 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlain Transformers are Surprisingly Powerful Link Predictors
Feb 02, 2026Link prediction is a core challenge in graph machine learning, demanding models that capture rich and complex topological dependencies. While Graph Neural Networks (GNNs) are the standard solution, state-of-the-art pipelines often rely on explicit structural heuristics or memory-intensive node embeddings -- approaches that struggle to generalize or scale to massive graphs. Emerging Graph Transformers (GTs) offer a potential alternative but often incur significant overhead due to complex structural encodings, hindering their applications to large-scale link prediction. We challenge these sophisticated paradigms with PENCIL, an encoder-only plain Transformer that replaces hand-crafted priors with attention over sampled local subgraphs, retaining the scalability and hardware efficiency of standard Transformers. Through experimental and theoretical analysis, we show that PENCIL extracts richer structural signals than GNNs, implicitly generalizing a broad class of heuristics and subgraph-based expressivity. Empirically, PENCIL outperforms heuristic-informed GNNs and is far more parameter-efficient than ID-embedding--based alternatives, while remaining competitive across diverse benchmarks -- even without node features. Our results challenge the prevailing reliance on complex engineering techniques, demonstrating that simple design choices are potentially sufficient to achieve the same capabilities.
Towards Agentic Intelligence for Materials Science
Jan 29, 2026The convergence of artificial intelligence and materials science presents a transformative opportunity, but achieving true acceleration in discovery requires moving beyond task-isolated, fine-tuned models toward agentic systems that plan, act, and learn across the full discovery loop. This survey advances a unique pipeline-centric view that spans from corpus curation and pretraining, through domain adaptation and instruction tuning, to goal-conditioned agents interfacing with simulation and experimental platforms. Unlike prior reviews, we treat the entire process as an end-to-end system to be optimized for tangible discovery outcomes rather than proxy benchmarks. This perspective allows us to trace how upstream design choices-such as data curation and training objectives-can be aligned with downstream experimental success through effective credit assignment. To bridge communities and establish a shared frame of reference, we first present an integrated lens that aligns terminology, evaluation, and workflow stages across AI and materials science. We then analyze the field through two focused lenses: From the AI perspective, the survey details LLM strengths in pattern recognition, predictive analytics, and natural language processing for literature mining, materials characterization, and property prediction; from the materials science perspective, it highlights applications in materials design, process optimization, and the acceleration of computational workflows via integration with external tools (e.g., DFT, robotic labs). Finally, we contrast passive, reactive approaches with agentic design, cataloging current contributions while motivating systems that pursue long-horizon goals with autonomy, memory, and tool use. This survey charts a practical roadmap towards autonomous, safety-aware LLM agents aimed at discovering novel and useful materials.
Are Multimodal Embeddings Truly Beneficial for Recommendation? A Deep Dive into Whole vs. Individual Modalities
Aug 10, 2025Multimodal recommendation (MMRec) has emerged as a mainstream paradigm, typically leveraging text and visual embeddings extracted from pre-trained models such as Sentence-BERT, Vision Transformers, and ResNet. This approach is founded on the intuitive assumption that incorporating multimodal embeddings can enhance recommendation performance. However, despite its popularity, this assumption lacks comprehensive empirical verification. This presents a critical research gap. To address it, we pose the central research question of this paper: Are multimodal embeddings truly beneficial for recommendation? To answer this question, we conduct a large-scale empirical study examining the role of text and visual embeddings in modern MMRec models, both as a whole and individually. Specifically, we pose two key research questions: (1) Do multimodal embeddings as a whole improve recommendation performance? (2) Is each individual modality - text and image - useful when used alone? To isolate the effect of individual modalities - text or visual - we employ a modality knockout strategy by setting the corresponding embeddings to either constant values or random noise. To ensure the scale and comprehensiveness of our study, we evaluate 14 widely used state-of-the-art MMRec models. Our findings reveal that: (1) multimodal embeddings generally enhance recommendation performance - particularly when integrated through more sophisticated graph-based fusion models. Surprisingly, commonly adopted baseline models with simple fusion schemes, such as VBPR and BM3, show only limited gains. (2) The text modality alone achieves performance comparable to the full multimodal setting in most cases, whereas the image modality alone does not. These results offer foundational insights and practical guidance for the MMRec community. We will release our code and datasets to facilitate future research.
A Scalable Pretraining Framework for Link Prediction with Efficient Adaptation
Aug 06, 2025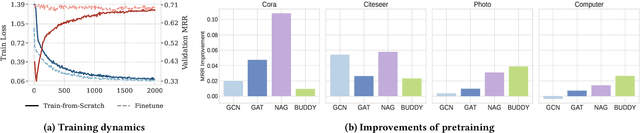

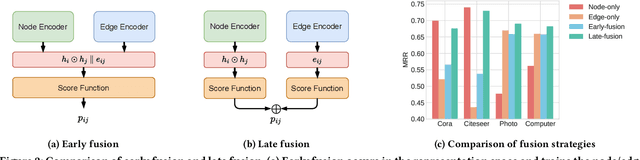

Link Prediction (LP) is a critical task in graph machine learning. While Graph Neural Networks (GNNs) have significantly advanced LP performance recently, existing methods face key challenges including limited supervision from sparse connectivity, sensitivity to initialization, and poor generalization under distribution shifts. We explore pretraining as a solution to address these challenges. Unlike node classification, LP is inherently a pairwise task, which requires the integration of both node- and edge-level information. In this work, we present the first systematic study on the transferability of these distinct modules and propose a late fusion strategy to effectively combine their outputs for improved performance. To handle the diversity of pretraining data and avoid negative transfer, we introduce a Mixture-of-Experts (MoE) framework that captures distinct patterns in separate experts, facilitating seamless application of the pretrained model on diverse downstream datasets. For fast adaptation, we develop a parameter-efficient tuning strategy that allows the pretrained model to adapt to unseen datasets with minimal computational overhead. Experiments on 16 datasets across two domains demonstrate the effectiveness of our approach, achieving state-of-the-art performance on low-resource link prediction while obtaining competitive results compared to end-to-end trained methods, with over 10,000x lower computational overhead.
Seek-CAD: A Self-refined Generative Modeling for 3D Parametric CAD Using Local Inference via DeepSeek
May 23, 2025The advent of Computer-Aided Design (CAD) generative modeling will significantly transform the design of industrial products. The recent research endeavor has extended into the realm of Large Language Models (LLMs). In contrast to fine-tuning methods, training-free approaches typically utilize the advanced closed-source LLMs, thereby offering enhanced flexibility and efficiency in the development of AI agents for generating CAD parametric models. However, the substantial cost and limitations of local deployment of the top-tier closed-source LLMs pose challenges in practical applications. The Seek-CAD is the pioneer exploration of locally deployed open-source inference LLM DeepSeek-R1 for CAD parametric model generation with a training-free methodology. This study is the first investigation to incorporate both visual and Chain-of-Thought (CoT) feedback within the self-refinement mechanism for generating CAD models. Specifically, the initial generated parametric CAD model is rendered into a sequence of step-wise perspective images, which are subsequently processed by a Vision Language Model (VLM) alongside the corresponding CoTs derived from DeepSeek-R1 to assess the CAD model generation. Then, the feedback is utilized by DeepSeek-R1 to refine the initial generated model for the next round of generation. Moreover, we present an innovative 3D CAD model dataset structured around the SSR (Sketch, Sketch-based feature, and Refinements) triple design paradigm. This dataset encompasses a wide range of CAD commands, thereby aligning effectively with industrial application requirements and proving suitable for the generation of LLMs. Extensive experiments validate the effectiveness of Seek-CAD under various metrics.
Higher-order Structure Boosts Link Prediction on Temporal Graphs
May 21, 2025Temporal Graph Neural Networks (TGNNs) have gained growing attention for modeling and predicting structures in temporal graphs. However, existing TGNNs primarily focus on pairwise interactions while overlooking higher-order structures that are integral to link formation and evolution in real-world temporal graphs. Meanwhile, these models often suffer from efficiency bottlenecks, further limiting their expressive power. To tackle these challenges, we propose a Higher-order structure Temporal Graph Neural Network, which incorporates hypergraph representations into temporal graph learning. In particular, we develop an algorithm to identify the underlying higher-order structures, enhancing the model's ability to capture the group interactions. Furthermore, by aggregating multiple edge features into hyperedge representations, HTGN effectively reduces memory cost during training. We theoretically demonstrate the enhanced expressiveness of our approach and validate its effectiveness and efficiency through extensive experiments on various real-world temporal graphs. Experimental results show that HTGN achieves superior performance on dynamic link prediction while reducing memory costs by up to 50\% compared to existing methods.
Accurate Tracking of Arabidopsis Root Cortex Cell Nuclei in 3D Time-Lapse Microscopy Images Based on Genetic Algorithm
Apr 17, 2025Arabidopsis is a widely used model plant to gain basic knowledge on plant physiology and development. Live imaging is an important technique to visualize and quantify elemental processes in plant development. To uncover novel theories underlying plant growth and cell division, accurate cell tracking on live imaging is of utmost importance. The commonly used cell tracking software, TrackMate, adopts tracking-by-detection fashion, which applies Laplacian of Gaussian (LoG) for blob detection, and Linear Assignment Problem (LAP) tracker for tracking. However, they do not perform sufficiently when cells are densely arranged. To alleviate the problems mentioned above, we propose an accurate tracking method based on Genetic algorithm (GA) using knowledge of Arabidopsis root cellular patterns and spatial relationship among volumes. Our method can be described as a coarse-to-fine method, in which we first conducted relatively easy line-level tracking of cell nuclei, then performed complicated nuclear tracking based on known linear arrangement of cell files and their spatial relationship between nuclei. Our method has been evaluated on a long-time live imaging dataset of Arabidopsis root tips, and with minor manual rectification, it accurately tracks nuclei. To the best of our knowledge, this research represents the first successful attempt to address a long-standing problem in the field of time-lapse microscopy in the root meristem by proposing an accurate tracking method for Arabidopsis root nuclei.
HoneyComb: A Flexible LLM-Based Agent System for Materials Science
Aug 29, 2024



The emergence of specialized large language models (LLMs) has shown promise in addressing complex tasks for materials science. Many LLMs, however, often struggle with distinct complexities of material science tasks, such as materials science computational tasks, and often rely heavily on outdated implicit knowledge, leading to inaccuracies and hallucinations. To address these challenges, we introduce HoneyComb, the first LLM-based agent system specifically designed for materials science. HoneyComb leverages a novel, high-quality materials science knowledge base (MatSciKB) and a sophisticated tool hub (ToolHub) to enhance its reasoning and computational capabilities tailored to materials science. MatSciKB is a curated, structured knowledge collection based on reliable literature, while ToolHub employs an Inductive Tool Construction method to generate, decompose, and refine API tools for materials science. Additionally, HoneyComb leverages a retriever module that adaptively selects the appropriate knowledge source or tools for specific tasks, thereby ensuring accuracy and relevance. Our results demonstrate that HoneyComb significantly outperforms baseline models across various tasks in materials science, effectively bridging the gap between current LLM capabilities and the specialized needs of this domain. Furthermore, our adaptable framework can be easily extended to other scientific domains, highlighting its potential for broad applicability in advancing scientific research and applications.
Do Neural Scaling Laws Exist on Graph Self-Supervised Learning?
Aug 20, 2024



Self-supervised learning~(SSL) is essential to obtain foundation models in NLP and CV domains via effectively leveraging knowledge in large-scale unlabeled data. The reason for its success is that a suitable SSL design can help the model to follow the neural scaling law, i.e., the performance consistently improves with increasing model and dataset sizes. However, it remains a mystery whether existing SSL in the graph domain can follow the scaling behavior toward building Graph Foundation Models~(GFMs) with large-scale pre-training. In this study, we examine whether existing graph SSL techniques can follow the neural scaling behavior with the potential to serve as the essential component for GFMs. Our benchmark includes comprehensive SSL technique implementations with analysis conducted on both the conventional SSL setting and many new settings adopted in other domains. Surprisingly, despite the SSL loss continuously decreasing, no existing graph SSL techniques follow the neural scaling behavior on the downstream performance. The model performance only merely fluctuates on different data scales and model scales. Instead of the scales, the key factors influencing the performance are the choices of model architecture and pretext task design. This paper examines existing SSL techniques for the feasibility of Graph SSL techniques in developing GFMs and opens a new direction for graph SSL design with the new evaluation prototype. Our code implementation is available online to ease reproducibility on https://github.com/GraphSSLScaling/GraphSSLScaling.
Multitask and Multimodal Neural Tuning for Large Models
Aug 06, 2024



In recent years, large-scale multimodal models have demonstrated impressive capabilities across various domains. However, enabling these models to effectively perform multiple multimodal tasks simultaneously remains a significant challenge. To address this, we introduce a novel tuning method called neural tuning, designed to handle diverse multimodal tasks concurrently, including reasoning segmentation, referring segmentation, image captioning, and text-to-image generation. Neural tuning emulates sparse distributed representation in human brain, where only specific subsets of neurons are activated for each task. Additionally, we present a new benchmark, MMUD, where each sample is annotated with multiple task labels. By applying neural tuning to pretrained large models on the MMUD benchmark, we achieve simultaneous task handling in a streamlined and efficient manner. All models, code, and datasets will be publicly available after publication, facilitating further research and development in this field.