 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Latent Representation Tuning for Image-text Classification
Paper and Code
Jun 10, 2024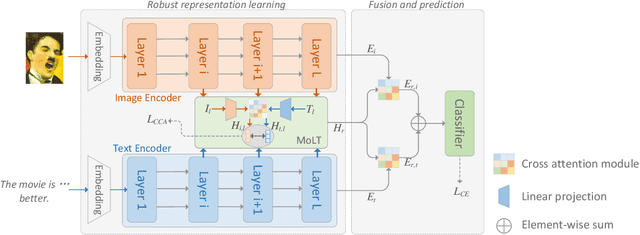



Large models have demonstrated exceptional generalization capabilities in computer vision and natural language processing. Recent efforts have focused on enhancing these models with multimodal processing abilities. However, addressing the challenges posed by scenarios where one modality is absent remains a significant hurdle. In response to this issue, we propose a robust latent representation tuning method for large models. Specifically, our approach introduces a modality latent translation module to maximize the correlation between modalities. Following this, a newly designed fusion module is employed to facilitate information interaction between the modalities. In this framework, not only are common semantics refined during training, but the method also yields robust representations in the absence of one modality. Importantly, our method maintains the frozen state of the image and text foundation models to preserve their abilities acquired through large-scale pretraining. We conduct experiments on several public datasets, and the results underscore the effectiveness of our proposed method.