 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Report-Derived Oncology VQA Benchmark for Evaluating Vision-Language Models on 3D Medical Imaging
Jun 01, 2026Evaluating vision-language models (VLMs) on medical images requires benchmarks that are clinically grounded, scalable, and controlled for evaluation confounds. Existing public benchmarks are limited in scale, manually annotated, or potentially leaked into VLM pretraining corpora. We present an automated agent-driven pipeline that generates multiple-choice VQA datasets directly from paired private radiology reports and 3D oncology imaging, producing two complementary question types: RADS-style questions deterministically derived from clinician-defined reporting schemas, and radiology report-derived questions generated by an LLM from radiologist findings and verified against the source report. Applied to four in-house cancer cohorts, the pipeline yields an instance-contamination-controlled benchmark without per-question human annotation. Zero-shot evaluation of six VLMs reveals no dominant model and substantial headroom across all cells. A blind ablation reveals that visual reliance is highly dataset-specific: liver Report-derived questions genuinely require the image, while Lung CT is essentially solvable without it - the leading closed model exceeds its sighted accuracy on Lung CT when blinded - indicating that even private clinical data does not guarantee a contamination-controlled read of visual capability. The pipeline is released as an open agent skill for in-house redeployment.
A Weak Signal Learning Dataset and Its Baseline Method
Dec 29, 2025Weak signal learning (WSL) is a common challenge in many fields like fault diagnosis, medical imaging, and autonomous driving, where critical information is often masked by noise and interference, making feature identification difficult. Even in tasks with abundant strong signals, the key to improving model performance often lies in effectively extracting weak signals. However, the lack of dedicated datasets has long constrained research. To address this, we construct the first specialized dataset for weak signal feature learning, containing 13,158 spectral samples. It features low SNR dominance (over 55% samples with SNR below 50) and extreme class imbalance (class ratio up to 29:1), providing a challenging benchmark for classification and regression in weak signal scenarios. We also propose a dual-view representation (vector + time-frequency map) and a PDVFN model tailored to low SNR, distribution skew, and dual imbalance. PDVFN extracts local sequential features and global frequency-domain structures in parallel, following principles of local enhancement, sequential modeling, noise suppression, multi-scale capture, frequency extraction, and global perception. This multi-source complementarity enhances representation for low-SNR and imbalanced data, offering a novel solution for WSL tasks like astronomical spectroscopy. Experiments show our method achieves higher accuracy and robustness in handling weak signals, high noise, and extreme class imbalance, especially in low SNR and imbalanced scenarios. This study provides a dedicated dataset, a baseline model, and establishes a foundation for future WSL research.
RepSNet: A Nucleus Instance Segmentation model based on Boundary Regression and Structural Re-parameterization
May 08, 2025Pathological diagnosis is the gold standard for tumor diagnosis, and nucleus instance segmentation is a key step in digital pathology analysis and pathological diagnosis. However, the computational efficiency of the model and the treatment of overlapping targets are the major challenges in the studies of this problem. To this end, a neural network model RepSNet was designed based on a nucleus boundary regression and a structural re-parameterization scheme for segmenting and classifying the nuclei in H\&E-stained histopathological images. First, RepSNet estimates the boundary position information (BPI) of the parent nucleus for each pixel. The BPI estimation incorporates the local information of the pixel and the contextual information of the parent nucleus. Then, the nucleus boundary is estimated by aggregating the BPIs from a series of pixels using a proposed boundary voting mechanism (BVM), and the instance segmentation results are computed from the estimated nucleus boundary using a connected component analysis procedure. The BVM intrinsically achieves a kind of synergistic belief enhancement among the BPIs from various pixels. Therefore, different from the methods available in literature that obtain nucleus boundaries based on a direct pixel recognition scheme, RepSNet computes its boundary decisions based on some guidances from macroscopic information using an integration mechanism. In addition, RepSNet employs a re-parametrizable encoder-decoder structure. This model can not only aggregate features from some receptive fields with various scales which helps segmentation accuracy improvement, but also reduce the parameter amount and computational burdens in the model inference phase through the structural re-parameterization technique. Extensive experiments demonstrated the superiorities of RepSNet compared to several typical benchmark models.
* 25 pages, 7 figures, 5 tables
CVVNet: A Cross-Vertical-View Network for Gait Recognition
May 03, 2025Gait recognition enables contact-free, long-range person identification that is robust to clothing variations and non-cooperative scenarios. While existing methods perform well in controlled indoor environments, they struggle with cross-vertical view scenarios, where surveillance angles vary significantly in elevation. Our experiments show up to 60\% accuracy degradation in low-to-high vertical view settings due to severe deformations and self-occlusions of key anatomical features. Current CNN and self-attention-based methods fail to effectively handle these challenges, due to their reliance on single-scale convolutions or simplistic attention mechanisms that lack effective multi-frequency feature integration. To tackle this challenge, we propose CVVNet (Cross-Vertical-View Network), a frequency aggregation architecture specifically designed for robust cross-vertical-view gait recognition. CVVNet employs a High-Low Frequency Extraction module (HLFE) that adopts parallel multi-scale convolution/max-pooling path and self-attention path as high- and low-frequency mixers for effective multi-frequency feature extraction from input silhouettes. We also introduce the Dynamic Gated Aggregation (DGA) mechanism to adaptively adjust the fusion ratio of high- and low-frequency features. The integration of our core Multi-Scale Attention Gated Aggregation (MSAGA) module, HLFE and DGA enables CVVNet to effectively handle distortions from view changes, significantly improving the recognition robustness across different vertical views. Experimental results show that our CVVNet achieves state-of-the-art performance, with $8.6\%$ improvement on DroneGait and $2\%$ on Gait3D compared with the best existing methods.
A Versatile Framework for Analyzing Galaxy Image Data by Implanting Human-in-the-loop on a Large Vision Model
May 17, 2024The exponential growth of astronomical datasets provides an unprecedented opportunity for humans to gain insight into the Universe. However, effectively analyzing this vast amount of data poses a significant challenge. Astronomers are turning to deep learning techniques to address this, but the methods are limited by their specific training sets, leading to considerable duplicate workloads too. Hence, as an example to present how to overcome the issue, we built a framework for general analysis of galaxy images, based on a large vision model (LVM) plus downstream tasks (DST), including galaxy morphological classification, image restoration, object detection, parameter extraction, and more. Considering the low signal-to-noise ratio of galaxy images and the imbalanced distribution of galaxy categories, we have incorporated a Human-in-the-loop (HITL) module into our large vision model, which leverages human knowledge to enhance the reliability and interpretability of processing galaxy images interactively. The proposed framework exhibits notable few-shot learning capabilities and versatile adaptability to all the abovementioned tasks on galaxy images in the DESI legacy imaging surveys. Expressly, for object detection, trained by 1000 data points, our DST upon the LVM achieves an accuracy of 96.7%, while ResNet50 plus Mask R-CNN gives an accuracy of 93.1%; for morphology classification, to obtain AUC ~0.9, LVM plus DST and HITL only requests 1/50 training sets compared to ResNet18. Expectedly, multimodal data can be integrated similarly, which opens up possibilities for conducting joint analyses with datasets spanning diverse domains in the era of multi-message astronomy.
Multi-Prompt Fine-Tuning of Foundation Models for Enhanced Medical Image Segmentation
Oct 03, 2023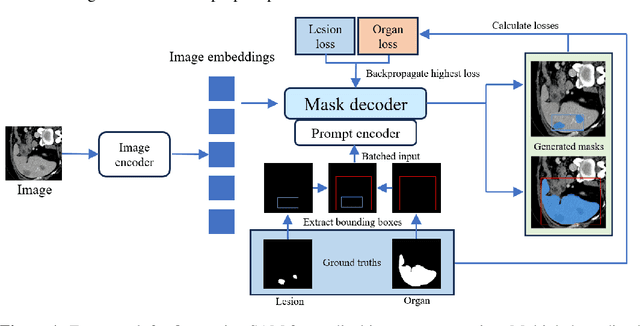


The Segment Anything Model (SAM) is a powerful foundation model that introduced revolutionary advancements in natural image segmentation. However, its performance remains sub-optimal when delineating the intricate structure of biomedical images, where multiple organs and tissues intertwine in a single image. In this study, we introduce a novel fine-tuning framework that leverages SAM's ability to bundle and process multiple prompts per image and seeks to improve SAM's performance in medical images. We first curated a medical image dataset that consists of CT scans of lesions in various organs, each with two annotations for organs and lesions respectively. Then, we fine-tuned SAM's mask decoder within our framework by batching both bounding boxes generated from ground truth masks as reference. The batched prompt strategy we introduced not only addresses the inherent complexity and ambiguity often found in medical images but also substantially enhances performance metrics when applied onto a wide range of segmentation tasks.
Galaxy Image Classification using Hierarchical Data Learning with Weighted Sampling and Label Smoothing
Dec 20, 2022With the development of a series of Galaxy sky surveys in recent years, the observations increased rapidly, which makes the research of machine learning methods for galaxy image recognition a hot topic. Available automatic galaxy image recognition researches are plagued by the large differences in similarity between categories, the imbalance of data between different classes, and the discrepancy between the discrete representation of Galaxy classes and the essentially gradual changes from one morphological class to the adjacent class (DDRGC). These limitations have motivated several astronomers and machine learning experts to design projects with improved galaxy image recognition capabilities. Therefore, this paper proposes a novel learning method, ``Hierarchical Imbalanced data learning with Weighted sampling and Label smoothing" (HIWL). The HIWL consists of three key techniques respectively dealing with the above-mentioned three problems: (1) Designed a hierarchical galaxy classification model based on an efficient backbone network; (2) Utilized a weighted sampling scheme to deal with the imbalance problem; (3) Adopted a label smoothing technique to alleviate the DDRGC problem. We applied this method to galaxy photometric images from the Galaxy Zoo-The Galaxy Challenge, exploring the recognition of completely round smooth, in between smooth, cigar-shaped, edge-on and spiral. The overall classification accuracy is 96.32\%, and some superiorities of the HIWL are shown based on recall, precision, and F1-Score in comparing with some related works. In addition, we also explored the visualization of the galaxy image features and model attention to understand the foundations of the proposed scheme.
Estimation of stellar atmospheric parameters from LAMOST DR8 low-resolution spectra with 20$\leq$SNR$<$30
Apr 13, 2022
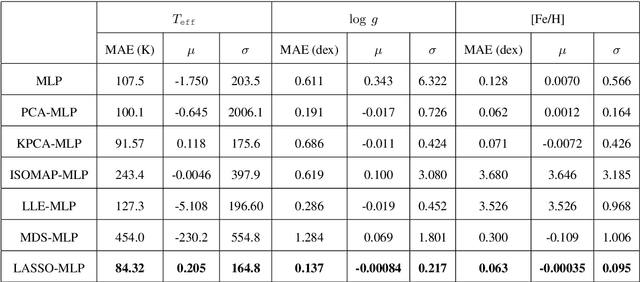

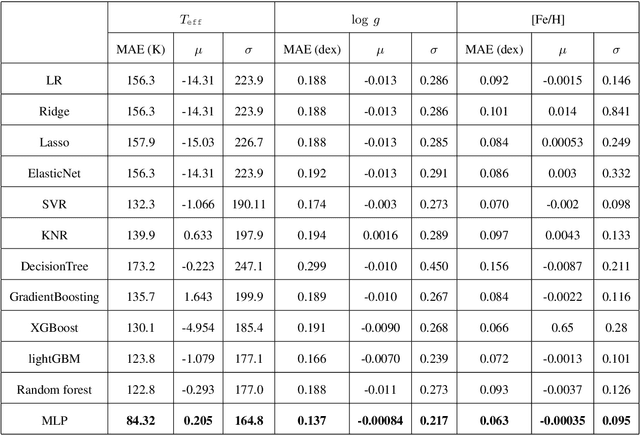
The accuracy of the estimated stellar atmospheric parameter decreases evidently with the decreasing of spectral signal-to-noise ratio (SNR) and there are a huge amount of this kind observations, especially in case of SNR$<$30. Therefore, it is helpful to improve the parameter estimation performance for these spectra and this work studied the ($T_\texttt{eff}, \log~g$, [Fe/H]) estimation problem for LAMOST DR8 low-resolution spectra with 20$\leq$SNR$<$30. We proposed a data-driven method based on machine learning techniques. Firstly, this scheme detected stellar atmospheric parameter-sensitive features from spectra by the Least Absolute Shrinkage and Selection Operator (LASSO), rejected ineffective data components and irrelevant data. Secondly, a Multi-layer Perceptron (MLP) method was used to estimate stellar atmospheric parameters from the LASSO features. Finally, the performance of the LASSO-MLP was evaluated by computing and analyzing the consistency between its estimation and the reference from the APOGEE (Apache Point Observatory Galactic Evolution Experiment) high-resolution spectra. Experiments show that the Mean Absolute Errors (MAE) of $T_\texttt{eff}, \log~g$, [Fe/H] are reduced from the LASP (137.6 K, 0.195 dex, 0.091 dex) to LASSO-MLP (84.32 K, 0.137 dex, 0.063 dex), which indicate evident improvements on stellar atmospheric parameter estimation. In addition, this work estimated the stellar atmospheric parameters for 1,162,760 low-resolution spectra with 20$\leq$SNR$<$30 from LAMOST DR8 using LASSO-MLP, and released the estimation catalog, learned model, experimental code, trained model, training data and test data for scientific exploration and algorithm study.
* 16 pages, 6 figures, 4 tables
Pulsars Detection by Machine Learning with Very Few Features
Feb 20, 2020
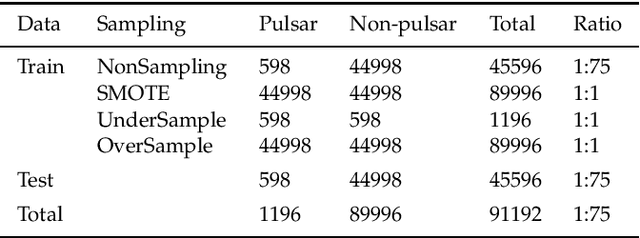


It is an active topic to investigate the schemes based on machine learning (ML) methods for detecting pulsars as the data volume growing exponentially in modern surveys. To improve the detection performance, input features into an ML model should be investigated specifically. In the existing pulsar detection researches based on ML methods, there are mainly two kinds of feature designs: the empirical features and statistical features. Due to the combinational effects from multiple features, however, there exist some redundancies and even irrelevant components in the available features, which can reduce the accuracy of a pulsar detection model. Therefore, it is essential to select a subset of relevant features from a set of available candidate features and known as {\itshape feature selection.} In this work, two feature selection algorithms ----\textit{Grid Search} (GS) and \textit{Recursive Feature Elimination} (RFE)---- are proposed to improve the detection performance by removing the redundant and irrelevant features. The algorithms were evaluated on the Southern High Time Resolution University survey (HTRU-S) with five pulsar detection models. The experimental results verify the effectiveness and efficiency of our proposed feature selection algorithms. By the GS, a model with only two features reach a recall rate as high as 99\% and a false positive rate (FPR) as low as 0.65\%; By the RFE, another model with only three features achieves a recall rate 99\% and an FPR of 0.16\% in pulsar candidates classification. Furthermore, this work investigated the number of features required as well as the misclassified pulsars by our models.
Linearly Supporting Feature Extraction For Automated Estimation Of Stellar Atmospheric Parameters
Apr 10, 2015
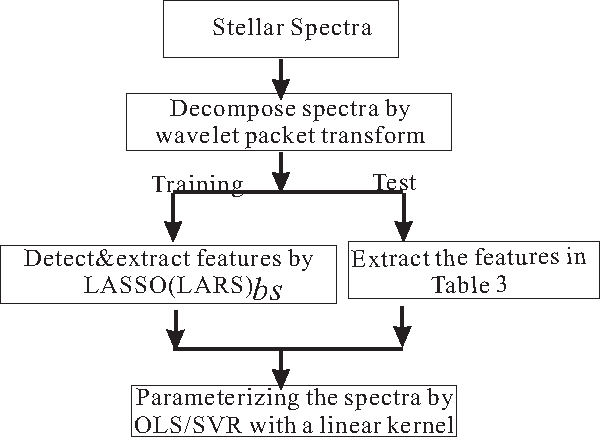
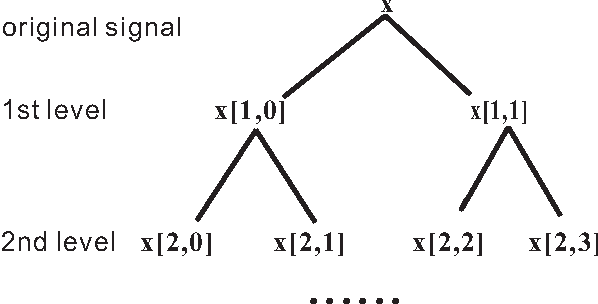
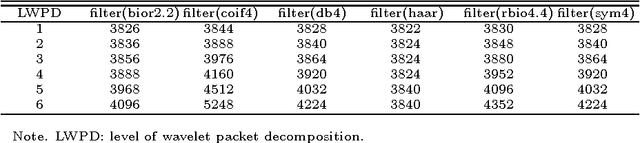
We describe a scheme to extract linearly supporting (LSU) features from stellar spectra to automatically estimate the atmospheric parameters $T_{eff}$, log$~g$, and [Fe/H]. "Linearly supporting" means that the atmospheric parameters can be accurately estimated from the extracted features through a linear model. The successive steps of the process are as follow: first, decompose the spectrum using a wavelet packet (WP) and represent it by the derived decomposition coefficients; second, detect representative spectral features from the decomposition coefficients using the proposed method Least Absolute Shrinkage and Selection Operator (LARS)$_{bs}$; third, estimate the atmospheric parameters $T_{eff}$, log$~g$, and [Fe/H] from the detected features using a linear regression method. One prominent characteristic of this scheme is its ability to evaluate quantitatively the contribution of each detected feature to the atmospheric parameter estimate and also to trace back the physical significance of that feature. This work also shows that the usefulness of a component depends on both wavelength and frequency. The proposed scheme has been evaluated on both real spectra from the Sloan Digital Sky Survey (SDSS)/SEGUE and synthetic spectra calculated from Kurucz's NEWODF models. On real spectra, we extracted 23 features to estimate $T_{eff}$, 62 features for log$~g$, and 68 features for [Fe/H]. Test consistencies between our estimates and those provided by the Spectroscopic Sarameter Pipeline of SDSS show that the mean absolute errors (MAEs) are 0.0062 dex for log$~T_{eff}$ (83 K for $T_{eff}$), 0.2345 dex for log$~g$, and 0.1564 dex for [Fe/H]. For the synthetic spectra, the MAE test accuracies are 0.0022 dex for log$~T_{eff}$ (32 K for $T_{eff}$), 0.0337 dex for log$~g$, and 0.0268 dex for [Fe/H].