 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOUT: Fast Spectral CT Imaging in Ultra LOw-data Regimes via PseUdo-label GeneraTion
Feb 28, 2026Noise and artifacts during computed tomography (CT) scans are a fundamental challenge affecting disease diagnosis. However, current methods either involve excessively long reconstruction times or rely on data-driven models for optimization, failing to adequately consider the valuable information inherent in the data itself, especially medical 3D data. This work proposes a reconstruction method under ultra-low raw data conditions, requiring no external data and avoiding lengthy pre-training processes. By leveraging spatial nonlocal similarity and the conjugate properties of the projection domain to generate pseudo-3D data for self-supervised training, high-fidelity results can be achieved in a very short time. Extensive experiments demonstrate that this method not only mitigates detector-induced ring artifacts but also exhibits unprecedented capabilities in detail recovery. This method provides a new paradigm for research using unlabeled raw projection data. Code is available at https://github.com/yqx7150/SCOUT.
Continuity-driven Synergistic Diffusion with Neural Priors for Ultra-Sparse-View CBCT Reconstruction
Feb 08, 2026The clinical application of cone-beam computed tomography (CBCT) is constrained by the inherent trade-off between radiation exposure and image quality. Ultra-sparse angular sampling, employed to reduce dose, introduces severe undersampling artifacts and inter-slice inconsistencies, compromising diagnostic reliability. Existing reconstruction methods often struggle to balance angular continuity with spatial detail fidelity. To address these challenges, we propose a Continuity-driven Synergistic Diffusion with Neural priors (CSDN) for ultra-sparse-view CBCT reconstruction. Neural priors are introduced as a structural foundation to encode a continuous threedimensional attenuation representation, enabling the synthesis of physically consistent dense projections from ultra-sparse measurements. Building upon this neural-prior-based initialization, a synergistic diffusion strategy is developed, consisting of two collaborative refinement paths: a Sinogram Refinement Diffusion (Sino-RD) process that restores angular continuity and a Digital Radiography Refinement Diffusion (DR-RD) process that enforces inter-slice consistency from the projection image perspective. The outputs of the two diffusion paths are adaptively fused by the Dual-Projection Reconstruction Fusion (DPRF) module to achieve coherent volumetric reconstruction. Extensive experiments demonstrate that the proposed CSDN effectively suppresses artifacts and recovers fine textures under ultra-sparse-view conditions, outperforming existing state-of-the-art techniques.
FSP-Diff: Full-Spectrum Prior-Enhanced DualDomain Latent Diffusion for Ultra-Low-Dose Spectral CT Reconstruction
Feb 08, 2026Spectral computed tomography (CT) with photon-counting detectors holds immense potential for material discrimination and tissue characterization. However, under ultra-low-dose conditions, the sharply degraded signal-to-noise ratio (SNR) in energy-specific projections poses a significant challenge, leading to severe artifacts and loss of structural details in reconstructed images. To address this, we propose FSP-Diff, a full-spectrum prior-enhanced dual-domain latent diffusion framework for ultra-low-dose spectral CT reconstruction. Our framework integrates three core strategies: 1) Complementary Feature Construction: We integrate direct image reconstructions with projection-domain denoised results. While the former preserves latent textural nuances amidst heavy noise, the latter provides a stable structural scaffold to balance detail fidelity and noise suppression. 2) Full-Spectrum Prior Integration: By fusing multi-energy projections into a high-SNR full-spectrum image, we establish a unified structural reference that guides the reconstruction across all energy bins. 3) Efficient Latent Diffusion Synthesis: To alleviate the high computational burden of high-dimensional spectral data, multi-path features are embedded into a compact latent space. This allows the diffusion process to facilitate interactive feature fusion in a lower-dimensional manifold, achieving accelerated reconstruction while maintaining fine-grained detail restoration. Extensive experiments on simulated and real-world datasets demonstrate that FSP-Diff significantly outperforms state-of-the-art methods in both image quality and computational efficiency, underscoring its potential for clinically viable ultra-low-dose spectral CT imaging.
Structure-constrained Language-informed Diffusion Model for Unpaired Low-dose Computed Tomography Angiography Reconstruction
Jan 28, 2026The application of iodinated contrast media (ICM) improves the sensitivity and specificity of computed tomography (CT) for a wide range of clinical indications. However, overdose of ICM can cause problems such as kidney damage and life-threatening allergic reactions. Deep learning methods can generate CT images of normal-dose ICM from low-dose ICM, reducing the required dose while maintaining diagnostic power. However, existing methods are difficult to realize accurate enhancement with incompletely paired images, mainly because of the limited ability of the model to recognize specific structures. To overcome this limitation, we propose a Structure-constrained Language-informed Diffusion Model (SLDM), a unified medical generation model that integrates structural synergy and spatial intelligence. First, the structural prior information of the image is effectively extracted to constrain the model inference process, thus ensuring structural consistency in the enhancement process. Subsequently, semantic supervision strategy with spatial intelligence is introduced, which integrates the functions of visual perception and spatial reasoning, thus prompting the model to achieve accurate enhancement. Finally, the subtraction angiography enhancement module is applied, which serves to improve the contrast of the ICM agent region to suitable interval for observation. Qualitative analysis of visual comparison and quantitative results of several metrics demonstrate the effectiveness of our method in angiographic reconstruction for low-dose contrast medium CT angiography.
Incremental Maintenance of DatalogMTL Materialisations
Nov 19, 2025DatalogMTL extends the classical Datalog language with metric temporal logic (MTL), enabling expressive reasoning over temporal data. While existing reasoning approaches, such as materialisation based and automata based methods, offer soundness and completeness, they lack support for handling efficient dynamic updates, a crucial requirement for real-world applications that involve frequent data updates. In this work, we propose DRedMTL, an incremental reasoning algorithm for DatalogMTL with bounded intervals. Our algorithm builds upon the classical DRed algorithm, which incrementally updates the materialisation of a Datalog program. Unlike a Datalog materialisation which is in essence a finite set of facts, a DatalogMTL materialisation has to be represented as a finite set of facts plus periodic intervals indicating how the full materialisation can be constructed through unfolding. To cope with this, our algorithm is equipped with specifically designed operators to efficiently handle such periodic representations of DatalogMTL materialisations. We have implemented this approach and tested it on several publicly available datasets. Experimental results show that DRedMTL often significantly outperforms rematerialisation, sometimes by orders of magnitude.
Iterative Diffusion-Refined Neural Attenuation Fields for Multi-Source Stationary CT Reconstruction: NAF Meets Diffusion Model
Nov 18, 2025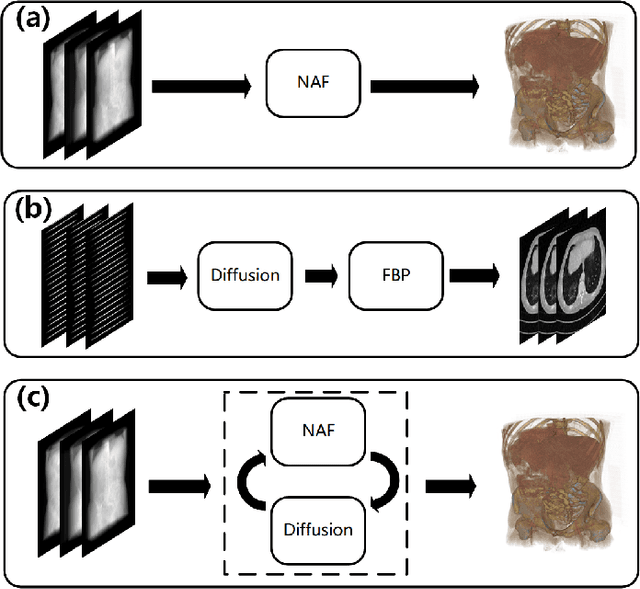
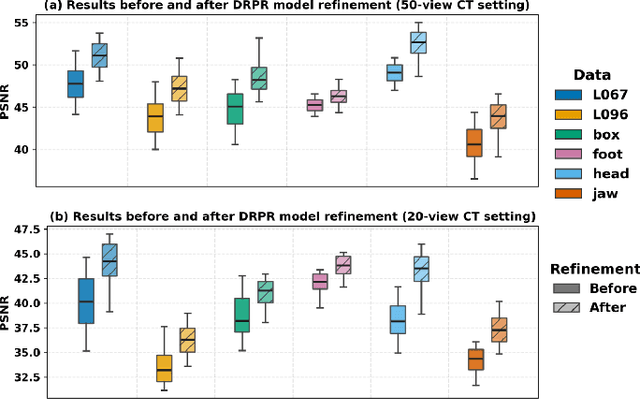
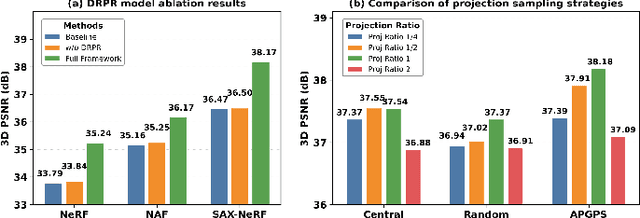
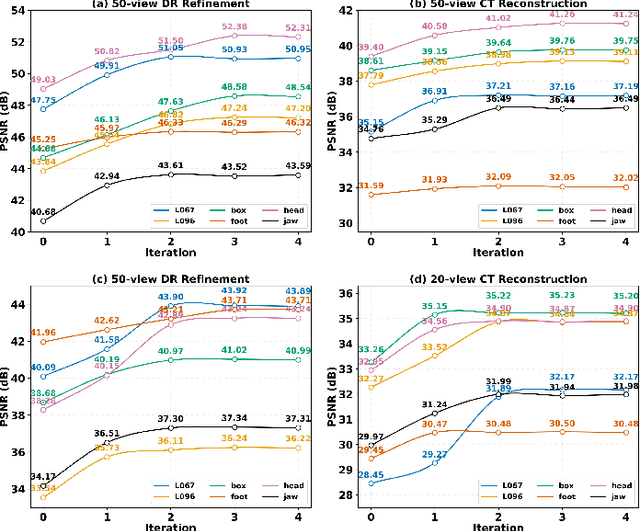
Multi-source stationary computed tomography (CT) has recently attracted attention for its ability to achieve rapid image reconstruction, making it suitable for time-sensitive clinical and industrial applications. However, practical systems are often constrained by ultra-sparse-view sampling, which significantly degrades reconstruction quality. Traditional methods struggle under ultra-sparse-view settings, where interpolation becomes inaccurate and the resulting reconstructions are unsatisfactory. To address this challenge, this study proposes Diffusion-Refined Neural Attenuation Fields (Diff-NAF), an iterative framework tailored for multi-source stationary CT under ultra-sparse-view conditions. Diff-NAF combines a Neural Attenuation Field representation with a dual-branch conditional diffusion model. The process begins by training an initial NAF using ultra-sparse-view projections. New projections are then generated through an Angle-Prior Guided Projection Synthesis strategy that exploits inter view priors, and are subsequently refined by a Diffusion-driven Reuse Projection Refinement Module. The refined projections are incorporated as pseudo-labels into the training set for the next iteration. Through iterative refinement, Diff-NAF progressively enhances projection completeness and reconstruction fidelity under ultra-sparse-view conditions, ultimately yielding high-quality CT reconstructions. Experimental results on multiple simulated 3D CT volumes and real projection data demonstrate that Diff-NAF achieves the best performance under ultra-sparse-view conditions.
UniSino: Physics-Driven Foundational Model for Universal CT Sinogram Standardization
Aug 25, 2025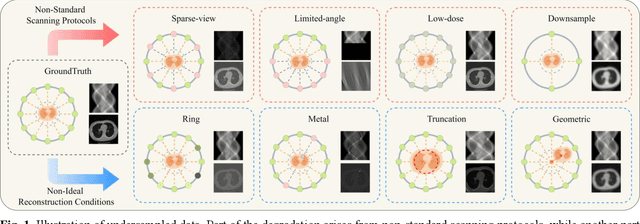
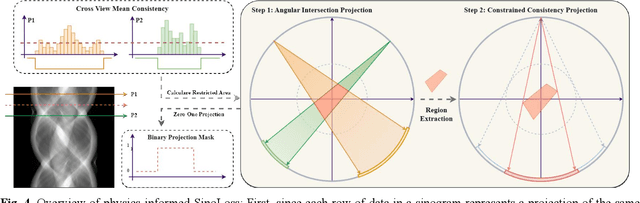
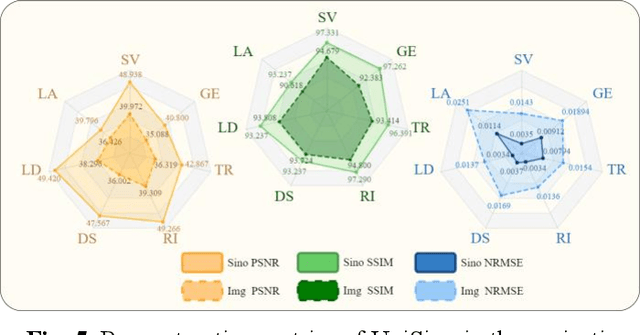
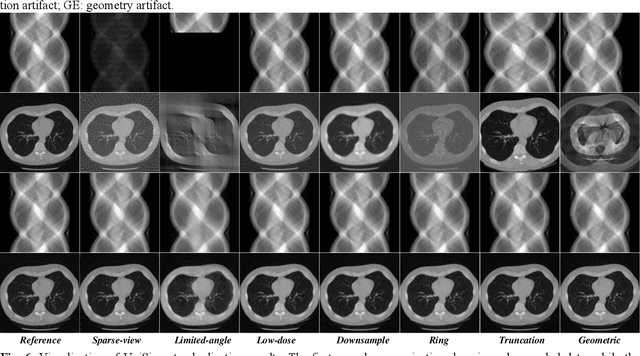
During raw-data acquisition in CT imaging, diverse factors can degrade the collected sinograms, with undersampling and noise leading to severe artifacts and noise in reconstructed images and compromising diagnostic accuracy. Conventional correction methods rely on manually designed algorithms or fixed empirical parameters, but these approaches often lack generalizability across heterogeneous artifact types. To address these limitations, we propose UniSino, a foundation model for universal CT sinogram standardization. Unlike existing foundational models that operate in image domain, UniSino directly standardizes data in the projection domain, which enables stronger generalization across diverse undersampling scenarios. Its training framework incorporates the physical characteristics of sinograms, enhancing generalization and enabling robust performance across multiple subtasks spanning four benchmark datasets. Experimental results demonstrate thatUniSino achieves superior reconstruction quality both single and mixed undersampling case, demonstrating exceptional robustness and generalization in sinogram enhancement for CT imaging. The code is available at: https://github.com/yqx7150/UniSino.
Ordered-subsets Multi-diffusion Model for Sparse-view CT Reconstruction
May 15, 2025Score-based diffusion models have shown significant promise in the field of sparse-view CT reconstruction. However, the projection dataset is large and riddled with redundancy. Consequently, applying the diffusion model to unprocessed data results in lower learning effectiveness and higher learning difficulty, frequently leading to reconstructed images that lack fine details. To address these issues, we propose the ordered-subsets multi-diffusion model (OSMM) for sparse-view CT reconstruction. The OSMM innovatively divides the CT projection data into equal subsets and employs multi-subsets diffusion model (MSDM) to learn from each subset independently. This targeted learning approach reduces complexity and enhances the reconstruction of fine details. Furthermore, the integration of one-whole diffusion model (OWDM) with complete sinogram data acts as a global information constraint, which can reduce the possibility of generating erroneous or inconsistent sinogram information. Moreover, the OSMM's unsupervised learning framework provides strong robustness and generalizability, adapting seamlessly to varying sparsity levels of CT sinograms. This ensures consistent and reliable performance across different clinical scenarios. Experimental results demonstrate that OSMM outperforms traditional diffusion models in terms of image quality and noise resilience, offering a powerful and versatile solution for advanced CT imaging in sparse-view scenarios.
Virtual-mask Informed Prior for Sparse-view Dual-Energy CT Reconstruction
Apr 10, 2025Sparse-view sampling in dual-energy computed tomography (DECT) significantly reduces radiation dose and increases imaging speed, yet is highly prone to artifacts. Although diffusion models have demonstrated potential in effectively handling incomplete data, most existing methods in this field focus on the image do-main and lack global constraints, which consequently leads to insufficient reconstruction quality. In this study, we propose a dual-domain virtual-mask in-formed diffusion model for sparse-view reconstruction by leveraging the high inter-channel correlation in DECT. Specifically, the study designs a virtual mask and applies it to the high-energy and low-energy data to perform perturbation operations, thus constructing high-dimensional tensors that serve as the prior information of the diffusion model. In addition, a dual-domain collaboration strategy is adopted to integrate the information of the randomly selected high-frequency components in the wavelet domain with the information in the projection domain, for the purpose of optimizing the global struc-tures and local details. Experimental results indicated that the present method exhibits excellent performance across multiple datasets.
HyperFree: A Channel-adaptive and Tuning-free Foundation Model for Hyperspectral Remote Sensing Imagery
Mar 27, 2025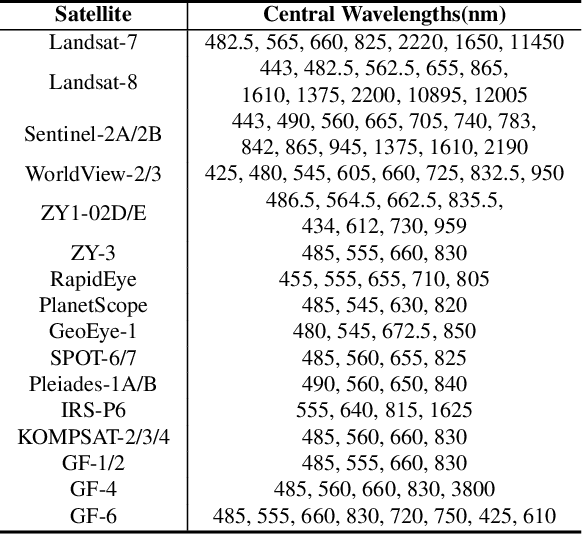
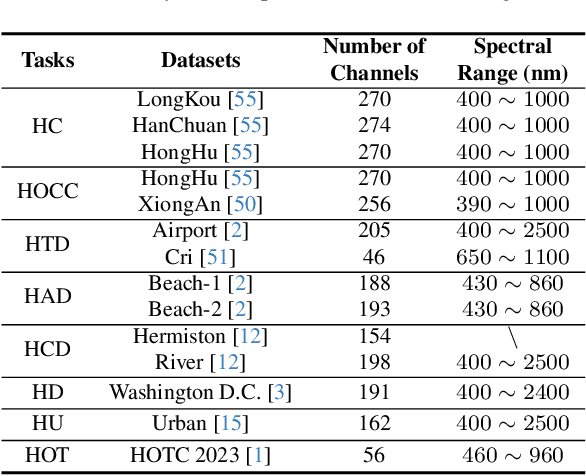
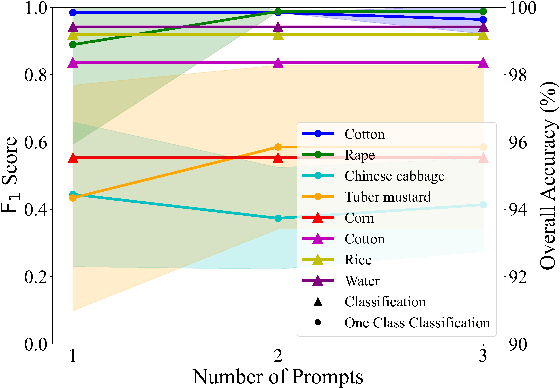
Advanced interpretation of hyperspectral remote sensing images benefits many precise Earth observation tasks. Recently, visual foundation models have promoted the remote sensing interpretation but concentrating on RGB and multispectral images. Due to the varied hyperspectral channels,existing foundation models would face image-by-image tuning situation, imposing great pressure on hardware and time resources. In this paper, we propose a tuning-free hyperspectral foundation model called HyperFree, by adapting the existing visual prompt engineering. To process varied channel numbers, we design a learned weight dictionary covering full-spectrum from $0.4 \sim 2.5 \, \mu\text{m}$, supporting to build the embedding layer dynamically. To make the prompt design more tractable, HyperFree can generate multiple semantic-aware masks for one prompt by treating feature distance as semantic-similarity. After pre-training HyperFree on constructed large-scale high-resolution hyperspectral images, HyperFree (1 prompt) has shown comparable results with specialized models (5 shots) on 5 tasks and 11 datasets.Code and dataset are accessible at https://rsidea.whu.edu.cn/hyperfree.htm.