 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.
PR2: Peephole Raw Pointer Rewriting with LLMs for Translating C to Safer Rust
May 07, 2025



There has been a growing interest in translating C code to Rust due to Rust's robust memory and thread safety guarantees. Tools such as C2RUST enable syntax-guided transpilation from C to semantically equivalent Rust code. However, the resulting Rust programs often rely heavily on unsafe constructs--particularly raw pointers--which undermines Rust's safety guarantees. This paper aims to improve the memory safety of Rust programs generated by C2RUST by eliminating raw pointers. Specifically, we propose a peephole raw pointer rewriting technique that lifts raw pointers in individual functions to appropriate Rust data structures. Technically, PR2 employs decision-tree-based prompting to guide the pointer lifting process. Additionally, it leverages code change analysis to guide the repair of errors introduced during rewriting, effectively addressing errors encountered during compilation and test case execution. We implement PR2 as a prototype and evaluate it using gpt-4o-mini on 28 real-world C projects. The results show that PR2 successfully eliminates 13.22% of local raw pointers across these projects, significantly enhancing the safety of the translated Rust code. On average, PR2 completes the transformation of a project in 5.44 hours, at an average cost of $1.46.
Validating Network Protocol Parsers with Traceable RFC Document Interpretation
Apr 25, 2025



Validating the correctness of network protocol implementations is highly challenging due to the oracle and traceability problems. The former determines when a protocol implementation can be considered buggy, especially when the bugs do not cause any observable symptoms. The latter allows developers to understand how an implementation violates the protocol specification, thereby facilitating bug fixes. Unlike existing works that rarely take both problems into account, this work considers both and provides an effective solution using recent advances in large language models (LLMs). Our key observation is that network protocols are often released with structured specification documents, a.k.a. RFC documents, which can be systematically translated to formal protocol message specifications via LLMs. Such specifications, which may contain errors due to the hallucination of LLMs, are used as a quasi-oracle to validate protocol parsers, while the validation results in return gradually refine the oracle. Since the oracle is derived from the document, any bugs we find in a protocol implementation can be traced back to the document, thus addressing the traceability problem. We have extensively evaluated our approach using nine network protocols and their implementations written in C, Python, and Go. The results show that our approach outperforms the state-of-the-art and has detected 69 bugs, with 36 confirmed. The project also demonstrates the potential for fully automating software validation based on natural language specifications, a process previously considered predominantly manual due to the need to understand specification documents and derive expected outputs for test inputs.
QCS:Feature Refining from Quadruplet Cross Similarity for Facial Expression Recognition
Nov 04, 2024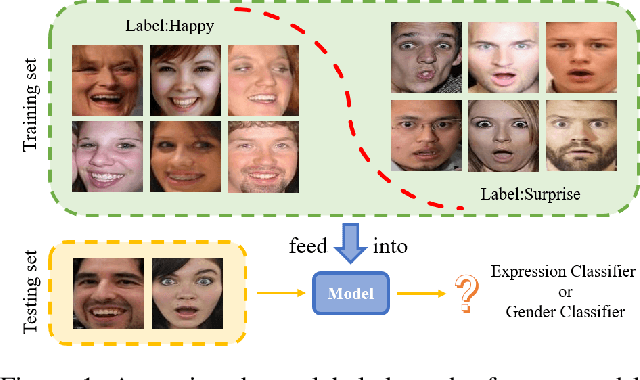
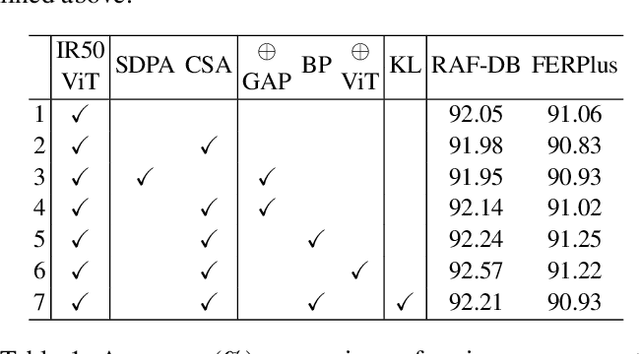
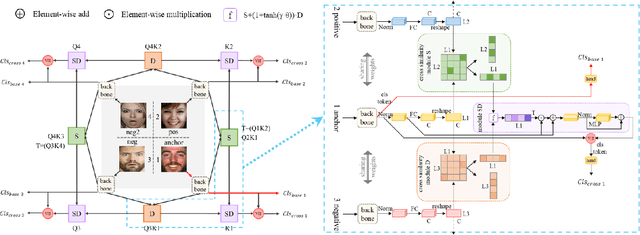
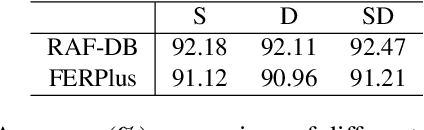
On facial expression datasets with complex and numerous feature types, where the significance and dominance of labeled features are difficult to predict, facial expression recognition(FER) encounters the challenges of inter-class similarity and intra-class variances, making it difficult to mine effective features. We aim to solely leverage the feature similarity among facial samples to address this. We introduce the Cross Similarity Attention (CSA), an input-output position-sensitive attention mechanism that harnesses feature similarity across different images to compute the corresponding global spatial attention. Based on this, we propose a four-branch circular framework, called Quadruplet Cross Similarity (QCS), to extract discriminative features from the same class and eliminate redundant ones from different classes synchronously to refine cleaner features. The symmetry of the network ensures balanced and stable training and reduces the amount of CSA interaction matrix. Contrastive residual distillation is utilized to transfer the information learned in the cross module back to the base network. The cross-attention module exists during training, and only one base branch is retained during inference. our proposed QCS model outperforms state-of-the-art methods on several popular FER datasets, without requiring additional landmark information or other extra training data. The code is available at https://github.com/birdwcp/QCS.
REPOFUSE: Repository-Level Code Completion with Fused Dual Context
Feb 23, 2024


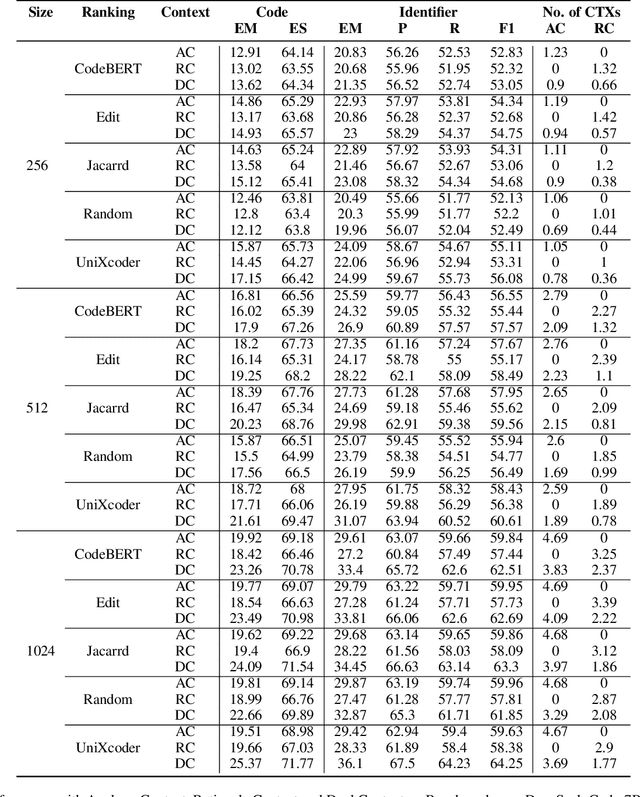
The success of language models in code assistance has spurred the proposal of repository-level code completion as a means to enhance prediction accuracy, utilizing the context from the entire codebase. However, this amplified context can inadvertently increase inference latency, potentially undermining the developer experience and deterring tool adoption - a challenge we termed the Context-Latency Conundrum. This paper introduces REPOFUSE, a pioneering solution designed to enhance repository-level code completion without the latency trade-off. REPOFUSE uniquely fuses two types of context: the analogy context, rooted in code analogies, and the rationale context, which encompasses in-depth semantic relationships. We propose a novel rank truncated generation (RTG) technique that efficiently condenses these contexts into prompts with restricted size. This enables REPOFUSE to deliver precise code completions while maintaining inference efficiency. Through testing with the CrossCodeEval suite, REPOFUSE has demonstrated a significant leap over existing models, achieving a 40.90% to 59.75% increase in exact match (EM) accuracy for code completions and a 26.8% enhancement in inference speed. Beyond experimental validation, REPOFUSE has been integrated into the workflow of a large enterprise, where it actively supports various coding tasks.
When Dataflow Analysis Meets Large Language Models
Feb 16, 2024


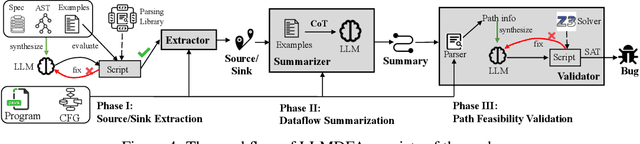
Dataflow analysis is a powerful code analysis technique that reasons dependencies between program values, offering support for code optimization, program comprehension, and bug detection. Existing approaches require the successful compilation of the subject program and customizations for downstream applications. This paper introduces LLMDFA, an LLM-powered dataflow analysis framework that analyzes arbitrary code snippets without requiring a compilation infrastructure and automatically synthesizes downstream applications. Inspired by summary-based dataflow analysis, LLMDFA decomposes the problem into three sub-problems, which are effectively resolved by several essential strategies, including few-shot chain-of-thought prompting and tool synthesis. Our evaluation has shown that the design can mitigate the hallucination and improve the reasoning ability, obtaining high precision and recall in detecting dataflow-related bugs upon benchmark programs, outperforming state-of-the-art (classic) tools, including a very recent industrial analyzer.
Unsupervised Discovery of Steerable Factors When Graph Deep Generative Models Are Entangled
Jan 29, 2024Deep generative models (DGMs) have been widely developed for graph data. However, much less investigation has been carried out on understanding the latent space of such pretrained graph DGMs. These understandings possess the potential to provide constructive guidelines for crucial tasks, such as graph controllable generation. Thus in this work, we are interested in studying this problem and propose GraphCG, a method for the unsupervised discovery of steerable factors in the latent space of pretrained graph DGMs. We first examine the representation space of three pretrained graph DGMs with six disentanglement metrics, and we observe that the pretrained representation space is entangled. Motivated by this observation, GraphCG learns the steerable factors via maximizing the mutual information between semantic-rich directions, where the controlled graph moving along the same direction will share the same steerable factors. We quantitatively verify that GraphCG outperforms four competitive baselines on two graph DGMs pretrained on two molecule datasets. Additionally, we qualitatively illustrate seven steerable factors learned by GraphCG on five pretrained DGMs over five graph datasets, including two for molecules and three for point clouds.
ChatGPT-powered Conversational Drug Editing Using Retrieval and Domain Feedback
May 29, 2023Recent advancements in conversational large language models (LLMs), such as ChatGPT, have demonstrated remarkable promise in various domains, including drug discovery. However, existing works mainly focus on investigating the capabilities of conversational LLMs on chemical reaction and retrosynthesis. While drug editing, a critical task in the drug discovery pipeline, remains largely unexplored. To bridge this gap, we propose ChatDrug, a framework to facilitate the systematic investigation of drug editing using LLMs. ChatDrug jointly leverages a prompt module, a retrieval and domain feedback (ReDF) module, and a conversation module to streamline effective drug editing. We empirically show that ChatDrug reaches the best performance on 33 out of 39 drug editing tasks, encompassing small molecules, peptides, and proteins. We further demonstrate, through 10 case studies, that ChatDrug can successfully identify the key substructures (e.g., the molecule functional groups, peptide motifs, and protein structures) for manipulation, generating diverse and valid suggestions for drug editing. Promisingly, we also show that ChatDrug can offer insightful explanations from a domain-specific perspective, enhancing interpretability and enabling informed decision-making. This research sheds light on the potential of ChatGPT and conversational LLMs for drug editing. It paves the way for a more efficient and collaborative drug discovery pipeline, contributing to the advancement of pharmaceutical research and development.
Multi-modal Molecule Structure-text Model for Text-based Retrieval and Editing
Dec 21, 2022There is increasing adoption of artificial intelligence in drug discovery. However, existing works use machine learning to mainly utilize the chemical structures of molecules yet ignore the vast textual knowledge available in chemistry. Incorporating textual knowledge enables us to realize new drug design objectives, adapt to text-based instructions, and predict complex biological activities. We present a multi-modal molecule structure-text model, MoleculeSTM, by jointly learning molecule's chemical structures and textual descriptions via a contrastive learning strategy. To train MoleculeSTM, we construct the largest multi-modal dataset to date, namely PubChemSTM, with over 280K chemical structure-text pairs. To demonstrate the effectiveness and utility of MoleculeSTM, we design two challenging zero-shot tasks based on text instructions, including structure-text retrieval and molecule editing. MoleculeSTM possesses two main properties: open vocabulary and compositionality via natural language. In experiments, MoleculeSTM obtains the state-of-the-art generalization ability to novel biochemical concepts across various benchmarks.