 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRAJECT-Bench:A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use
Oct 06, 2025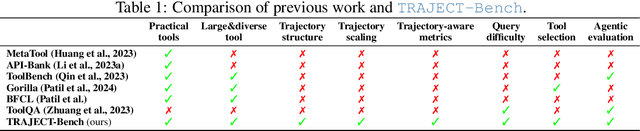

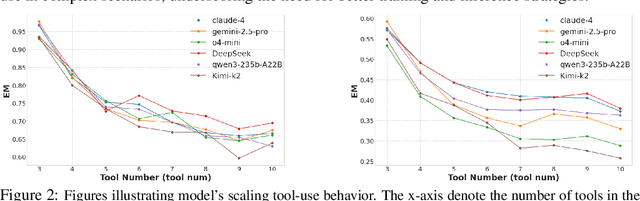
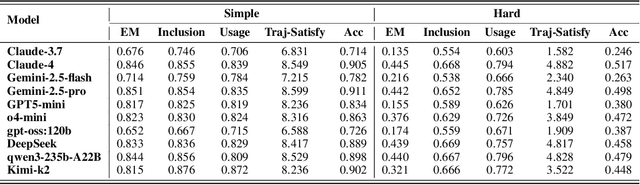
Large language model (LLM)-based agents increasingly rely on tool use to complete real-world tasks. While existing works evaluate the LLMs' tool use capability, they largely focus on the final answers yet overlook the detailed tool usage trajectory, i.e., whether tools are selected, parameterized, and ordered correctly. We introduce TRAJECT-Bench, a trajectory-aware benchmark to comprehensively evaluate LLMs' tool use capability through diverse tasks with fine-grained evaluation metrics. TRAJECT-Bench pairs high-fidelity, executable tools across practical domains with tasks grounded in production-style APIs, and synthesizes trajectories that vary in breadth (parallel calls) and depth (interdependent chains). Besides final accuracy, TRAJECT-Bench also reports trajectory-level diagnostics, including tool selection and argument correctness, and dependency/order satisfaction. Analyses reveal failure modes such as similar tool confusion and parameter-blind selection, and scaling behavior with tool diversity and trajectory length where the bottleneck of transiting from short to mid-length trajectories is revealed, offering actionable guidance for LLMs' tool use.
Learning with Less: Knowledge Distillation from Large Language Models via Unlabeled Data
Nov 12, 2024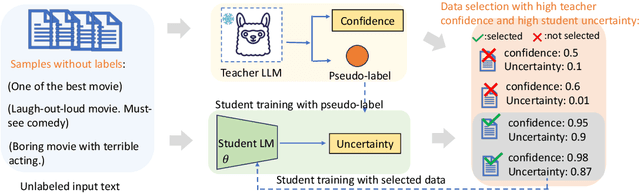


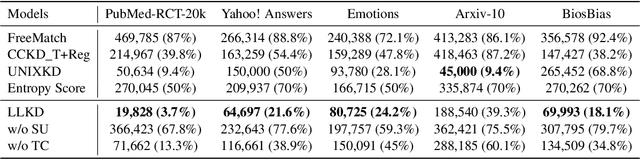
In real-world NLP applications, Large Language Models (LLMs) offer promising solutions due to their extensive training on vast datasets. However, the large size and high computation demands of LLMs limit their practicality in many applications, especially when further fine-tuning is required. To address these limitations, smaller models are typically preferred for deployment. However, their training is hindered by the scarcity of labeled data. In contrast, unlabeled data is often readily which can be leveraged by using LLMs to generate pseudo-labels for training smaller models. This enables the smaller models (student) to acquire knowledge from LLMs(teacher) while reducing computational costs. This process introduces challenges, such as potential noisy pseudo-labels. Selecting high-quality and informative data is therefore critical to enhance model performance while improving the efficiency of data utilization. To address this, we propose LLKD that enables Learning with Less computational resources and less data for Knowledge Distillation from LLMs. LLKD is an adaptive sample selection method that incorporates signals from both the teacher and student. Specifically, it prioritizes samples where the teacher demonstrates high confidence in its labeling, indicating reliable labels, and where the student exhibits a high information need, identifying challenging samples that require further learning. Our comprehensive experiments show that LLKD achieves superior performance across various datasets with higher data efficiency.
Node-wise Filtering in Graph Neural Networks: A Mixture of Experts Approach
Jun 05, 2024



Graph Neural Networks (GNNs) have proven to be highly effective for node classification tasks across diverse graph structural patterns. Traditionally, GNNs employ a uniform global filter, typically a low-pass filter for homophilic graphs and a high-pass filter for heterophilic graphs. However, real-world graphs often exhibit a complex mix of homophilic and heterophilic patterns, rendering a single global filter approach suboptimal. In this work, we theoretically demonstrate that a global filter optimized for one pattern can adversely affect performance on nodes with differing patterns. To address this, we introduce a novel GNN framework Node-MoE that utilizes a mixture of experts to adaptively select the appropriate filters for different nodes. Extensive experiments demonstrate the effectiveness of Node-MoE on both homophilic and heterophilic graphs.
Enhancing ID and Text Fusion via Alternative Training in Session-based Recommendation
Feb 14, 2024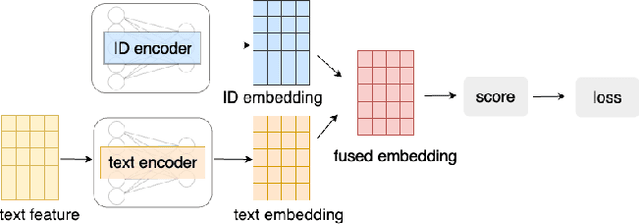
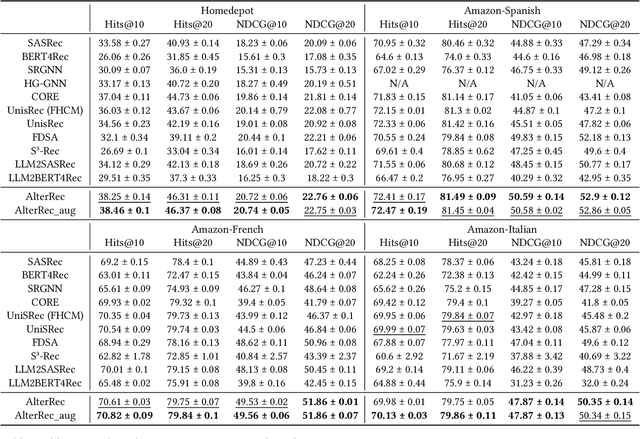
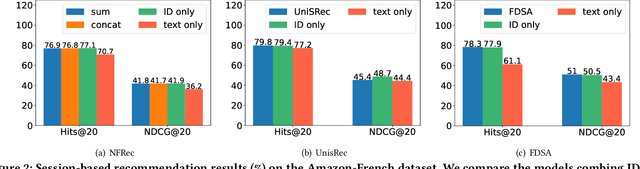

Session-based recommendation has gained increasing attention in recent years, with its aim to offer tailored suggestions based on users' historical behaviors within sessions. To advance this field, a variety of methods have been developed, with ID-based approaches typically demonstrating promising performance. However, these methods often face challenges with long-tail items and overlook other rich forms of information, notably valuable textual semantic information. To integrate text information, various methods have been introduced, mostly following a naive fusion framework. Surprisingly, we observe that fusing these two modalities does not consistently outperform the best single modality by following the naive fusion framework. Further investigation reveals an potential imbalance issue in naive fusion, where the ID dominates and text modality is undertrained. This suggests that the unexpected observation may stem from naive fusion's failure to effectively balance the two modalities, often over-relying on the stronger ID modality. This insight suggests that naive fusion might not be as effective in combining ID and text as previously expected. To address this, we propose a novel alternative training strategy AlterRec. It separates the training of ID and text, thereby avoiding the imbalance issue seen in naive fusion. Additionally, AlterRec designs a novel strategy to facilitate the interaction between the two modalities, enabling them to mutually learn from each other and integrate the text more effectively. Comprehensive experiments demonstrate the effectiveness of AlterRec in session-based recommendation. The implementation is available at https://github.com/Juanhui28/AlterRec.
Mixture of Link Predictors
Feb 13, 2024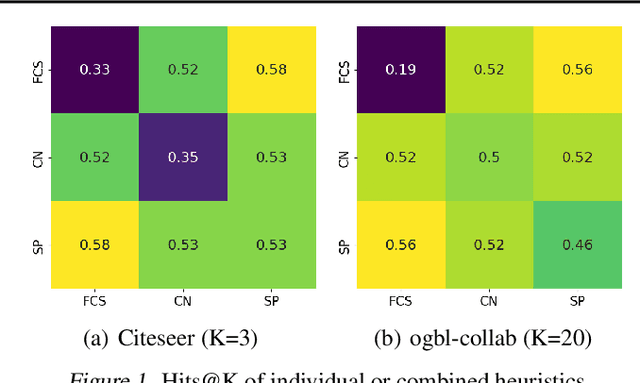
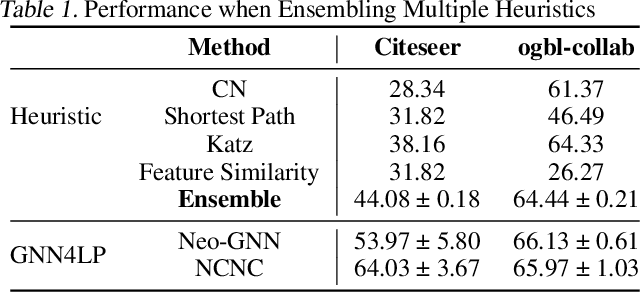
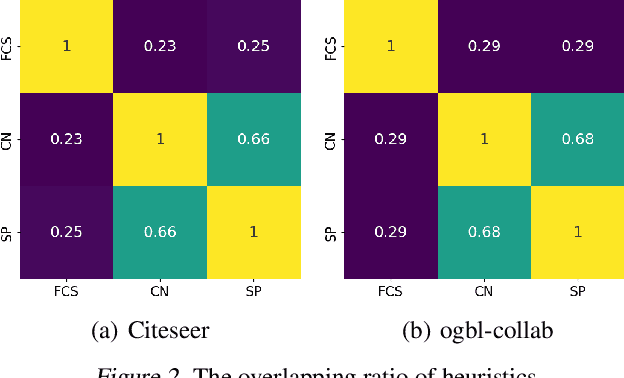

Link prediction, which aims to forecast unseen connections in graphs, is a fundamental task in graph machine learning. Heuristic methods, leveraging a range of different pairwise measures such as common neighbors and shortest paths, often rival the performance of vanilla Graph Neural Networks (GNNs). Therefore, recent advancements in GNNs for link prediction (GNN4LP) have primarily focused on integrating one or a few types of pairwise information. In this work, we reveal that different node pairs within the same dataset necessitate varied pairwise information for accurate prediction and models that only apply the same pairwise information uniformly could achieve suboptimal performance. As a result, we propose a simple mixture of experts model Link-MoE for link prediction. Link-MoE utilizes various GNNs as experts and strategically selects the appropriate expert for each node pair based on various types of pairwise information. Experimental results across diverse real-world datasets demonstrate substantial performance improvement from Link-MoE. Notably, Link-MoE achieves a relative improvement of 18.82\% on the MRR metric for the Pubmed dataset and 10.8\% on the Hits@100 metric for the ogbl-ppa dataset, compared to the best baselines.
Distance-Based Propagation for Efficient Knowledge Graph Reasoning
Nov 02, 2023



Knowledge graph completion (KGC) aims to predict unseen edges in knowledge graphs (KGs), resulting in the discovery of new facts. A new class of methods have been proposed to tackle this problem by aggregating path information. These methods have shown tremendous ability in the task of KGC. However they are plagued by efficiency issues. Though there are a few recent attempts to address this through learnable path pruning, they often sacrifice the performance to gain efficiency. In this work, we identify two intrinsic limitations of these methods that affect the efficiency and representation quality. To address the limitations, we introduce a new method, TAGNet, which is able to efficiently propagate information. This is achieved by only aggregating paths in a fixed window for each source-target pair. We demonstrate that the complexity of TAGNet is independent of the number of layers. Extensive experiments demonstrate that TAGNet can cut down on the number of propagated messages by as much as 90% while achieving competitive performance on multiple KG datasets. The code is available at https://github.com/HarryShomer/TAGNet.
Adaptive Pairwise Encodings for Link Prediction
Oct 18, 2023



Link prediction is a common task on graph-structured data that has seen applications in a variety of domains. Classically, hand-crafted heuristics were used for this task. Heuristic measures are chosen such that they correlate well with the underlying factors related to link formation. In recent years, a new class of methods has emerged that combines the advantages of message-passing neural networks (MPNN) and heuristics methods. These methods perform predictions by using the output of an MPNN in conjunction with a "pairwise encoding" that captures the relationship between nodes in the candidate link. They have been shown to achieve strong performance on numerous datasets. However, current pairwise encodings often contain a strong inductive bias, using the same underlying factors to classify all links. This limits the ability of existing methods to learn how to properly classify a variety of different links that may form from different factors. To address this limitation, we propose a new method, LPFormer, which attempts to adaptively learn the pairwise encodings for each link. LPFormer models the link factors via an attention module that learns the pairwise encoding that exists between nodes by modeling multiple factors integral to link prediction. Extensive experiments demonstrate that LPFormer can achieve SOTA performance on numerous datasets while maintaining efficiency.
Revisiting Link Prediction: A Data Perspective
Oct 01, 2023



Link prediction, a fundamental task on graphs, has proven indispensable in various applications, e.g., friend recommendation, protein analysis, and drug interaction prediction. However, since datasets span a multitude of domains, they could have distinct underlying mechanisms of link formation. Evidence in existing literature underscores the absence of a universally best algorithm suitable for all datasets. In this paper, we endeavor to explore principles of link prediction across diverse datasets from a data-centric perspective. We recognize three fundamental factors critical to link prediction: local structural proximity, global structural proximity, and feature proximity. We then unearth relationships among those factors where (i) global structural proximity only shows effectiveness when local structural proximity is deficient. (ii) The incompatibility can be found between feature and structural proximity. Such incompatibility leads to GNNs for Link Prediction (GNN4LP) consistently underperforming on edges where the feature proximity factor dominates. Inspired by these new insights from a data perspective, we offer practical instruction for GNN4LP model design and guidelines for selecting appropriate benchmark datasets for more comprehensive evaluations.
Evaluating Graph Neural Networks for Link Prediction: Current Pitfalls and New Benchmarking
Jun 18, 2023Link prediction attempts to predict whether an unseen edge exists based on only a portion of edges of a graph. A flurry of methods have been introduced in recent years that attempt to make use of graph neural networks (GNNs) for this task. Furthermore, new and diverse datasets have also been created to better evaluate the effectiveness of these new models. However, multiple pitfalls currently exist that hinder our ability to properly evaluate these new methods. These pitfalls mainly include: (1) Lower than actual performance on multiple baselines, (2) A lack of a unified data split and evaluation metric on some datasets, and (3) An unrealistic evaluation setting that uses easy negative samples. To overcome these challenges, we first conduct a fair comparison across prominent methods and datasets, utilizing the same dataset and hyperparameter search settings. We then create a more practical evaluation setting based on a Heuristic Related Sampling Technique (HeaRT), which samples hard negative samples via multiple heuristics. The new evaluation setting helps promote new challenges and opportunities in link prediction by aligning the evaluation with real-world situations. Our implementation and data are available at https://github.com/Juanhui28/HeaRT
Learning Representations for Hyper-Relational Knowledge Graphs
Aug 30, 2022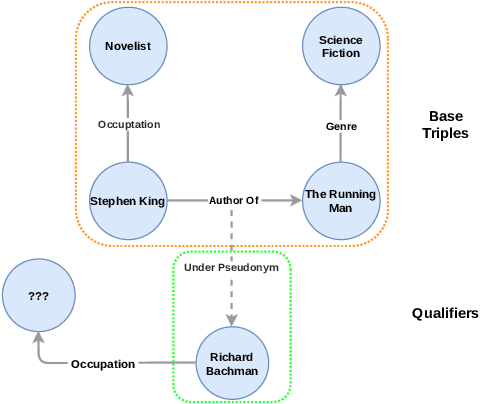
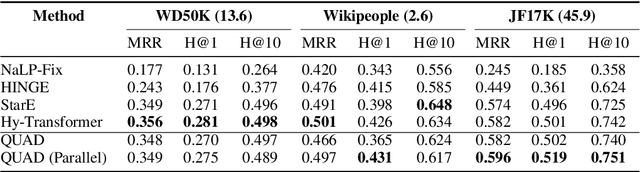

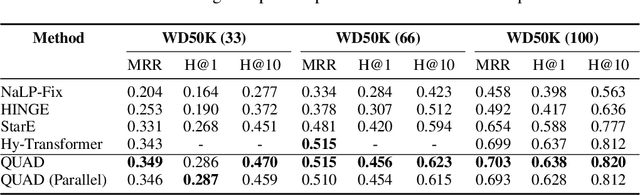
Knowledge graphs (KGs) have gained prominence for their ability to learn representations for uni-relational facts. Recently, research has focused on modeling hyper-relational facts, which move beyond the restriction of uni-relational facts and allow us to represent more complex and real-world information. However, existing approaches for learning representations on hyper-relational KGs majorly focus on enhancing the communication from qualifiers to base triples while overlooking the flow of information from base triple to qualifiers. This can lead to suboptimal qualifier representations, especially when a large amount of qualifiers are presented. It motivates us to design a framework that utilizes multiple aggregators to learn representations for hyper-relational facts: one from the perspective of the base triple and the other one from the perspective of the qualifiers. Experiments demonstrate the effectiveness of our framework for hyper-relational knowledge graph completion across multiple datasets. Furthermore, we conduct an ablation study that validates the importance of the various components in our framework. The code to reproduce our results can be found at \url{https://github.com/HarryShomer/QUAD}.