 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODESTRUCT: Code Agents over Structured Action Spaces
Apr 07, 2026LLM-based code agents treat repositories as unstructured text, applying edits through brittle string matching that frequently fails due to formatting drift or ambiguous patterns. We propose reframing the codebase as a structured action space where agents operate on named AST entities rather than text spans. Our framework, CODESTRUCT, provides readCode for retrieving complete syntactic units and editCode for applying syntax-validated transformations to semantic program elements. Evaluated on SWE-Bench Verified across six LLMs, CODESTRUCT improves Pass@1 accuracy by 1.2-5.0% while reducing token consumption by 12-38% for most models. Models that frequently fail to produce valid patches under text-based interfaces benefit most: GPT-5-nano improves by 20.8% as empty-patch failures drop from 46.6% to 7.2%. On CodeAssistBench, we observe consistent accuracy gains (+0.8-4.4%) with cost reductions up to 33%. Our results show that structure-aware interfaces offer a more reliable foundation for code agents.
TRAJEVAL: Decomposing Code Agent Trajectories for Fine-Grained Diagnosis
Mar 25, 2026Code agents can autonomously resolve GitHub issues, yet when they fail, current evaluation provides no visibility into where or why. Metrics such as Pass@1 collapse an entire execution into a single binary outcome, making it difficult to identify where and why the agent went wrong. To address this limitation, we introduce TRAJEVAL, a diagnostic framework that decomposes agent trajectories into three interpretable stages: search (file localization), read (function comprehension), and edit (modification targeting). For each stage, we compute precision and recall by comparing against reference patches. Analyzing 16,758 trajectories across three agent architectures and seven models, we find universal inefficiencies (all agents examine approximately 22x more functions than necessary) yet distinct failure modes: GPT-5 locates relevant code but targets edits incorrectly, while Qwen-32B fails at file discovery entirely. We validate that these diagnostics are predictive, achieving model-level Pass@1 prediction within 0.87-2.1% MAE, and actionable: real-time feedback based on trajectory signals improves two state-of-the-art models by 2.2-4.6 percentage points while reducing costs by 20-31%. These results demonstrate that our framework not only provides a more fine-grained analysis of agent behavior, but also translates diagnostic signals into tangible performance gains. More broadly, TRAJEVAL transforms agent evaluation beyond outcome-based benchmarking toward mechanism-driven diagnosis of agent success and failure.
Train Less, Learn More: Adaptive Efficient Rollout Optimization for Group-Based Reinforcement Learning
Feb 15, 2026Reinforcement learning (RL) plays a central role in large language model (LLM) post-training. Among existing approaches, Group Relative Policy Optimization (GRPO) is widely used, especially for RL with verifiable rewards (RLVR) fine-tuning. In GRPO, each query prompts the LLM to generate a group of rollouts with a fixed group size $N$. When all rollouts in a group share the same outcome, either all correct or all incorrect, the group-normalized advantages become zero, yielding no gradient signal and wasting fine-tuning compute. We introduce Adaptive Efficient Rollout Optimization (AERO), an enhancement of GRPO. AERO uses an adaptive rollout strategy, applies selective rejection to strategically prune rollouts, and maintains a Bayesian posterior to prevent zero-advantage dead zones. Across three model configurations (Qwen2.5-Math-1.5B, Qwen2.5-7B, and Qwen2.5-7B-Instruct), AERO improves compute efficiency without sacrificing performance. Under the same total rollout budget, AERO reduces total training compute by about 48% while shortening wall-clock time per step by about 45% on average. Despite the substantial reduction in compute, AERO matches or improves Pass@8 and Avg@8 over GRPO, demonstrating a practical, scalable, and compute-efficient strategy for RL-based LLM alignment.
Retrieval Augmented Question Answering: When Should LLMs Admit Ignorance?
Dec 29, 2025The success of expanded context windows in Large Language Models (LLMs) has driven increased use of broader context in retrieval-augmented generation. We investigate the use of LLMs for retrieval augmented question answering. While longer contexts make it easier to incorporate targeted knowledge, they introduce more irrelevant information that hinders the model's generation process and degrades its performance. To address the issue, we design an adaptive prompting strategy which involves splitting the retrieved information into smaller chunks and sequentially prompting a LLM to answer the question using each chunk. Adjusting the chunk size allows a trade-off between incorporating relevant information and reducing irrelevant information. Experimental results on three open-domain question answering datasets demonstrate that the adaptive strategy matches the performance of standard prompting while using fewer tokens. Our analysis reveals that when encountering insufficient information, the LLM often generates incorrect answers instead of declining to respond, which constitutes a major source of error. This finding highlights the need for further research into enhancing LLMs' ability to effectively decline requests when faced with inadequate information.
CRABS: A syntactic-semantic pincer strategy for bounding LLM interpretation of Python notebooks
Jul 15, 2025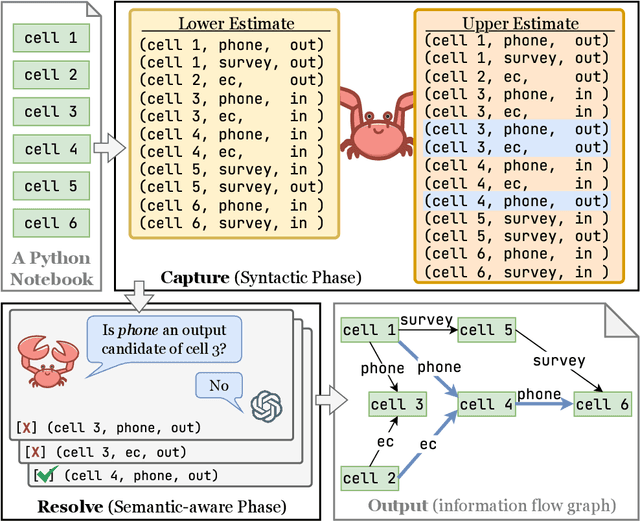



Recognizing the information flows and operations comprising data science and machine learning Python notebooks is critical for evaluating, reusing, and adapting notebooks for new tasks. Investigating a notebook via re-execution often is impractical due to the challenges of resolving data and software dependencies. While Large Language Models (LLMs) pre-trained on large codebases have demonstrated effectiveness in understanding code without running it, we observe that they fail to understand some realistic notebooks due to hallucinations and long-context challenges. To address these issues, we propose a notebook understanding task yielding an information flow graph and corresponding cell execution dependency graph for a notebook, and demonstrate the effectiveness of a pincer strategy that uses limited syntactic analysis to assist full comprehension of the notebook using an LLM. Our Capture and Resolve Assisted Bounding Strategy (CRABS) employs shallow syntactic parsing and analysis of the abstract syntax tree (AST) to capture the correct interpretation of a notebook between lower and upper estimates of the inter-cell I/O sets, then uses an LLM to resolve remaining ambiguities via cell-by-cell zero-shot learning, thereby identifying the true data inputs and outputs of each cell. We evaluate and demonstrate the effectiveness of our approach using an annotated dataset of 50 representative, highly up-voted Kaggle notebooks that together represent 3454 actual cell inputs and outputs. The LLM correctly resolves 1397 of 1425 (98%) ambiguities left by analyzing the syntactic structure of these notebooks. Across 50 notebooks, CRABS achieves average F1 scores of 98% identifying cell-to-cell information flows and 99% identifying transitive cell execution dependencies.
C-3PO: Compact Plug-and-Play Proxy Optimization to Achieve Human-like Retrieval-Augmented Generation
Feb 10, 2025



Retrieval-augmented generation (RAG) systems face a fundamental challenge in aligning independently developed retrievers and large language models (LLMs). Existing approaches typically involve modifying either component or introducing simple intermediate modules, resulting in practical limitations and sub-optimal performance. Inspired by human search behavior -- typically involving a back-and-forth process of proposing search queries and reviewing documents, we propose C-3PO, a proxy-centric framework that facilitates communication between retrievers and LLMs through a lightweight multi-agent system. Our framework implements three specialized agents that collaboratively optimize the entire RAG pipeline without altering the retriever and LLMs. These agents work together to assess the need for retrieval, generate effective queries, and select information suitable for the LLMs. To enable effective multi-agent coordination, we develop a tree-structured rollout approach for reward credit assignment in reinforcement learning. Extensive experiments in both in-domain and out-of-distribution scenarios demonstrate that C-3PO significantly enhances RAG performance while maintaining plug-and-play flexibility and superior generalization capabilities.
Goal-Driven Reasoning in DatalogMTL with Magic Sets
Dec 10, 2024

DatalogMTL is a powerful rule-based language for temporal reasoning. Due to its high expressive power and flexible modeling capabilities, it is suitable for a wide range of applications, including tasks from industrial and financial sectors. However, due its high computational complexity, practical reasoning in DatalogMTL is highly challenging. To address this difficulty, we introduce a new reasoning method for DatalogMTL which exploits the magic sets technique -- a rewriting approach developed for (non-temporal) Datalog to simulate top-down evaluation with bottom-up reasoning. We implement this approach and evaluate it on several publicly available benchmarks, showing that the proposed approach significantly and consistently outperforms performance of the state-of-the-art reasoning techniques.
Contextual Distillation Model for Diversified Recommendation
Jun 13, 2024



The diversity of recommendation is equally crucial as accuracy in improving user experience. Existing studies, e.g., Determinantal Point Process (DPP) and Maximal Marginal Relevance (MMR), employ a greedy paradigm to iteratively select items that optimize both accuracy and diversity. However, prior methods typically exhibit quadratic complexity, limiting their applications to the re-ranking stage and are not applicable to other recommendation stages with a larger pool of candidate items, such as the pre-ranking and ranking stages. In this paper, we propose Contextual Distillation Model (CDM), an efficient recommendation model that addresses diversification, suitable for the deployment in all stages of industrial recommendation pipelines. Specifically, CDM utilizes the candidate items in the same user request as context to enhance the diversification of the results. We propose a contrastive context encoder that employs attention mechanisms to model both positive and negative contexts. For the training of CDM, we compare each target item with its context embedding and utilize the knowledge distillation framework to learn the win probability of each target item under the MMR algorithm, where the teacher is derived from MMR outputs. During inference, ranking is performed through a linear combination of the recommendation and student model scores, ensuring both diversity and efficiency. We perform offline evaluations on two industrial datasets and conduct online A/B test of CDM on the short-video platform KuaiShou. The considerable enhancements observed in both recommendation quality and diversity, as shown by metrics, provide strong superiority for the effectiveness of CDM.
Calibrate and Boost Logical Expressiveness of GNN Over Multi-Relational and Temporal Graphs
Nov 03, 2023



As a powerful framework for graph representation learning, Graph Neural Networks (GNNs) have garnered significant attention in recent years. However, to the best of our knowledge, there has been no formal analysis of the logical expressiveness of GNNs as Boolean node classifiers over multi-relational graphs, where each edge carries a specific relation type. In this paper, we investigate $\mathcal{FOC}_2$, a fragment of first-order logic with two variables and counting quantifiers. On the negative side, we demonstrate that the R$^2$-GNN architecture, which extends the local message passing GNN by incorporating global readout, fails to capture $\mathcal{FOC}_2$ classifiers in the general case. Nevertheless, on the positive side, we establish that R$^2$-GNNs models are equivalent to $\mathcal{FOC}_2$ classifiers under certain restricted yet reasonable scenarios. To address the limitations of R$^2$-GNNs regarding expressiveness, we propose a simple graph transformation technique, akin to a preprocessing step, which can be executed in linear time. This transformation enables R$^2$-GNNs to effectively capture any $\mathcal{FOC}_2$ classifiers when applied to the "transformed" input graph. Moreover, we extend our analysis of expressiveness and graph transformation to temporal graphs, exploring several temporal GNN architectures and providing an expressiveness hierarchy for them. To validate our findings, we implement R$^2$-GNNs and the graph transformation technique and conduct empirical tests in node classification tasks against various well-known GNN architectures that support multi-relational or temporal graphs. Our experimental results consistently demonstrate that R$^2$-GNN with the graph transformation outperforms the baseline methods on both synthetic and real-world datasets
Seminaive Materialisation in DatalogMTL
Aug 15, 2022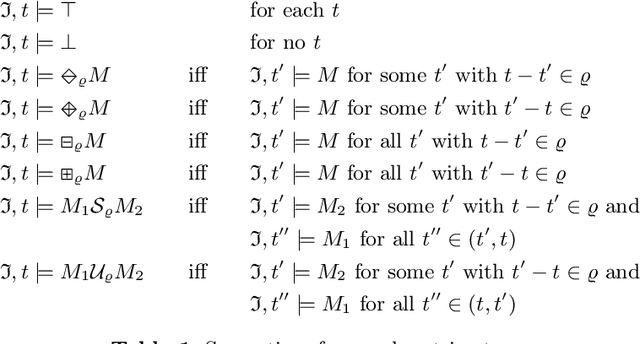
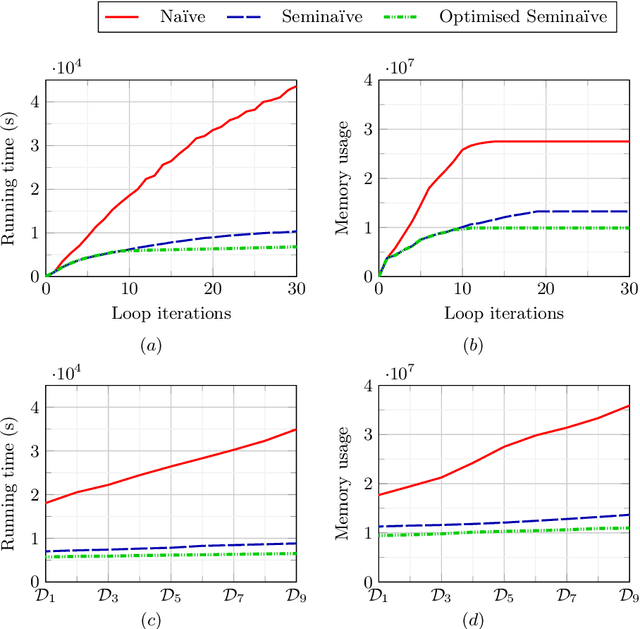
DatalogMTL is an extension of Datalog with metric temporal operators that has found applications in temporal ontology-based data access and query answering, as well as in stream reasoning. Practical algorithms for DatalogMTL are reliant on materialisation-based reasoning, where temporal facts are derived in a forward chaining manner in successive rounds of rule applications. Current materialisation-based procedures are, however, based on a naive evaluation strategy, where the main source of inefficiency stems from redundant computations. In this paper, we propose a materialisation-based procedure which, analogously to the classical seminaive algorithm in Datalog, aims at minimising redundant computation by ensuring that each temporal rule instance is considered at most once during the execution of the algorithm. Our experiments show that our optimised seminaive strategy for DatalogMTL is able to significantly reduce materialisation times.