 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRO: LLM Agent Optimization Through Rising Reward Trajectories
May 27, 2025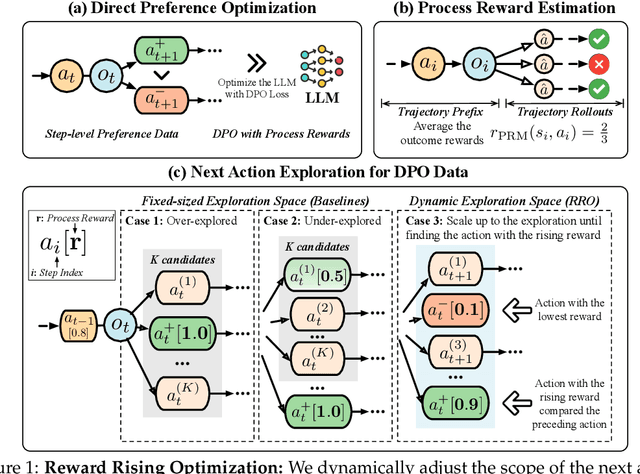
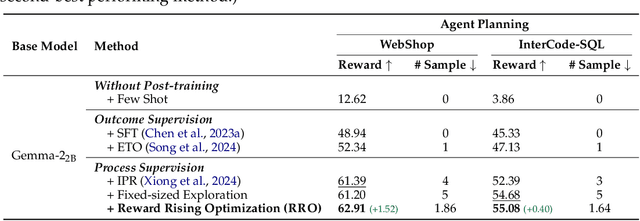
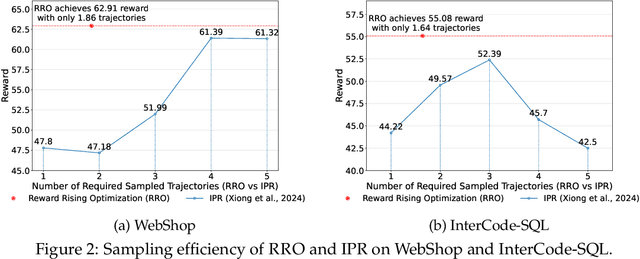

Large language models (LLMs) have exhibited extraordinary performance in a variety of tasks while it remains challenging for them to solve complex multi-step tasks as agents. In practice, agents sensitive to the outcome of certain key steps which makes them likely to fail the task because of a subtle mistake in the planning trajectory. Recent approaches resort to calibrating the reasoning process through reinforcement learning. They reward or penalize every reasoning step with process supervision, as known as Process Reward Models (PRMs). However, PRMs are difficult and costly to scale up with a large number of next action candidates since they require extensive computations to acquire the training data through the per-step trajectory exploration. To mitigate this issue, we focus on the relative reward trend across successive reasoning steps and propose maintaining an increasing reward in the collected trajectories for process supervision, which we term Reward Rising Optimization (RRO). Specifically, we incrementally augment the process supervision until identifying a step exhibiting positive reward differentials, i.e. rising rewards, relative to its preceding iteration. This method dynamically expands the search space for the next action candidates, efficiently capturing high-quality data. We provide mathematical groundings and empirical results on the WebShop and InterCode-SQL benchmarks, showing that our proposed RRO achieves superior performance while requiring much less exploration cost.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.
AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents
Apr 13, 2025



A/B testing experiment is a widely adopted method for evaluating UI/UX design decisions in modern web applications. Yet, traditional A/B testing remains constrained by its dependence on the large-scale and live traffic of human participants, and the long time of waiting for the testing result. Through formative interviews with six experienced industry practitioners, we identified critical bottlenecks in current A/B testing workflows. In response, we present AgentA/B, a novel system that leverages Large Language Model-based autonomous agents (LLM Agents) to automatically simulate user interaction behaviors with real webpages. AgentA/B enables scalable deployment of LLM agents with diverse personas, each capable of navigating the dynamic webpage and interactively executing multi-step interactions like search, clicking, filtering, and purchasing. In a demonstrative controlled experiment, we employ AgentA/B to simulate a between-subject A/B testing with 1,000 LLM agents Amazon.com, and compare agent behaviors with real human shopping behaviors at a scale. Our findings suggest AgentA/B can emulate human-like behavior patterns.
Query Brand Entity Linking in E-Commerce Search
Feb 03, 2025



In this work, we address the brand entity linking problem for e-commerce search queries. The entity linking task is done by either i)a two-stage process consisting of entity mention detection followed by entity disambiguation or ii) an end-to-end linking approaches that directly fetch the target entity given the input text. The task presents unique challenges: queries are extremely short (averaging 2.4 words), lack natural language structure, and must handle a massive space of unique brands. We present a two-stage approach combining named-entity recognition with matching, and a novel end-to-end solution using extreme multi-class classification. We validate our solutions by both offline benchmarks and the impact of online A/B test.
Reasoning with Graphs: Structuring Implicit Knowledge to Enhance LLMs Reasoning
Jan 14, 2025Large language models (LLMs) have demonstrated remarkable success across a wide range of tasks; however, they still encounter challenges in reasoning tasks that require understanding and inferring relationships between distinct pieces of information within text sequences. This challenge is particularly pronounced in tasks involving multi-step processes, such as logical reasoning and multi-hop question answering, where understanding implicit relationships between entities and leveraging multi-hop connections in the given context are crucial. Graphs, as fundamental data structures, explicitly represent pairwise relationships between entities, thereby offering the potential to enhance LLMs' reasoning capabilities. External graphs have proven effective in supporting LLMs across multiple tasks. However, in many reasoning tasks, no pre-existing graph structure is provided. Can we structure implicit knowledge derived from context into graphs to assist LLMs in reasoning? In this paper, we propose Reasoning with Graphs (RwG) by first constructing explicit graphs from the context and then leveraging these graphs to enhance LLM reasoning performance on reasoning tasks. Extensive experiments demonstrate the effectiveness of the proposed method in improving both logical reasoning and multi-hop question answering tasks.
Learning with Less: Knowledge Distillation from Large Language Models via Unlabeled Data
Nov 12, 2024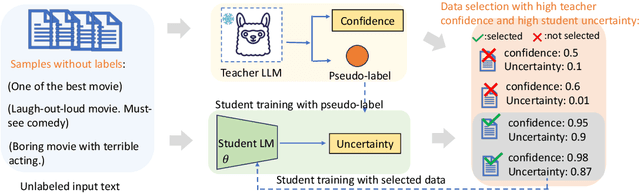


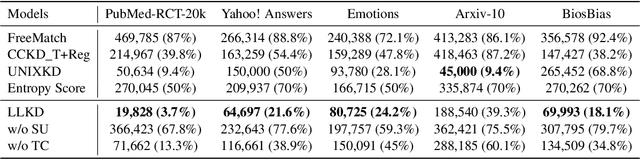
In real-world NLP applications, Large Language Models (LLMs) offer promising solutions due to their extensive training on vast datasets. However, the large size and high computation demands of LLMs limit their practicality in many applications, especially when further fine-tuning is required. To address these limitations, smaller models are typically preferred for deployment. However, their training is hindered by the scarcity of labeled data. In contrast, unlabeled data is often readily which can be leveraged by using LLMs to generate pseudo-labels for training smaller models. This enables the smaller models (student) to acquire knowledge from LLMs(teacher) while reducing computational costs. This process introduces challenges, such as potential noisy pseudo-labels. Selecting high-quality and informative data is therefore critical to enhance model performance while improving the efficiency of data utilization. To address this, we propose LLKD that enables Learning with Less computational resources and less data for Knowledge Distillation from LLMs. LLKD is an adaptive sample selection method that incorporates signals from both the teacher and student. Specifically, it prioritizes samples where the teacher demonstrates high confidence in its labeling, indicating reliable labels, and where the student exhibits a high information need, identifying challenging samples that require further learning. Our comprehensive experiments show that LLKD achieves superior performance across various datasets with higher data efficiency.
SimRAG: Self-Improving Retrieval-Augmented Generation for Adapting Large Language Models to Specialized Domains
Oct 23, 2024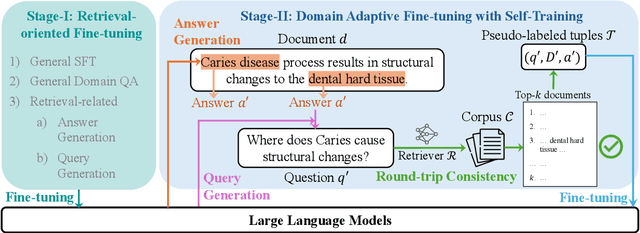
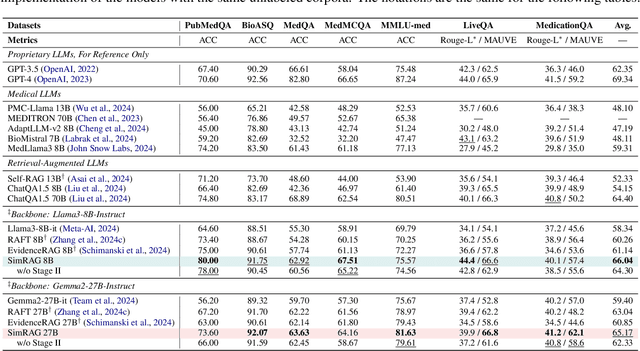
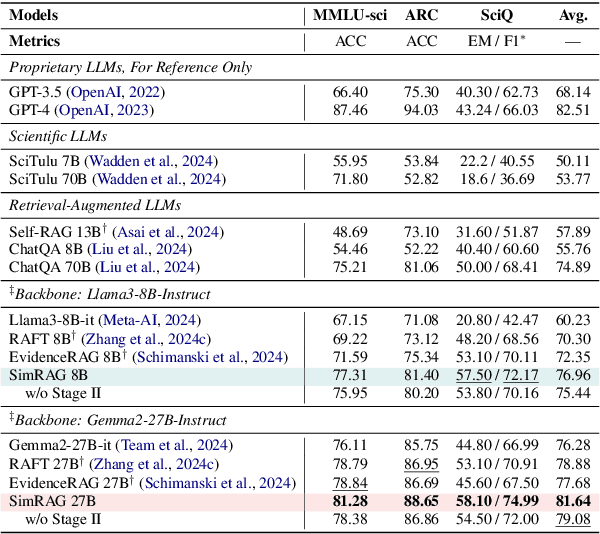
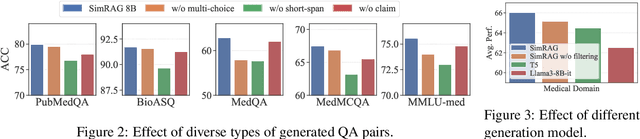
Retrieval-augmented generation (RAG) enhances the question-answering (QA) abilities of large language models (LLMs) by integrating external knowledge. However, adapting general-purpose RAG systems to specialized fields such as science and medicine poses unique challenges due to distribution shifts and limited access to domain-specific data. To tackle this, we propose SimRAG, a self-training approach that equips the LLM with joint capabilities of question answering and question generation for domain adaptation. Our method first fine-tunes the LLM on instruction-following, question-answering, and search-related data. Then, it prompts the same LLM to generate diverse domain-relevant questions from unlabeled corpora, with an additional filtering strategy to retain high-quality synthetic examples. By leveraging these synthetic examples, the LLM can improve their performance on domain-specific RAG tasks. Experiments on 11 datasets, spanning two backbone sizes and three domains, demonstrate that SimRAG outperforms baselines by 1.2\%--8.6\%.
Exploring Query Understanding for Amazon Product Search
Aug 05, 2024



Online shopping platforms, such as Amazon, offer services to billions of people worldwide. Unlike web search or other search engines, product search engines have their unique characteristics, primarily featuring short queries which are mostly a combination of product attributes and structured product search space. The uniqueness of product search underscores the crucial importance of the query understanding component. However, there are limited studies focusing on exploring this impact within real-world product search engines. In this work, we aim to bridge this gap by conducting a comprehensive study and sharing our year-long journey investigating how the query understanding service impacts Amazon Product Search. Firstly, we explore how query understanding-based ranking features influence the ranking process. Next, we delve into how the query understanding system contributes to understanding the performance of a ranking model. Building on the insights gained from our study on the evaluation of the query understanding-based ranking model, we propose a query understanding-based multi-task learning framework for ranking. We present our studies and investigations using the real-world system on Amazon Search.
REAPER: Reasoning based Retrieval Planning for Complex RAG Systems
Jul 26, 2024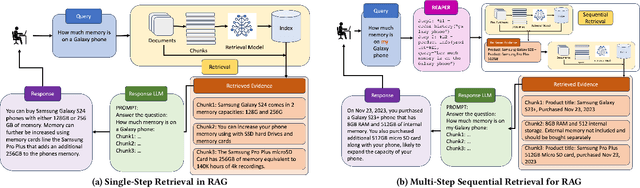
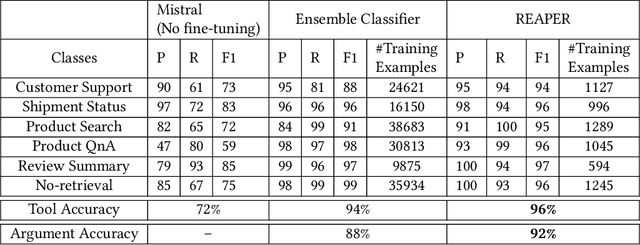


Complex dialog systems often use retrieved evidence to facilitate factual responses. Such RAG (Retrieval Augmented Generation) systems retrieve from massive heterogeneous data stores that are usually architected as multiple indexes or APIs instead of a single monolithic source. For a given query, relevant evidence needs to be retrieved from one or a small subset of possible retrieval sources. Complex queries can even require multi-step retrieval. For example, a conversational agent on a retail site answering customer questions about past orders will need to retrieve the appropriate customer order first and then the evidence relevant to the customer's question in the context of the ordered product. Most RAG Agents handle such Chain-of-Thought (CoT) tasks by interleaving reasoning and retrieval steps. However, each reasoning step directly adds to the latency of the system. For large models (>100B parameters) this latency cost is significant -- in the order of multiple seconds. Multi-agent systems may classify the query to a single Agent associated with a retrieval source, though this means that a (small) classification model dictates the performance of a large language model. In this work we present REAPER (REAsoning-based PlannER) - an LLM based planner to generate retrieval plans in conversational systems. We show significant gains in latency over Agent-based systems and are able to scale easily to new and unseen use cases as compared to classification-based planning. Though our method can be applied to any RAG system, we show our results in the context of Rufus -- Amazon's conversational shopping assistant.
IterAlign: Iterative Constitutional Alignment of Large Language Models
Mar 27, 2024



With the rapid development of large language models (LLMs), aligning LLMs with human values and societal norms to ensure their reliability and safety has become crucial. Reinforcement learning with human feedback (RLHF) and Constitutional AI (CAI) have been proposed for LLM alignment. However, these methods require either heavy human annotations or explicitly pre-defined constitutions, which are labor-intensive and resource-consuming. To overcome these drawbacks, we study constitution-based LLM alignment and propose a data-driven constitution discovery and self-alignment framework called IterAlign. IterAlign leverages red teaming to unveil the weaknesses of an LLM and automatically discovers new constitutions using a stronger LLM. These constitutions are then used to guide self-correction of the base LLM. Such a constitution discovery pipeline can be run iteratively and automatically to discover new constitutions that specifically target the alignment gaps in the current LLM. Empirical results on several safety benchmark datasets and multiple base LLMs show that IterAlign successfully improves truthfulness, helpfulness, harmlessness and honesty, improving the LLM alignment by up to $13.5\%$ in harmlessness.