioners. We believe this work will advance neurotechnology toward wearable and imaging-based solutions for epilepsy monitoring, serving as a valuable resource for future innovations in this domain.
Step-Audio-EditX Technical Report
Nov 05, 2025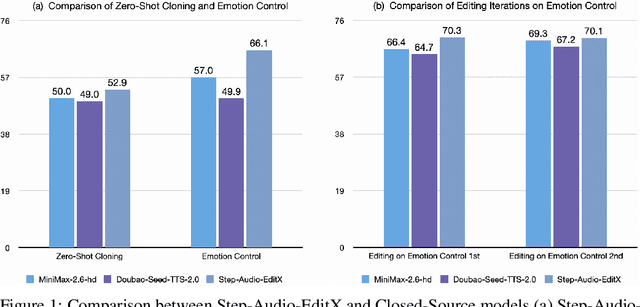
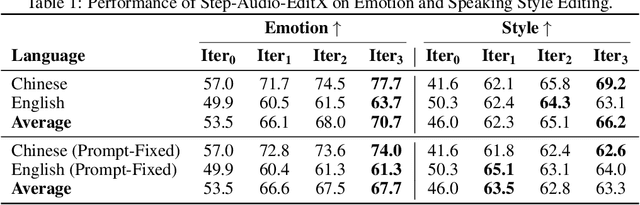

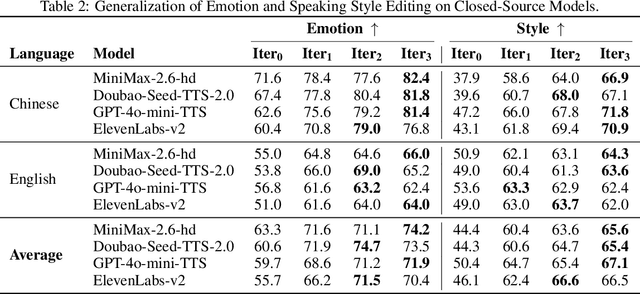
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Learning Unified Representations from Heterogeneous Data for Robust Heart Rate Modeling
Aug 29, 2025Heart rate prediction is vital for personalized health monitoring and fitness, while it frequently faces a critical challenge when deploying in real-world: data heterogeneity. We classify it in two key dimensions: source heterogeneity from fragmented device markets with varying feature sets, and user heterogeneity reflecting distinct physiological patterns across individuals and activities. Existing methods either discard device-specific information, or fail to model user-specific differences, limiting their real-world performance. To address this, we propose a framework that learns latent representations agnostic to both heterogeneity, enabling downstream predictors to work consistently under heterogeneous data patterns. Specifically, we introduce a random feature dropout strategy to handle source heterogeneity, making the model robust to various feature sets. To manage user heterogeneity, we employ a time-aware attention module to capture long-term physiological traits and use a contrastive learning objective to build a discriminative representation space. To reflect the heterogeneous nature of real-world data, we created and publicly released a new benchmark dataset, ParroTao. Evaluations on both ParroTao and the public FitRec dataset show that our model significantly outperforms existing baselines by 17% and 15%, respectively. Furthermore, analysis of the learned representations demonstrates their strong discriminative power, and one downstream application task confirm the practical value of our model.
A Decoupled LOB Representation Framework for Multilevel Manipulation Detection with Supervised Contrastive Learning
Aug 23, 2025Financial markets are critical to global economic stability, yet trade-based manipulation (TBM) often undermines their fairness. Spoofing, a particularly deceptive TBM strategy, exhibits multilevel anomaly patterns that have not been adequately modeled. These patterns are usually concealed within the rich, hierarchical information of the Limit Order Book (LOB), which is challenging to leverage due to high dimensionality and noise. To address this, we propose a representation learning framework combining a cascaded LOB representation pipeline with supervised contrastive learning. Extensive experiments demonstrate that our framework consistently improves detection performance across diverse models, with Transformer-based architectures achieving state-of-the-art results. In addition, we conduct systematic analyses and ablation studies to investigate multilevel anomalies and the contributions of key components, offering broader insights into representation learning and anomaly detection for complex sequential data. Our code will be released later at this URL.
QoE-Aware Service Provision for Mobile AR Rendering: An Agent-Driven Approach
Aug 12, 2025Mobile augmented reality (MAR) is envisioned as a key immersive application in 6G, enabling virtual content rendering aligned with the physical environment through device pose estimation. In this paper, we propose a novel agent-driven communication service provisioning approach for edge-assisted MAR, aiming to reduce communication overhead between MAR devices and the edge server while ensuring the quality of experience (QoE). First, to address the inaccessibility of MAR application-specific information to the network controller, we establish a digital agent powered by large language models (LLMs) on behalf of the MAR service provider, bridging the data and function gap between the MAR service and network domains. Second, to cope with the user-dependent and dynamic nature of data traffic patterns for individual devices, we develop a user-level QoE modeling method that captures the relationship between communication resource demands and perceived user QoE, enabling personalized, agent-driven communication resource management. Trace-driven simulation results demonstrate that the proposed approach outperforms conventional LLM-based QoE-aware service provisioning methods in both user-level QoE modeling accuracy and communication resource efficiency.
Learning from Expert Factors: Trajectory-level Reward Shaping for Formulaic Alpha Mining
Jul 27, 2025
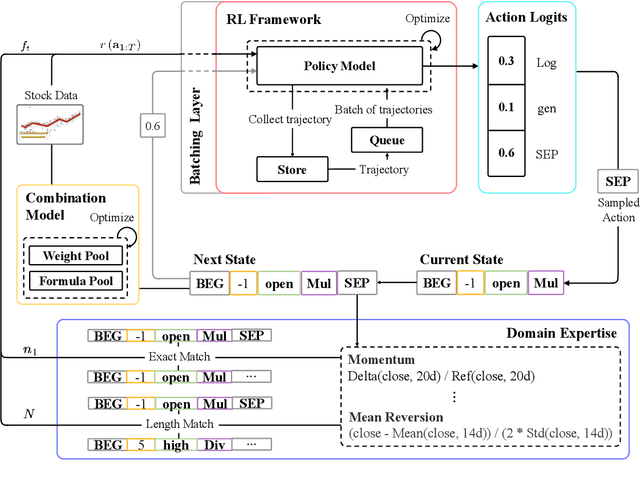
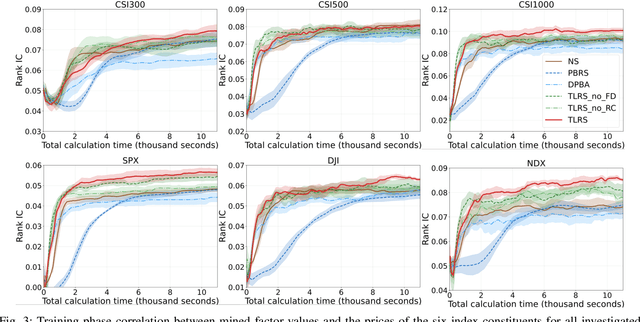
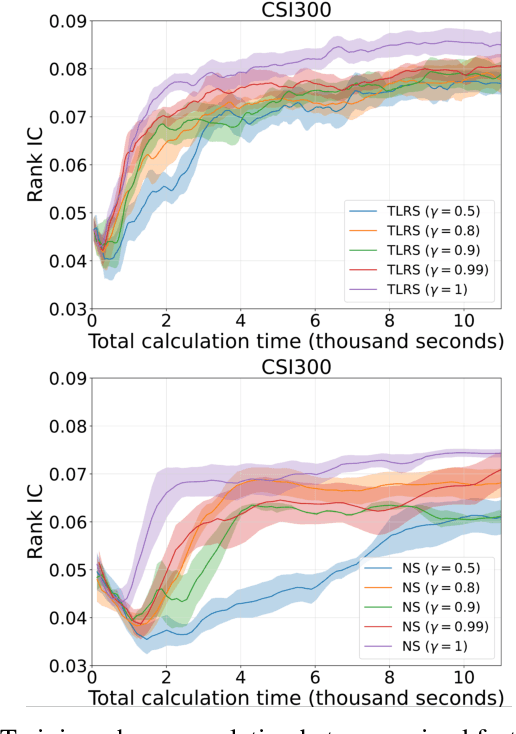
Reinforcement learning (RL) has successfully automated the complex process of mining formulaic alpha factors, for creating interpretable and profitable investment strategies. However, existing methods are hampered by the sparse rewards given the underlying Markov Decision Process. This inefficiency limits the exploration of the vast symbolic search space and destabilizes the training process. To address this, Trajectory-level Reward Shaping (TLRS), a novel reward shaping method, is proposed. TLRS provides dense, intermediate rewards by measuring the subsequence-level similarity between partially generated expressions and a set of expert-designed formulas. Furthermore, a reward centering mechanism is introduced to reduce training variance. Extensive experiments on six major Chinese and U.S. stock indices show that TLRS significantly improves the predictive power of mined factors, boosting the Rank Information Coefficient by 9.29% over existing potential-based shaping algorithms. Notably, TLRS achieves a major leap in computational efficiency by reducing its time complexity with respect to the feature dimension from linear to constant, which is a significant improvement over distance-based baselines.