 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Spatio-Temporal Neural Network for Air Quality Reanalysis
Feb 17, 2025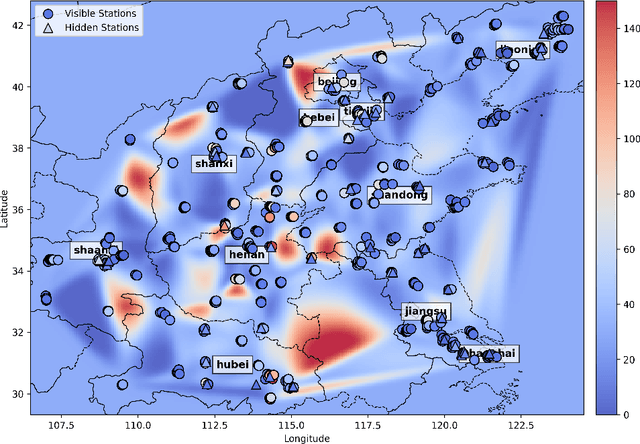
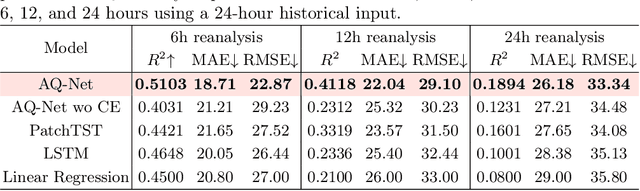
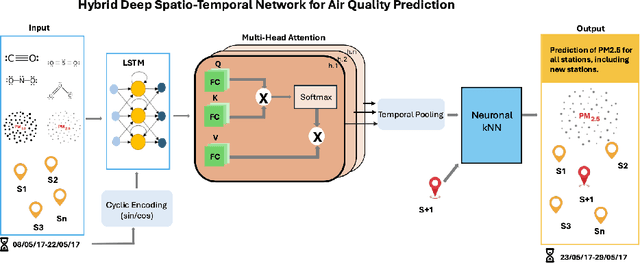

Air quality prediction is key to mitigating health impacts and guiding decisions, yet existing models tend to focus on temporal trends while overlooking spatial generalization. We propose AQ-Net, a spatiotemporal reanalysis model for both observed and unobserved stations in the near future. AQ-Net utilizes the LSTM and multi-head attention for the temporal regression. We also propose a cyclic encoding technique to ensure continuous time representation. To learn fine-grained spatial air quality estimation, we incorporate AQ-Net with the neural kNN to explore feature-based interpolation, such that we can fill the spatial gaps given coarse observation stations. To demonstrate the efficiency of our model for spatiotemporal reanalysis, we use data from 2013-2017 collected in northern China for PM2.5 analysis. Extensive experiments show that AQ-Net excels in air quality reanalysis, highlighting the potential of hybrid spatio-temporal models to better capture environmental dynamics, especially in urban areas where both spatial and temporal variability are critical.
FFA Sora, video generation as fundus fluorescein angiography simulator
Dec 23, 2024



Fundus fluorescein angiography (FFA) is critical for diagnosing retinal vascular diseases, but beginners often struggle with image interpretation. This study develops FFA Sora, a text-to-video model that converts FFA reports into dynamic videos via a Wavelet-Flow Variational Autoencoder (WF-VAE) and a diffusion transformer (DiT). Trained on an anonymized dataset, FFA Sora accurately simulates disease features from the input text, as confirmed by objective metrics: Frechet Video Distance (FVD) = 329.78, Learned Perceptual Image Patch Similarity (LPIPS) = 0.48, and Visual-question-answering Score (VQAScore) = 0.61. Specific evaluations showed acceptable alignment between the generated videos and textual prompts, with BERTScore of 0.35. Additionally, the model demonstrated strong privacy-preserving performance in retrieval evaluations, achieving an average Recall@K of 0.073. Human assessments indicated satisfactory visual quality, with an average score of 1.570(scale: 1 = best, 5 = worst). This model addresses privacy concerns associated with sharing large-scale FFA data and enhances medical education.
GoHD: Gaze-oriented and Highly Disentangled Portrait Animation with Rhythmic Poses and Realistic Expression
Dec 13, 2024



Audio-driven talking head generation necessitates seamless integration of audio and visual data amidst the challenges posed by diverse input portraits and intricate correlations between audio and facial motions. In response, we propose a robust framework GoHD designed to produce highly realistic, expressive, and controllable portrait videos from any reference identity with any motion. GoHD innovates with three key modules: Firstly, an animation module utilizing latent navigation is introduced to improve the generalization ability across unseen input styles. This module achieves high disentanglement of motion and identity, and it also incorporates gaze orientation to rectify unnatural eye movements that were previously overlooked. Secondly, a conformer-structured conditional diffusion model is designed to guarantee head poses that are aware of prosody. Thirdly, to estimate lip-synchronized and realistic expressions from the input audio within limited training data, a two-stage training strategy is devised to decouple frequent and frame-wise lip motion distillation from the generation of other more temporally dependent but less audio-related motions, e.g., blinks and frowns. Extensive experiments validate GoHD's advanced generalization capabilities, demonstrating its effectiveness in generating realistic talking face results on arbitrary subjects.
QCS:Feature Refining from Quadruplet Cross Similarity for Facial Expression Recognition
Nov 04, 2024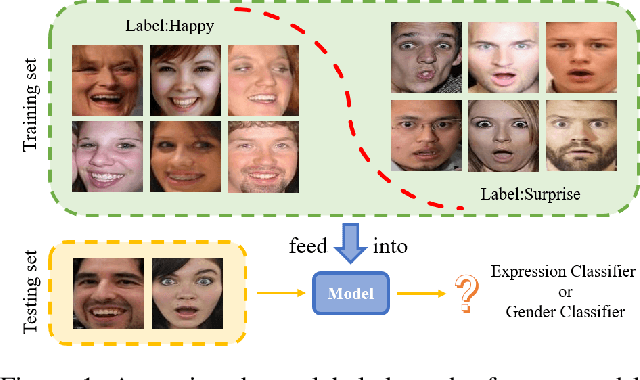
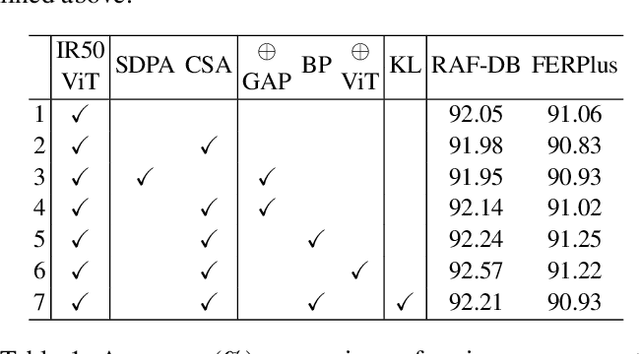
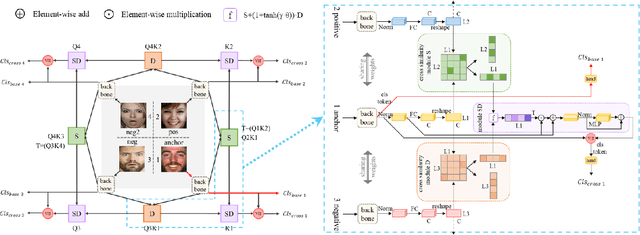
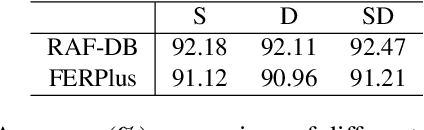
On facial expression datasets with complex and numerous feature types, where the significance and dominance of labeled features are difficult to predict, facial expression recognition(FER) encounters the challenges of inter-class similarity and intra-class variances, making it difficult to mine effective features. We aim to solely leverage the feature similarity among facial samples to address this. We introduce the Cross Similarity Attention (CSA), an input-output position-sensitive attention mechanism that harnesses feature similarity across different images to compute the corresponding global spatial attention. Based on this, we propose a four-branch circular framework, called Quadruplet Cross Similarity (QCS), to extract discriminative features from the same class and eliminate redundant ones from different classes synchronously to refine cleaner features. The symmetry of the network ensures balanced and stable training and reduces the amount of CSA interaction matrix. Contrastive residual distillation is utilized to transfer the information learned in the cross module back to the base network. The cross-attention module exists during training, and only one base branch is retained during inference. our proposed QCS model outperforms state-of-the-art methods on several popular FER datasets, without requiring additional landmark information or other extra training data. The code is available at https://github.com/birdwcp/QCS.
A Versatile Framework for Analyzing Galaxy Image Data by Implanting Human-in-the-loop on a Large Vision Model
May 17, 2024The exponential growth of astronomical datasets provides an unprecedented opportunity for humans to gain insight into the Universe. However, effectively analyzing this vast amount of data poses a significant challenge. Astronomers are turning to deep learning techniques to address this, but the methods are limited by their specific training sets, leading to considerable duplicate workloads too. Hence, as an example to present how to overcome the issue, we built a framework for general analysis of galaxy images, based on a large vision model (LVM) plus downstream tasks (DST), including galaxy morphological classification, image restoration, object detection, parameter extraction, and more. Considering the low signal-to-noise ratio of galaxy images and the imbalanced distribution of galaxy categories, we have incorporated a Human-in-the-loop (HITL) module into our large vision model, which leverages human knowledge to enhance the reliability and interpretability of processing galaxy images interactively. The proposed framework exhibits notable few-shot learning capabilities and versatile adaptability to all the abovementioned tasks on galaxy images in the DESI legacy imaging surveys. Expressly, for object detection, trained by 1000 data points, our DST upon the LVM achieves an accuracy of 96.7%, while ResNet50 plus Mask R-CNN gives an accuracy of 93.1%; for morphology classification, to obtain AUC ~0.9, LVM plus DST and HITL only requests 1/50 training sets compared to ResNet18. Expectedly, multimodal data can be integrated similarly, which opens up possibilities for conducting joint analyses with datasets spanning diverse domains in the era of multi-message astronomy.
Guided Diffusion for Fast Inverse Design of Density-based Mechanical Metamaterials
Jan 24, 2024Mechanical metamaterial is a synthetic material that can possess extraordinary physical characteristics, such as abnormal elasticity, stiffness, and stability, by carefully designing its internal structure. To make metamaterials contain delicate local structures with unique mechanical properties, it is a potential method to represent them through high-resolution voxels. However, it brings a substantial computational burden. To this end, this paper proposes a fast inverse design method, whose core is an advanced deep generative AI algorithm, to generate voxel-based mechanical metamaterials. Specifically, we use the self-conditioned diffusion model, capable of generating a microstructure with a resolution of $128^3$ to approach the specified homogenized tensor matrix in just 3 seconds. Accordingly, this rapid reverse design tool facilitates the exploration of extreme metamaterials, the sequence interpolation in metamaterials, and the generation of diverse microstructures for multi-scale design. This flexible and adaptive generative tool is of great value in structural engineering or other mechanical systems and can stimulate more subsequent research.
Feature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 21, 2023



Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Graph-Level Embedding for Time-Evolving Graphs
Jun 01, 2023Graph representation learning (also known as network embedding) has been extensively researched with varying levels of granularity, ranging from nodes to graphs. While most prior work in this area focuses on node-level representation, limited research has been conducted on graph-level embedding, particularly for dynamic or temporal networks. However, learning low-dimensional graph-level representations for dynamic networks is critical for various downstream graph retrieval tasks such as temporal graph similarity ranking, temporal graph isomorphism, and anomaly detection. In this paper, we present a novel method for temporal graph-level embedding that addresses this gap. Our approach involves constructing a multilayer graph and using a modified random walk with temporal backtracking to generate temporal contexts for the graph's nodes. We then train a "document-level" language model on these contexts to generate graph-level embeddings. We evaluate our proposed model on five publicly available datasets for the task of temporal graph similarity ranking, and our model outperforms baseline methods. Our experimental results demonstrate the effectiveness of our method in generating graph-level embeddings for dynamic networks.
EnCBP: A New Benchmark Dataset for Finer-Grained Cultural Background Prediction in English
Mar 28, 2022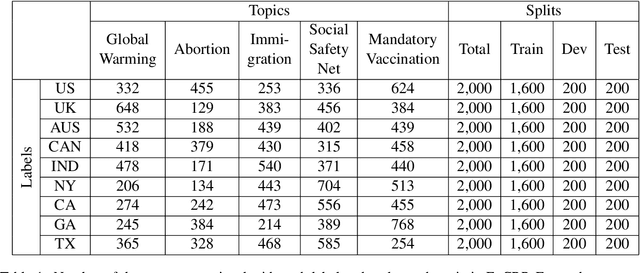


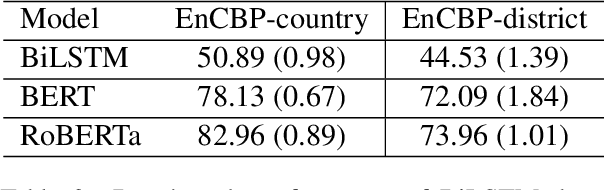
While cultural backgrounds have been shown to affect linguistic expressions, existing natural language processing (NLP) research on culture modeling is overly coarse-grained and does not examine cultural differences among speakers of the same language. To address this problem and augment NLP models with cultural background features, we collect, annotate, manually validate, and benchmark EnCBP, a finer-grained news-based cultural background prediction dataset in English. Through language modeling (LM) evaluations and manual analyses, we confirm that there are noticeable differences in linguistic expressions among five English-speaking countries and across four states in the US. Additionally, our evaluations on nine syntactic (CoNLL-2003), semantic (PAWS-Wiki, QNLI, STS-B, and RTE), and psycholinguistic tasks (SST-5, SST-2, Emotion, and Go-Emotions) show that, while introducing cultural background information does not benefit the Go-Emotions task due to text domain conflicts, it noticeably improves deep learning (DL) model performance on other tasks. Our findings strongly support the importance of cultural background modeling to a wide variety of NLP tasks and demonstrate the applicability of EnCBP in culture-related research.
Embedding Node Structural Role Identity Using Stress Majorization
Sep 14, 2021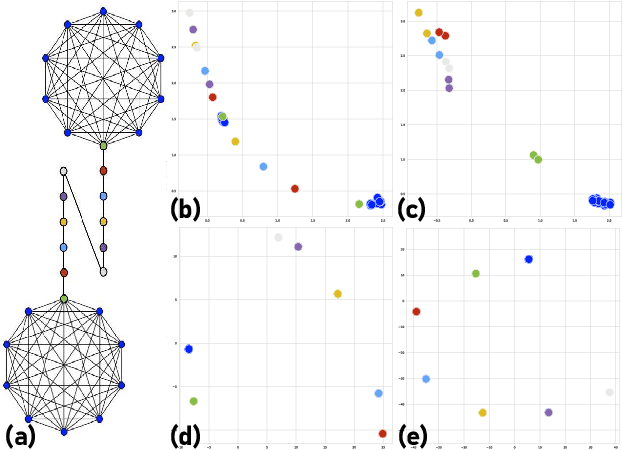
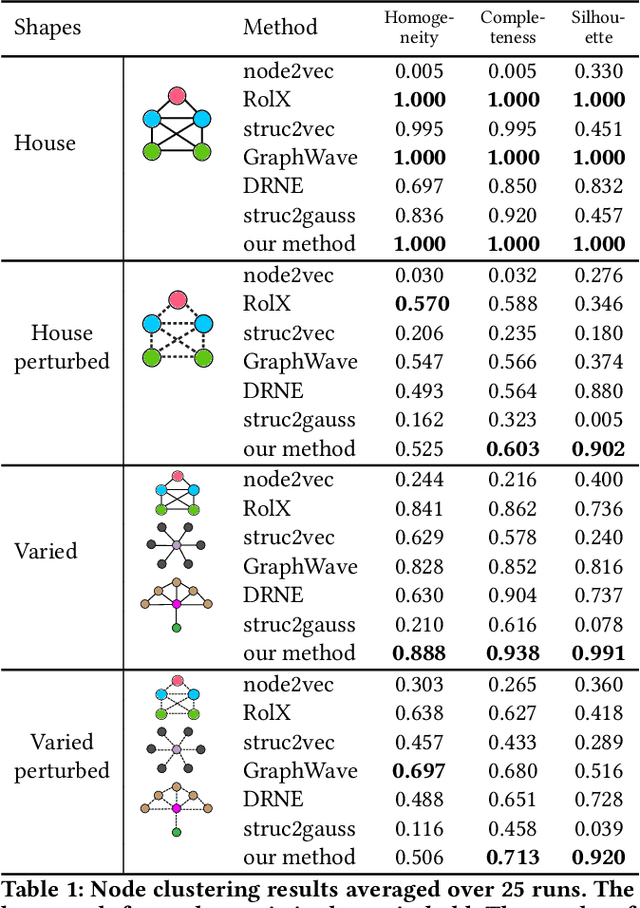
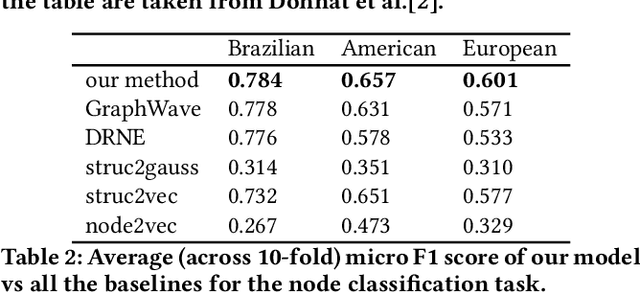
Nodes in networks may have one or more functions that determine their role in the system. As opposed to local proximity, which captures the local context of nodes, the role identity captures the functional "role" that nodes play in a network, such as being the center of a group, or the bridge between two groups. This means that nodes far apart in a network can have similar structural role identities. Several recent works have explored methods for embedding the roles of nodes in networks. However, these methods all rely on either approximating or indirect modeling of structural equivalence. In this paper, we present a novel and flexible framework using stress majorization, to transform the high-dimensional role identities in networks directly (without approximation or indirect modeling) to a low-dimensional embedding space. Our method is also flexible, in that it does not rely on specific structural similarity definitions. We evaluated our method on the tasks of node classification, clustering, and visualization, using three real-world and five synthetic networks. Our experiments show that our framework achieves superior results than existing methods in learning node role representations.