 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHalDet: A Unified Benchmark for Hallucination Detection across Diverse Generation Scenarios
Jun 05, 2026Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of downstream domains and tasks. Consequently, reported detector performance is often difficult to compare, reproduce, and generalize beyond specific experimental settings. We introduce OpenHalDet, a unified benchmark for hallucination detection across diverse generation scenarios. OpenHalDet standardizes the evaluation pipeline, from prompt construction and response generation to truthfulness annotation, detector scoring, and metric computation. It supports heterogeneous detector families under different access settings, including black-box methods that use only generated outputs, gray-box methods that rely on probability-based signals, and white-box methods that exploit internal model signals. By bringing diverse tasks, models, and detectors into a shared framework, OpenHalDet enables controlled comparison and provides a systematic view of how different detection paradigms behave in LLM applications. We release OpenHalDet as an open and extensible codebase to facilitate reproducible evaluation and future development of hallucination detection methods. The code and datasets are available at https://github.com/Nellie179/Hallucination-Detection.
Multi-Agent Coordination Adaptation via Structure-Guided Orchestration
May 25, 2026As large language model (LLM)-based multi-agent systems scale to handle increasingly complex tasks, balancing structural stability and dynamic adaptability becomes increasingly challenging. Existing systems typically adopt either structure-centric methods, committing to structures determined upfront that limit fine-grained control, or orchestration-centric methods, adapting decisions dynamically while leaving coordination structure implicit and unstable. To address this challenge, we revisit multi-agent coordination from a probabilistic perspective, casting it as posterior inference over the joint distribution of structure and orchestration. We introduce MACA, an automated coordination framework that learns a task- and budget-conditioned structural prior over agent participation and interactions. This prior guides a policy-based orchestration as an approximation to posterior inference, enabling efficient solutions with fine-grained control. Across benchmarks, MACA outperforms adaptive multi-agent baselines by an average of 8.42% while using 43.19% fewer tokens. Further investigation reveals that joint adaptation of structure and orchestration suppresses redundant interactions, converging coordination toward task-effective execution.
GCCM: Enhancing Generative Graph Prediction via Contrastive Consistency Model
May 07, 2026Conditional generative models, particularly diffusion-based methods, have recently been applied to graph prediction by modeling the target as a conditional distribution given the input graph, yielding competitive results compared to deterministic predictor. However, existing diffusion-based prediction methods typically require expensive iterative denoising at inference and often suffer from unstable sampling, which motivates recent efforts to reduce inference denoising steps and enable stable sampling via techniques such as consistency training. Despite this progress, we find that existing consistency training methods for graph prediction could potentially fall into a shortcut solution: the model may attempt to satisfy the self-consistency constraint by ignoring the noisy target (i.e., assigning it negligible weight), ultimately collapsing into a purely deterministic predictor. To mitigate such shortcut solution, we propose GCCM, a graph contrastive consistency model that goes beyond isolated pairwise matching between the same target at different noise levels by introducing negative pairs into a contrastive consistency objective. This adds an additional separation requirement, making the shortcut solution no longer trivially sufficient to satisfy the proposed objective. Moreover, we apply feature perturbation to the input node/edge features to break identical conditioning on the input graph, so that the shortcut no longer yields the same predictions across noise levels and becomes less attractive. Extensive experiments on benchmark datasets demonstrate that GCCM mitigates the shortcut solution and yields consistent performance improvements in graph prediction compared to deterministic predictors.
Small Shifts, Large Gains: Unlocking Traditional TSP Heuristic Guided-Sampling via Unsupervised Neural Instance Modification
Jan 31, 2026The Traveling Salesman Problem (TSP) is one of the most representative NP-hard problems in route planning and a long-standing benchmark in combinatorial optimization. Traditional heuristic tour constructors, such as Farthest or Nearest Insertion, are computationally efficient and highly practical, but their deterministic behavior limits exploration and often leads to local optima. In contrast, neural-based heuristic tour constructors alleviate this issue through guided-sampling and typically achieve superior solution quality, but at the cost of extensive training and reliance on ground-truth supervision, hindering their practical use. To bridge this gap, we propose TSP-MDF, a novel instance modification framework that equips traditional deterministic heuristic tour constructors with guided-sampling capability. Specifically, TSP-MDF introduces a neural-based instance modifier that strategically shifts node coordinates to sample multiple modified instances, on which the base traditional heuristic tour constructor constructs tours that are mapped back to the original instance, allowing traditional tour constructors to explore higher-quality tours and escape local optima. At the same time, benefiting from our instance modification formulation, the neural-based instance modifier can be trained efficiently without any ground-truth supervision, ensuring the framework maintains practicality. Extensive experiments on large-scale TSP benchmarks and real-world benchmarks demonstrate that TSP-MDF significantly improves the performance of traditional heuristics tour constructors, achieving solution quality comparable to neural-based heuristic tour constructors, but with an extremely short training time.
TwinWeaver: An LLM-Based Foundation Model Framework for Pan-Cancer Digital Twins
Jan 28, 2026Precision oncology requires forecasting clinical events and trajectories, yet modeling sparse, multi-modal clinical time series remains a critical challenge. We introduce TwinWeaver, an open-source framework that serializes longitudinal patient histories into text, enabling unified event prediction as well as forecasting with large language models, and use it to build Genie Digital Twin (GDT) on 93,054 patients across 20 cancer types. In benchmarks, GDT significantly reduces forecasting error, achieving a median Mean Absolute Scaled Error (MASE) of 0.87 compared to 0.97 for the strongest time-series baseline (p<0.001). Furthermore, GDT improves risk stratification, achieving an average concordance index (C-index) of 0.703 across survival, progression, and therapy switching tasks, surpassing the best baseline of 0.662. GDT also generalizes to out-of-distribution clinical trials, matching trained baselines at zero-shot and surpassing them with fine-tuning, achieving a median MASE of 0.75-0.88 and outperforming the strongest baseline in event prediction with an average C-index of 0.672 versus 0.648. Finally, TwinWeaver enables an interpretable clinical reasoning extension, providing a scalable and transparent foundation for longitudinal clinical modeling.
Muse: Towards Reproducible Long-Form Song Generation with Fine-Grained Style Control
Jan 08, 2026Recent commercial systems such as Suno demonstrate strong capabilities in long-form song generation, while academic research remains largely non-reproducible due to the lack of publicly available training data, hindering fair comparison and progress. To this end, we release a fully open-source system for long-form song generation with fine-grained style conditioning, including a licensed synthetic dataset, training and evaluation pipelines, and Muse, an easy-to-deploy song generation model. The dataset consists of 116k fully licensed synthetic songs with automatically generated lyrics and style descriptions paired with audio synthesized by SunoV5. We train Muse via single-stage supervised finetuning of a Qwen-based language model extended with discrete audio tokens using MuCodec, without task-specific losses, auxiliary objectives, or additional architectural components. Our evaluations find that although Muse is trained with a modest data scale and model size, it achieves competitive performance on phoneme error rate, text--music style similarity, and audio aesthetic quality, while enabling controllable segment-level generation across different musical structures. All data, model weights, and training and evaluation pipelines will be publicly released, paving the way for continued progress in controllable long-form song generation research. The project repository is available at https://github.com/yuhui1038/Muse.
FADTI: Fourier and Attention Driven Diffusion for Multivariate Time Series Imputation
Dec 17, 2025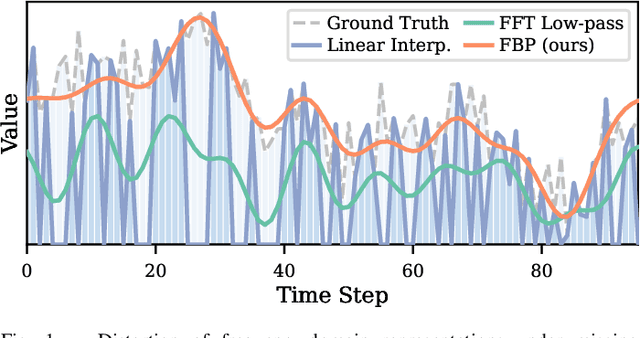
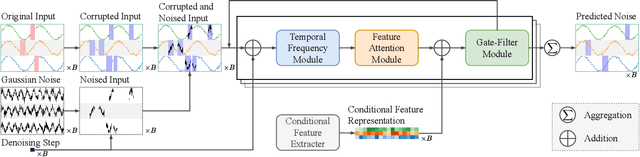

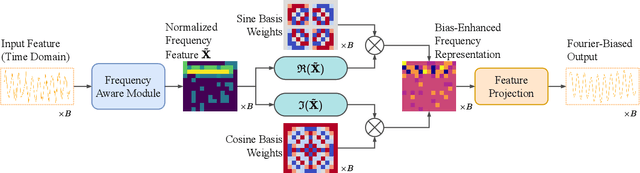
Multivariate time series imputation is fundamental in applications such as healthcare, traffic forecasting, and biological modeling, where sensor failures and irregular sampling lead to pervasive missing values. However, existing Transformer- and diffusion-based models lack explicit inductive biases and frequency awareness, limiting their generalization under structured missing patterns and distribution shifts. We propose FADTI, a diffusion-based framework that injects frequency-informed feature modulation via a learnable Fourier Bias Projection (FBP) module and combines it with temporal modeling through self-attention and gated convolution. FBP supports multiple spectral bases, enabling adaptive encoding of both stationary and non-stationary patterns. This design injects frequency-domain inductive bias into the generative imputation process. Experiments on multiple benchmarks, including a newly introduced biological time series dataset, show that FADTI consistently outperforms state-of-the-art methods, particularly under high missing rates. Code is available at https://anonymous.4open.science/r/TimeSeriesImputation-52BF
OpenPros: A Large-Scale Dataset for Limited View Prostate Ultrasound Computed Tomography
May 18, 2025Prostate cancer is one of the most common and lethal cancers among men, making its early detection critically important. Although ultrasound imaging offers greater accessibility and cost-effectiveness compared to MRI, traditional transrectal ultrasound methods suffer from low sensitivity, especially in detecting anteriorly located tumors. Ultrasound computed tomography provides quantitative tissue characterization, but its clinical implementation faces significant challenges, particularly under anatomically constrained limited-angle acquisition conditions specific to prostate imaging. To address these unmet needs, we introduce OpenPros, the first large-scale benchmark dataset explicitly developed for limited-view prostate USCT. Our dataset includes over 280,000 paired samples of realistic 2D speed-of-sound (SOS) phantoms and corresponding ultrasound full-waveform data, generated from anatomically accurate 3D digital prostate models derived from real clinical MRI/CT scans and ex vivo ultrasound measurements, annotated by medical experts. Simulations are conducted under clinically realistic configurations using advanced finite-difference time-domain and Runge-Kutta acoustic wave solvers, both provided as open-source components. Through comprehensive baseline experiments, we demonstrate that state-of-the-art deep learning methods surpass traditional physics-based approaches in both inference efficiency and reconstruction accuracy. Nevertheless, current deep learning models still fall short of delivering clinically acceptable high-resolution images with sufficient accuracy. By publicly releasing OpenPros, we aim to encourage the development of advanced machine learning algorithms capable of bridging this performance gap and producing clinically usable, high-resolution, and highly accurate prostate ultrasound images. The dataset is publicly accessible at https://open-pros.github.io/.
Towards Artificial Intelligence Research Assistant for Expert-Involved Learning
May 03, 2025Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have emerged as transformative tools in scientific research, yet their reliability and specific contributions to biomedical applications remain insufficiently characterized. In this study, we present \textbf{AR}tificial \textbf{I}ntelligence research assistant for \textbf{E}xpert-involved \textbf{L}earning (ARIEL), a multimodal dataset designed to benchmark and enhance two critical capabilities of LLMs and LMMs in biomedical research: summarizing extensive scientific texts and interpreting complex biomedical figures. To facilitate rigorous assessment, we create two open-source sets comprising biomedical articles and figures with designed questions. We systematically benchmark both open- and closed-source foundation models, incorporating expert-driven human evaluations conducted by doctoral-level experts. Furthermore, we improve model performance through targeted prompt engineering and fine-tuning strategies for summarizing research papers, and apply test-time computational scaling to enhance the reasoning capabilities of LMMs, achieving superior accuracy compared to human-expert corrections. We also explore the potential of using LMM Agents to generate scientific hypotheses from diverse multimodal inputs. Overall, our results delineate clear strengths and highlight significant limitations of current foundation models, providing actionable insights and guiding future advancements in deploying large-scale language and multi-modal models within biomedical research.
Learned Correction Methods for Ultrasound Computed Tomography Imaging Using Simplified Physics Models
Feb 13, 2025


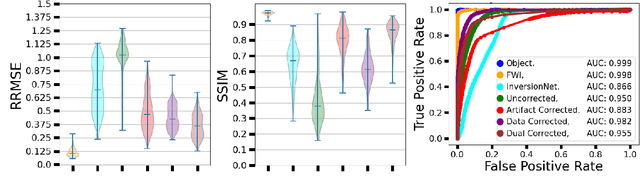
Ultrasound computed tomography (USCT) is an emerging modality for breast imaging. Image reconstruction methods that incorporate accurate wave physics produce high resolution quantitative images of acoustic properties but are computationally expensive. The use of a simplified linear model in reconstruction reduces computational expense at the cost of reduced accuracy. This work aims to systematically compare different learning approaches for USCT reconstruction utilizing simplified linear models. This work considered various learning approaches to compensate for errors stemming from a linearized wave propagation model: correction in the data and image domains. The resulting image reconstruction methods are systematically assessed, alongside data-driven and model-based methods, in four virtual imaging studies utilizing anatomically realistic numerical phantoms. Image quality was assessed utilizing relative root mean square error (RRMSE), structural similarity index measure (SSIM), and a task-based assessment for tumor detection. Correction in the measurement domain resulted in images with minor visual artifacts and highly accurate task performance. Correction in the image domain demonstrated a heavy bias on training data, resulting in hallucinations, but greater robustness to measurement noise. Combining both forms of correction performed best in terms of RRMSE and SSIM, at the cost of task performance. This work systematically assessed learned reconstruction methods incorporating an approximated physical model for USCT imaging. Results demonstrated the importance of incorporating physics, compared to data-driven methods. Learning a correction in the data domain led to better task performance and robust out-of-distribution generalization compared to correction in the image domain.