 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Pretraining Framework for Link Prediction with Efficient Adaptation
Aug 06, 2025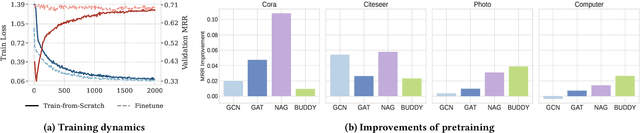

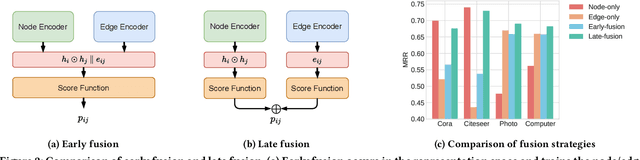

Link Prediction (LP) is a critical task in graph machine learning. While Graph Neural Networks (GNNs) have significantly advanced LP performance recently, existing methods face key challenges including limited supervision from sparse connectivity, sensitivity to initialization, and poor generalization under distribution shifts. We explore pretraining as a solution to address these challenges. Unlike node classification, LP is inherently a pairwise task, which requires the integration of both node- and edge-level information. In this work, we present the first systematic study on the transferability of these distinct modules and propose a late fusion strategy to effectively combine their outputs for improved performance. To handle the diversity of pretraining data and avoid negative transfer, we introduce a Mixture-of-Experts (MoE) framework that captures distinct patterns in separate experts, facilitating seamless application of the pretrained model on diverse downstream datasets. For fast adaptation, we develop a parameter-efficient tuning strategy that allows the pretrained model to adapt to unseen datasets with minimal computational overhead. Experiments on 16 datasets across two domains demonstrate the effectiveness of our approach, achieving state-of-the-art performance on low-resource link prediction while obtaining competitive results compared to end-to-end trained methods, with over 10,000x lower computational overhead.
Higher-order Structure Boosts Link Prediction on Temporal Graphs
May 21, 2025Temporal Graph Neural Networks (TGNNs) have gained growing attention for modeling and predicting structures in temporal graphs. However, existing TGNNs primarily focus on pairwise interactions while overlooking higher-order structures that are integral to link formation and evolution in real-world temporal graphs. Meanwhile, these models often suffer from efficiency bottlenecks, further limiting their expressive power. To tackle these challenges, we propose a Higher-order structure Temporal Graph Neural Network, which incorporates hypergraph representations into temporal graph learning. In particular, we develop an algorithm to identify the underlying higher-order structures, enhancing the model's ability to capture the group interactions. Furthermore, by aggregating multiple edge features into hyperedge representations, HTGN effectively reduces memory cost during training. We theoretically demonstrate the enhanced expressiveness of our approach and validate its effectiveness and efficiency through extensive experiments on various real-world temporal graphs. Experimental results show that HTGN achieves superior performance on dynamic link prediction while reducing memory costs by up to 50\% compared to existing methods.
Unveiling Mode Connectivity in Graph Neural Networks
Feb 18, 2025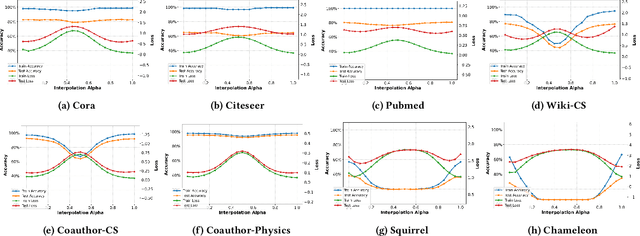
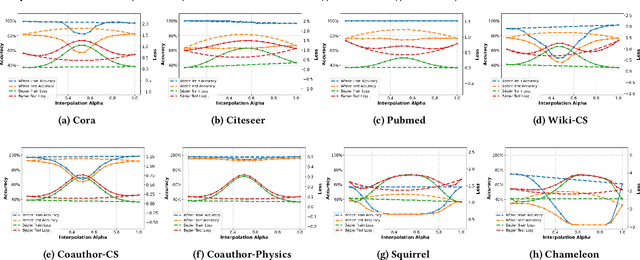
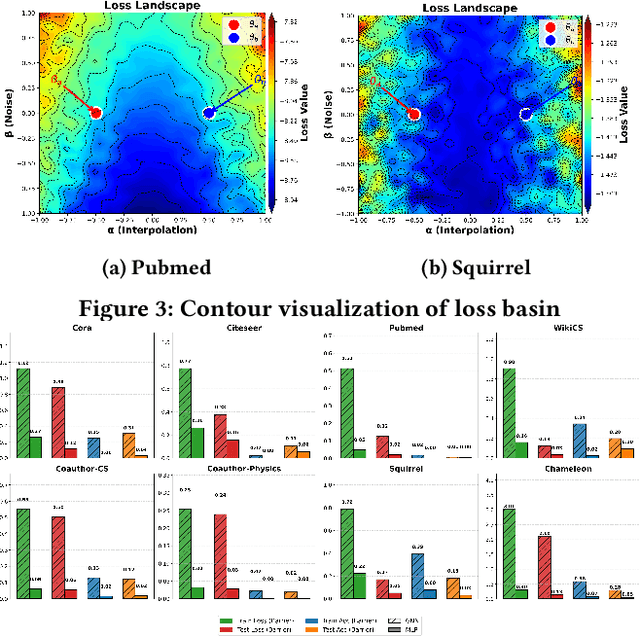
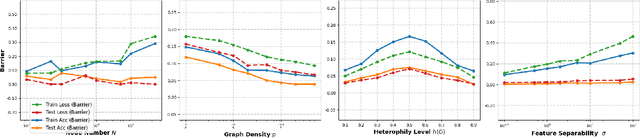
A fundamental challenge in understanding graph neural networks (GNNs) lies in characterizing their optimization dynamics and loss landscape geometry, critical for improving interpretability and robustness. While mode connectivity, a lens for analyzing geometric properties of loss landscapes has proven insightful for other deep learning architectures, its implications for GNNs remain unexplored. This work presents the first investigation of mode connectivity in GNNs. We uncover that GNNs exhibit distinct non-linear mode connectivity, diverging from patterns observed in fully-connected networks or CNNs. Crucially, we demonstrate that graph structure, rather than model architecture, dominates this behavior, with graph properties like homophily correlating with mode connectivity patterns. We further establish a link between mode connectivity and generalization, proposing a generalization bound based on loss barriers and revealing its utility as a diagnostic tool. Our findings further bridge theoretical insights with practical implications: they rationalize domain alignment strategies in graph learning and provide a foundation for refining GNN training paradigms.
One Model for One Graph: A New Perspective for Pretraining with Cross-domain Graphs
Nov 30, 2024



Graph Neural Networks (GNNs) have emerged as a powerful tool to capture intricate network patterns, achieving success across different domains. However, existing GNNs require careful domain-specific architecture designs and training from scratch on each dataset, leading to an expertise-intensive process with difficulty in generalizing across graphs from different domains. Therefore, it can be hard for practitioners to infer which GNN model can generalize well to graphs from their domains. To address this challenge, we propose a novel cross-domain pretraining framework, "one model for one graph," which overcomes the limitations of previous approaches that failed to use a single GNN to capture diverse graph patterns across domains with significant gaps. Specifically, we pretrain a bank of expert models, with each one corresponding to a specific dataset. When inferring to a new graph, gating functions choose a subset of experts to effectively integrate prior model knowledge while avoiding negative transfer. Extensive experiments consistently demonstrate the superiority of our proposed method on both link prediction and node classification tasks.
Do Neural Scaling Laws Exist on Graph Self-Supervised Learning?
Aug 20, 2024



Self-supervised learning~(SSL) is essential to obtain foundation models in NLP and CV domains via effectively leveraging knowledge in large-scale unlabeled data. The reason for its success is that a suitable SSL design can help the model to follow the neural scaling law, i.e., the performance consistently improves with increasing model and dataset sizes. However, it remains a mystery whether existing SSL in the graph domain can follow the scaling behavior toward building Graph Foundation Models~(GFMs) with large-scale pre-training. In this study, we examine whether existing graph SSL techniques can follow the neural scaling behavior with the potential to serve as the essential component for GFMs. Our benchmark includes comprehensive SSL technique implementations with analysis conducted on both the conventional SSL setting and many new settings adopted in other domains. Surprisingly, despite the SSL loss continuously decreasing, no existing graph SSL techniques follow the neural scaling behavior on the downstream performance. The model performance only merely fluctuates on different data scales and model scales. Instead of the scales, the key factors influencing the performance are the choices of model architecture and pretext task design. This paper examines existing SSL techniques for the feasibility of Graph SSL techniques in developing GFMs and opens a new direction for graph SSL design with the new evaluation prototype. Our code implementation is available online to ease reproducibility on https://github.com/GraphSSLScaling/GraphSSLScaling.
Robust Simultaneous Multislice MRI Reconstruction Using Deep Generative Priors
Jul 31, 2024



Simultaneous multislice (SMS) imaging is a powerful technique for accelerating magnetic resonance imaging (MRI) acquisitions. However, SMS reconstruction remains challenging due to the complex signal interactions between and within the excited slices. This study presents a robust SMS MRI reconstruction method using deep generative priors. Starting from Gaussian noise, we leverage denoising diffusion probabilistic models (DDPM) to gradually recover the individual slices through reverse diffusion iterations while imposing data consistency from the measured k-space under readout concatenation framework. The posterior sampling procedure is designed such that the DDPM training can be performed on single-slice images without special adjustments for SMS tasks. Additionally, our method integrates a low-frequency enhancement (LFE) module to address a practical issue that SMS-accelerated fast spin echo (FSE) and echo-planar imaging (EPI) sequences cannot easily embed autocalibration signals. Extensive experiments demonstrate that our approach consistently outperforms existing methods and generalizes well to unseen datasets. The code is available at https://github.com/Solor-pikachu/ROGER after the review process.
A Pure Transformer Pretraining Framework on Text-attributed Graphs
Jun 19, 2024



Pretraining plays a pivotal role in acquiring generalized knowledge from large-scale data, achieving remarkable successes as evidenced by large models in CV and NLP. However, progress in the graph domain remains limited due to fundamental challenges such as feature heterogeneity and structural heterogeneity. Recently, increasing efforts have been made to enhance node feature quality with Large Language Models (LLMs) on text-attributed graphs (TAGs), demonstrating superiority to traditional bag-of-words or word2vec techniques. These high-quality node features reduce the previously critical role of graph structure, resulting in a modest performance gap between Graph Neural Networks (GNNs) and structure-agnostic Multi-Layer Perceptrons (MLPs). Motivated by this, we introduce a feature-centric pretraining perspective by treating graph structure as a prior and leveraging the rich, unified feature space to learn refined interaction patterns that generalizes across graphs. Our framework, Graph Sequence Pretraining with Transformer (GSPT), samples node contexts through random walks and employs masked feature reconstruction to capture pairwise proximity in the LLM-unified feature space using a standard Transformer. By utilizing unified text representations rather than varying structures, our framework achieves significantly better transferability among graphs within the same domain. GSPT can be easily adapted to both node classification and link prediction, demonstrating promising empirical success on various datasets.
Text-space Graph Foundation Models: Comprehensive Benchmarks and New Insights
Jun 15, 2024



Given the ubiquity of graph data and its applications in diverse domains, building a Graph Foundation Model (GFM) that can work well across different graphs and tasks with a unified backbone has recently garnered significant interests. A major obstacle to achieving this goal stems from the fact that graphs from different domains often exhibit diverse node features. Inspired by multi-modal models that align different modalities with natural language, the text has recently been adopted to provide a unified feature space for diverse graphs. Despite the great potential of these text-space GFMs, current research in this field is hampered by two problems. First, the absence of a comprehensive benchmark with unified problem settings hinders a clear understanding of the comparative effectiveness and practical value of different text-space GFMs. Second, there is a lack of sufficient datasets to thoroughly explore the methods' full potential and verify their effectiveness across diverse settings. To address these issues, we conduct a comprehensive benchmark providing novel text-space datasets and comprehensive evaluation under unified problem settings. Empirical results provide new insights and inspire future research directions. Our code and data are publicly available from \url{https://github.com/CurryTang/TSGFM}.
Neural Scaling Laws on Graphs
Feb 03, 2024Deep graph models (e.g., graph neural networks and graph transformers) have become important techniques for leveraging knowledge across various types of graphs. Yet, the scaling properties of deep graph models have not been systematically investigated, casting doubt on the feasibility of achieving large graph models through enlarging the model and dataset sizes. In this work, we delve into neural scaling laws on graphs from both model and data perspectives. We first verify the validity of such laws on graphs, establishing formulations to describe the scaling behaviors. For model scaling, we investigate the phenomenon of scaling law collapse and identify overfitting as the potential reason. Moreover, we reveal that the model depth of deep graph models can impact the model scaling behaviors, which differ from observations in other domains such as CV and NLP. For data scaling, we suggest that the number of graphs can not effectively metric the graph data volume in scaling law since the sizes of different graphs are highly irregular. Instead, we reform the data scaling law with the number of edges as the metric to address the irregular graph sizes. We further demonstrate the reformed law offers a unified view of the data scaling behaviors for various fundamental graph tasks including node classification, link prediction, and graph classification. This work provides valuable insights into neural scaling laws on graphs, which can serve as an essential step toward large graph models.