 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Expressive Encoders Necessary for Discrete Graph Generation?
Mar 09, 2026Discrete graph generation has emerged as a powerful paradigm for modeling graph data, often relying on highly expressive neural backbones such as transformers or higher-order architectures. We revisit this design choice by introducing GenGNN, a modular message-passing framework for graph generation. Diffusion models with GenGNN achieve more than 90% validity on Tree and Planar datasets, within margins of graph transformers, at 2-5x faster inference speed. For molecule generation, DiGress with a GenGNN backbone achieves 99.49% Validity. A systematic ablation study shows the benefit provided by each GenGNN component, indicating the need for residual connections to mitigate oversmoothing on complicated graph-structure. Through scaling analyses, we apply a principled metric-space view to investigate learned diffusion representations and uncover whether GNNs can be expressive neural backbones for discrete diffusion.
A Scalable Pretraining Framework for Link Prediction with Efficient Adaptation
Aug 06, 2025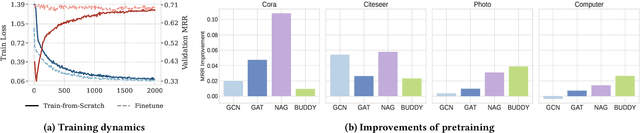

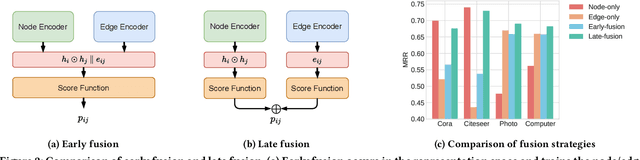

Link Prediction (LP) is a critical task in graph machine learning. While Graph Neural Networks (GNNs) have significantly advanced LP performance recently, existing methods face key challenges including limited supervision from sparse connectivity, sensitivity to initialization, and poor generalization under distribution shifts. We explore pretraining as a solution to address these challenges. Unlike node classification, LP is inherently a pairwise task, which requires the integration of both node- and edge-level information. In this work, we present the first systematic study on the transferability of these distinct modules and propose a late fusion strategy to effectively combine their outputs for improved performance. To handle the diversity of pretraining data and avoid negative transfer, we introduce a Mixture-of-Experts (MoE) framework that captures distinct patterns in separate experts, facilitating seamless application of the pretrained model on diverse downstream datasets. For fast adaptation, we develop a parameter-efficient tuning strategy that allows the pretrained model to adapt to unseen datasets with minimal computational overhead. Experiments on 16 datasets across two domains demonstrate the effectiveness of our approach, achieving state-of-the-art performance on low-resource link prediction while obtaining competitive results compared to end-to-end trained methods, with over 10,000x lower computational overhead.
Subgraph Generation for Generalizing on Out-of-Distribution Links
Jul 15, 2025Graphs Neural Networks (GNNs) demonstrate high-performance on the link prediction (LP) task. However, these models often rely on all dataset samples being drawn from the same distribution. In addition, graph generative models (GGMs) show a pronounced ability to generate novel output graphs. Despite this, GGM applications remain largely limited to domain-specific tasks. To bridge this gap, we propose FLEX as a GGM framework which leverages two mechanism: (1) structurally-conditioned graph generation, and (2) adversarial co-training between an auto-encoder and GNN. As such, FLEX ensures structural-alignment between sample distributions to enhance link-prediction performance in out-of-distribution (OOD) scenarios. Notably, FLEX does not require expert knowledge to function in different OOD scenarios. Numerous experiments are conducted in synthetic and real-world OOD settings to demonstrate FLEX's performance-enhancing ability, with further analysis for understanding the effects of graph data augmentation on link structures. The source code is available here: https://github.com/revolins/FlexOOD.
Higher-order Structure Boosts Link Prediction on Temporal Graphs
May 21, 2025Temporal Graph Neural Networks (TGNNs) have gained growing attention for modeling and predicting structures in temporal graphs. However, existing TGNNs primarily focus on pairwise interactions while overlooking higher-order structures that are integral to link formation and evolution in real-world temporal graphs. Meanwhile, these models often suffer from efficiency bottlenecks, further limiting their expressive power. To tackle these challenges, we propose a Higher-order structure Temporal Graph Neural Network, which incorporates hypergraph representations into temporal graph learning. In particular, we develop an algorithm to identify the underlying higher-order structures, enhancing the model's ability to capture the group interactions. Furthermore, by aggregating multiple edge features into hyperedge representations, HTGN effectively reduces memory cost during training. We theoretically demonstrate the enhanced expressiveness of our approach and validate its effectiveness and efficiency through extensive experiments on various real-world temporal graphs. Experimental results show that HTGN achieves superior performance on dynamic link prediction while reducing memory costs by up to 50\% compared to existing methods.
Empowering GraphRAG with Knowledge Filtering and Integration
Mar 18, 2025In recent years, large language models (LLMs) have revolutionized the field of natural language processing. However, they often suffer from knowledge gaps and hallucinations. Graph retrieval-augmented generation (GraphRAG) enhances LLM reasoning by integrating structured knowledge from external graphs. However, we identify two key challenges that plague GraphRAG:(1) Retrieving noisy and irrelevant information can degrade performance and (2)Excessive reliance on external knowledge suppresses the model's intrinsic reasoning. To address these issues, we propose GraphRAG-FI (Filtering and Integration), consisting of GraphRAG-Filtering and GraphRAG-Integration. GraphRAG-Filtering employs a two-stage filtering mechanism to refine retrieved information. GraphRAG-Integration employs a logits-based selection strategy to balance external knowledge from GraphRAG with the LLM's intrinsic reasoning,reducing over-reliance on retrievals. Experiments on knowledge graph QA tasks demonstrate that GraphRAG-FI significantly improves reasoning performance across multiple backbone models, establishing a more reliable and effective GraphRAG framework.
RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
Feb 17, 2025Retrieval-Augmented Generation (RAG) enhances the performance of LLMs across various tasks by retrieving relevant information from external sources, particularly on text-based data. For structured data, such as knowledge graphs, GraphRAG has been widely used to retrieve relevant information. However, recent studies have revealed that structuring implicit knowledge from text into graphs can benefit certain tasks, extending the application of GraphRAG from graph data to general text-based data. Despite their successful extensions, most applications of GraphRAG for text data have been designed for specific tasks and datasets, lacking a systematic evaluation and comparison between RAG and GraphRAG on widely used text-based benchmarks. In this paper, we systematically evaluate RAG and GraphRAG on well-established benchmark tasks, such as Question Answering and Query-based Summarization. Our results highlight the distinct strengths of RAG and GraphRAG across different tasks and evaluation perspectives. Inspired by these observations, we investigate strategies to integrate their strengths to improve downstream tasks. Additionally, we provide an in-depth discussion of the shortcomings of current GraphRAG approaches and outline directions for future research.
Retrieval-Augmented Generation with Graphs (GraphRAG)
Jan 08, 2025



Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.
A LLM-Powered Automatic Grading Framework with Human-Level Guidelines Optimization
Oct 03, 2024



Open-ended short-answer questions (SAGs) have been widely recognized as a powerful tool for providing deeper insights into learners' responses in the context of learning analytics (LA). However, SAGs often present challenges in practice due to the high grading workload and concerns about inconsistent assessments. With recent advancements in natural language processing (NLP), automatic short-answer grading (ASAG) offers a promising solution to these challenges. Despite this, current ASAG algorithms are often limited in generalizability and tend to be tailored to specific questions. In this paper, we propose a unified multi-agent ASAG framework, GradeOpt, which leverages large language models (LLMs) as graders for SAGs. More importantly, GradeOpt incorporates two additional LLM-based agents - the reflector and the refiner - into the multi-agent system. This enables GradeOpt to automatically optimize the original grading guidelines by performing self-reflection on its errors. Through experiments on a challenging ASAG task, namely the grading of pedagogical content knowledge (PCK) and content knowledge (CK) questions, GradeOpt demonstrates superior performance in grading accuracy and behavior alignment with human graders compared to representative baselines. Finally, comprehensive ablation studies confirm the effectiveness of the individual components designed in GradeOpt.
Sub-graph Based Diffusion Model for Link Prediction
Sep 13, 2024Denoising Diffusion Probabilistic Models (DDPMs) represent a contemporary class of generative models with exceptional qualities in both synthesis and maximizing the data likelihood. These models work by traversing a forward Markov Chain where data is perturbed, followed by a reverse process where a neural network learns to undo the perturbations and recover the original data. There have been increasing efforts exploring the applications of DDPMs in the graph domain. However, most of them have focused on the generative perspective. In this paper, we aim to build a novel generative model for link prediction. In particular, we treat link prediction between a pair of nodes as a conditional likelihood estimation of its enclosing sub-graph. With a dedicated design to decompose the likelihood estimation process via the Bayesian formula, we are able to separate the estimation of sub-graph structure and its node features. Such designs allow our model to simultaneously enjoy the advantages of inductive learning and the strong generalization capability. Remarkably, comprehensive experiments across various datasets validate that our proposed method presents numerous advantages: (1) transferability across datasets without retraining, (2) promising generalization on limited training data, and (3) robustness against graph adversarial attacks.
Towards Better Benchmark Datasets for Inductive Knowledge Graph Completion
Jun 14, 2024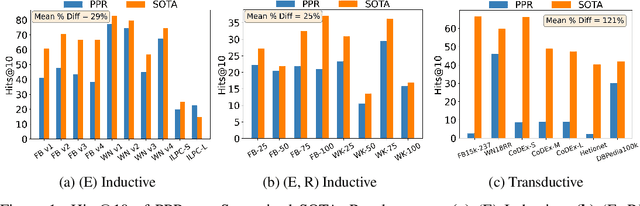

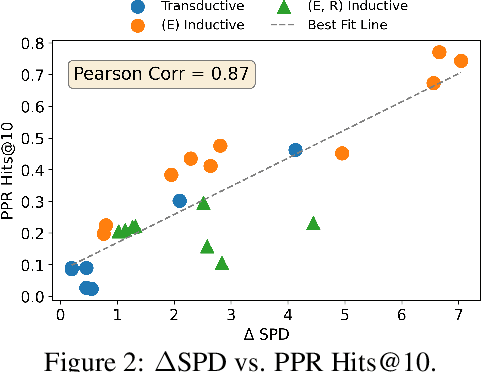
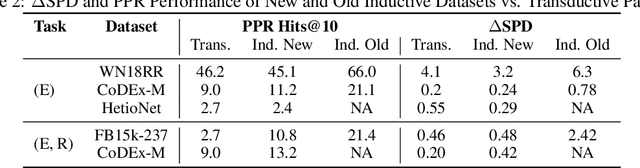
Knowledge Graph Completion (KGC) attempts to predict missing facts in a Knowledge Graph (KG). Recently, there's been an increased focus on designing KGC methods that can excel in the {\it inductive setting}, where a portion or all of the entities and relations seen in inference are unobserved during training. Numerous benchmark datasets have been proposed for inductive KGC, all of which are subsets of existing KGs used for transductive KGC. However, we find that the current procedure for constructing inductive KGC datasets inadvertently creates a shortcut that can be exploited even while disregarding the relational information. Specifically, we observe that the Personalized PageRank (PPR) score can achieve strong or near SOTA performance on most inductive datasets. In this paper, we study the root cause of this problem. Using these insights, we propose an alternative strategy for constructing inductive KGC datasets that helps mitigate the PPR shortcut. We then benchmark multiple popular methods using the newly constructed datasets and analyze their performance. The new benchmark datasets help promote a better understanding of the capabilities and challenges of inductive KGC by removing any shortcuts that obfuscate performance.