 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-Aware DNN Compression for Homogeneous Edge Devices
Jan 25, 2025



Deploying deep neural networks (DNNs) across homogeneous edge devices (the devices with the same SKU labeled by the manufacturer) often assumes identical performance among them. However, once a device model is widely deployed, the performance of each device becomes different after a period of running. This is caused by the differences in user configurations, environmental conditions, manufacturing variances, battery degradation, etc. Existing DNN compression methods have not taken this scenario into consideration and can not guarantee good compression results in all homogeneous edge devices. To address this, we propose Homogeneous-Device Aware Pruning (HDAP), a hardware-aware DNN compression framework explicitly designed for homogeneous edge devices, aiming to achieve optimal average performance of the compressed model across all devices. To deal with the difficulty of time-consuming hardware-aware evaluations for thousands or millions of homogeneous edge devices, HDAP partitions all the devices into several device clusters, which can dramatically reduce the number of devices to evaluate and use the surrogate-based evaluation instead of hardware evaluation in real-time. Experiments on ResNet50 and MobileNetV1 with the ImageNet dataset show that HDAP consistently achieves lower average inference latency compared with state-of-the-art methods, with substantial speedup gains (e.g., 2.86 $\times$ speedup at 1.0G FLOPs for ResNet50) on the homogeneous device clusters. HDAP offers an effective solution for scalable, high-performance DNN deployment methods for homogeneous edge devices.
Zero-shot Dynamic MRI Reconstruction with Global-to-local Diffusion Model
Nov 06, 2024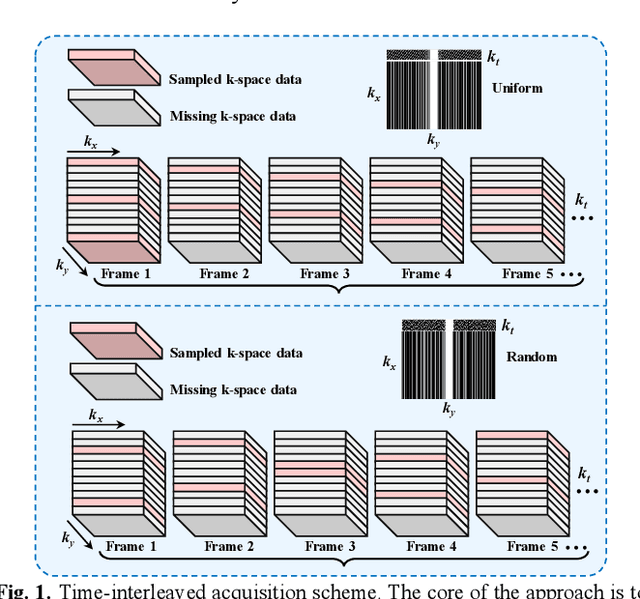
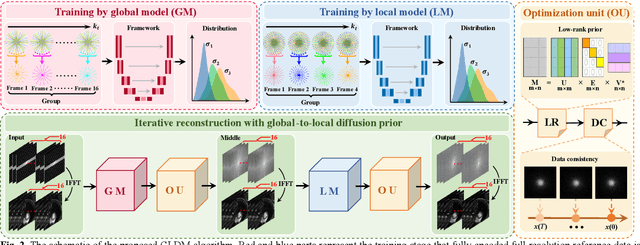
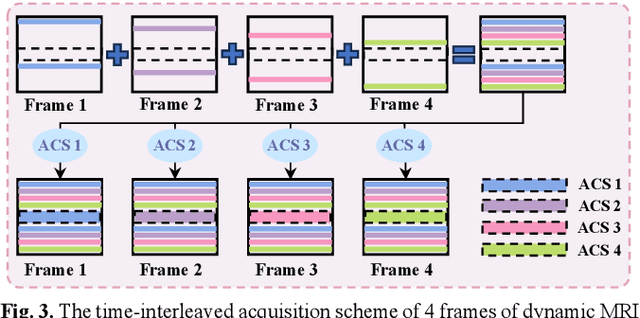
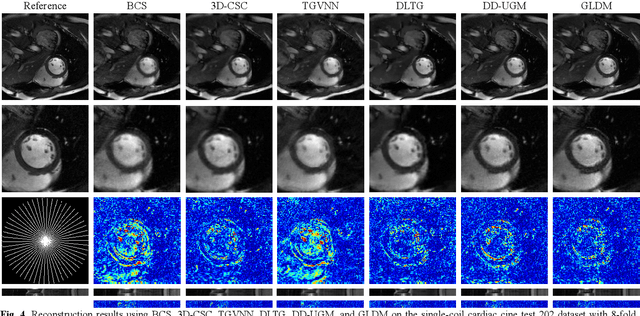
Diffusion models have recently demonstrated considerable advancement in the generation and reconstruction of magnetic resonance imaging (MRI) data. These models exhibit great potential in handling unsampled data and reducing noise, highlighting their promise as generative models. However, their application in dynamic MRI remains relatively underexplored. This is primarily due to the substantial amount of fully-sampled data typically required for training, which is difficult to obtain in dynamic MRI due to its spatio-temporal complexity and high acquisition costs. To address this challenge, we propose a dynamic MRI reconstruction method based on a time-interleaved acquisition scheme, termed the Glob-al-to-local Diffusion Model. Specifically, fully encoded full-resolution reference data are constructed by merging under-sampled k-space data from adjacent time frames, generating two distinct bulk training datasets for global and local models. The global-to-local diffusion framework alternately optimizes global information and local image details, enabling zero-shot reconstruction. Extensive experiments demonstrate that the proposed method performs well in terms of noise reduction and detail preservation, achieving reconstruction quality comparable to that of supervised approaches.