 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents
Jan 28, 2026Tool-calling agents are increasingly deployed in real-world customer-facing workflows. Yet most studies on tool-calling agents focus on idealized settings with general, fixed, and well-specified tasks. In real-world applications, user requests are often (1) ambiguous, (2) changing over time, or (3) infeasible due to policy constraints, and training and evaluation data that cover these diverse, complex interaction patterns remain under-represented. To bridge the gap, we present Trajectory2Task, a verifiable data generation pipeline for studying tool use at scale under three realistic user scenarios: ambiguous intent, changing intent, and infeasible intents. The pipeline first conducts multi-turn exploration to produce valid tool-call trajectories. It then converts these trajectories into user-facing tasks with controlled intent adaptations. This process yields verifiable task that support closed-loop evaluation and training. We benchmark seven state-of-the-art LLMs on the generated complex user scenario tasks and observe frequent failures. Finally, using successful trajectories obtained from task rollouts, we fine-tune lightweight LLMs and find consistent improvements across all three conditions, along with better generalization to unseen tool-use domains, indicating stronger general tool-calling ability.
Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning
Jan 19, 2026Large Language Models (LLMs) have become a popular interface for human-AI interaction, supporting information seeking and task assistance through natural, multi-turn dialogue. To respond to users within multi-turn dialogues, the context-dependent user intent evolves across interactions, requiring contextual interpretation, query reformulation, and dynamic coordination between retrieval and generation. Existing studies usually follow static rewrite, retrieve, and generate pipelines, which optimize different procedures separately and overlook the mixed-initiative action optimization simultaneously. Although the recent developments in deep search agents demonstrate the effectiveness in jointly optimizing retrieval and generation via reasoning, these approaches focus on single-turn scenarios, which might lack the ability to handle multi-turn interactions. We introduce a conversational agent that interleaves search and reasoning across turns, enabling exploratory and adaptive behaviors learned through reinforcement learning (RL) training with tailored rewards towards evolving user goals. The experimental results across four widely used conversational benchmarks demonstrate the effectiveness of our methods by surpassing several existing strong baselines.
Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline
Jan 18, 2026Recent advances in LLM-based multi-agent systems (MAS) show that workflows composed of multiple LLM agents with distinct roles, tools, and communication patterns can outperform single-LLM baselines on complex tasks. However, most frameworks are homogeneous, where all agents share the same base LLM and differ only in prompts, tools, and positions in the workflow. This raises the question of whether such workflows can be simulated by a single agent through multi-turn conversations. We investigate this across seven benchmarks spanning coding, mathematics, general question answering, domain-specific reasoning, and real-world planning and tool use. Our results show that a single agent can reach the performance of homogeneous workflows with an efficiency advantage from KV cache reuse, and can even match the performance of an automatically optimized heterogeneous workflow. Building on this finding, we propose \textbf{OneFlow}, an algorithm that automatically tailors workflows for single-agent execution, reducing inference costs compared to existing automatic multi-agent design frameworks without trading off accuracy. These results position the single-LLM implementation of multi-agent workflows as a strong baseline for MAS research. We also note that single-LLM methods cannot capture heterogeneous workflows due to the lack of KV cache sharing across different LLMs, highlighting future opportunities in developing \textit{truly} heterogeneous multi-agent systems.
See, Think, Act: Online Shopper Behavior Simulation with VLM Agents
Oct 22, 2025LLMs have recently demonstrated strong potential in simulating online shopper behavior. Prior work has improved action prediction by applying SFT on action traces with LLM-generated rationales, and by leveraging RL to further enhance reasoning capabilities. Despite these advances, current approaches rely on text-based inputs and overlook the essential role of visual perception in shaping human decision-making during web GUI interactions. In this paper, we investigate the integration of visual information, specifically webpage screenshots, into behavior simulation via VLMs, leveraging OPeRA dataset. By grounding agent decision-making in both textual and visual modalities, we aim to narrow the gap between synthetic agents and real-world users, thereby enabling more cognitively aligned simulations of online shopping behavior. Specifically, we employ SFT for joint action prediction and rationale generation, conditioning on the full interaction context, which comprises action history, past HTML observations, and the current webpage screenshot. To further enhance reasoning capabilities, we integrate RL with a hierarchical reward structure, scaled by a difficulty-aware factor that prioritizes challenging decision points. Empirically, our studies show that incorporating visual grounding yields substantial gains: the combination of text and image inputs improves exact match accuracy by more than 6% over text-only inputs. These results indicate that multi-modal grounding not only boosts predictive accuracy but also enhances simulation fidelity in visually complex environments, which captures nuances of human attention and decision-making that text-only agents often miss. Finally, we revisit the design space of behavior simulation frameworks, identify key methodological limitations, and propose future research directions toward building efficient and effective human behavior simulators.
DPRF: A Generalizable Dynamic Persona Refinement Framework for Optimizing Behavior Alignment Between Personalized LLM Role-Playing Agents and Humans
Oct 16, 2025The emerging large language model role-playing agents (LLM RPAs) aim to simulate individual human behaviors, but the persona fidelity is often undermined by manually-created profiles (e.g., cherry-picked information and personality characteristics) without validating the alignment with the target individuals. To address this limitation, our work introduces the Dynamic Persona Refinement Framework (DPRF).DPRF aims to optimize the alignment of LLM RPAs' behaviors with those of target individuals by iteratively identifying the cognitive divergence, either through free-form or theory-grounded, structured analysis, between generated behaviors and human ground truth, and refining the persona profile to mitigate these divergences.We evaluate DPRF with five LLMs on four diverse behavior-prediction scenarios: formal debates, social media posts with mental health issues, public interviews, and movie reviews.DPRF can consistently improve behavioral alignment considerably over baseline personas and generalizes across models and scenarios.Our work provides a robust methodology for creating high-fidelity persona profiles and enhancing the validity of downstream applications, such as user simulation, social studies, and personalized AI.
Customer-R1: Personalized Simulation of Human Behaviors via RL-based LLM Agent in Online Shopping
Oct 08, 2025


Simulating step-wise human behavior with Large Language Models (LLMs) has become an emerging research direction, enabling applications in various practical domains. While prior methods, including prompting, supervised fine-tuning (SFT), and reinforcement learning (RL), have shown promise in modeling step-wise behavior, they primarily learn a population-level policy without conditioning on a user's persona, yielding generic rather than personalized simulations. In this work, we pose a critical question: how can LLM agents better simulate personalized user behavior? We introduce Customer-R1, an RL-based method for personalized, step-wise user behavior simulation in online shopping environments. Our policy is conditioned on an explicit persona, and we optimize next-step rationale and action generation via action correctness reward signals. Experiments on the OPeRA dataset emonstrate that Customer-R1 not only significantly outperforms prompting and SFT-based baselines in next-action prediction tasks, but also better matches users' action distribution, indicating higher fidelity in personalized behavior simulation.
SurgWound-Bench: A Benchmark for Surgical Wound Diagnosis
Aug 21, 2025Surgical site infection (SSI) is one of the most common and costly healthcare-associated infections and and surgical wound care remains a significant clinical challenge in preventing SSIs and improving patient outcomes. While recent studies have explored the use of deep learning for preliminary surgical wound screening, progress has been hindered by concerns over data privacy and the high costs associated with expert annotation. Currently, no publicly available dataset or benchmark encompasses various types of surgical wounds, resulting in the absence of an open-source Surgical-Wound screening tool. To address this gap: (1) we present SurgWound, the first open-source dataset featuring a diverse array of surgical wound types. It contains 697 surgical wound images annotated by 3 professional surgeons with eight fine-grained clinical attributes. (2) Based on SurgWound, we introduce the first benchmark for surgical wound diagnosis, which includes visual question answering (VQA) and report generation tasks to comprehensively evaluate model performance. (3) Furthermore, we propose a three-stage learning framework, WoundQwen, for surgical wound diagnosis. In the first stage, we employ five independent MLLMs to accurately predict specific surgical wound characteristics. In the second stage, these predictions serve as additional knowledge inputs to two MLLMs responsible for diagnosing outcomes, which assess infection risk and guide subsequent interventions. In the third stage, we train a MLLM that integrates the diagnostic results from the previous two stages to produce a comprehensive report. This three-stage framework can analyze detailed surgical wound characteristics and provide subsequent instructions to patients based on surgical images, paving the way for personalized wound care, timely intervention, and improved patient outcomes.
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025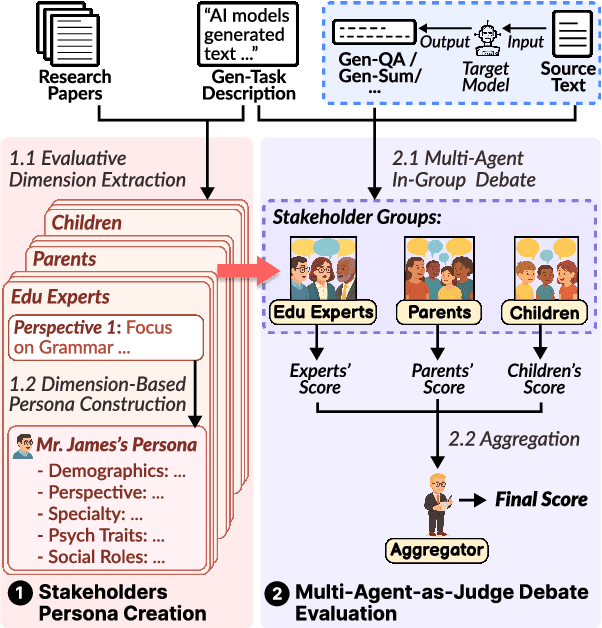



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025


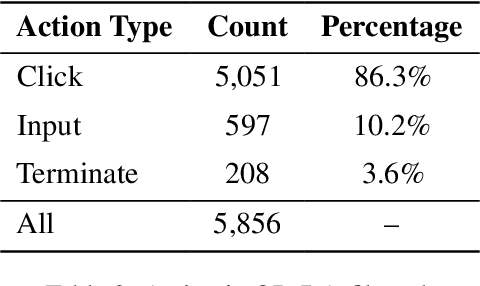
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025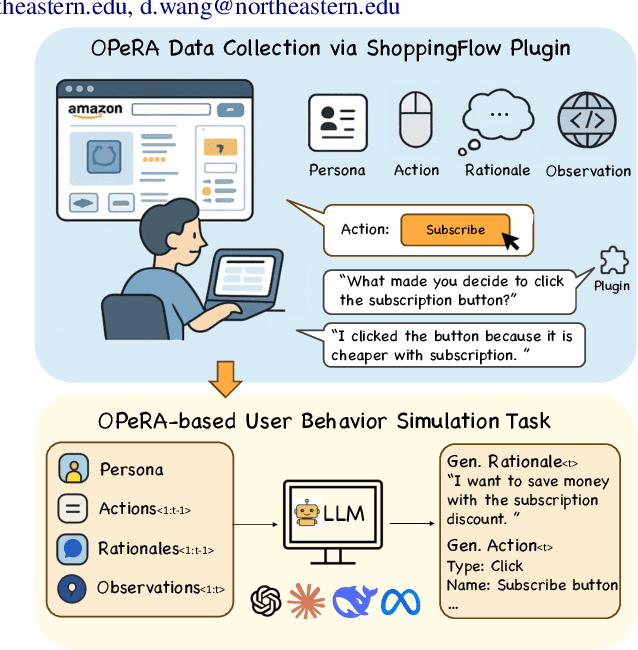
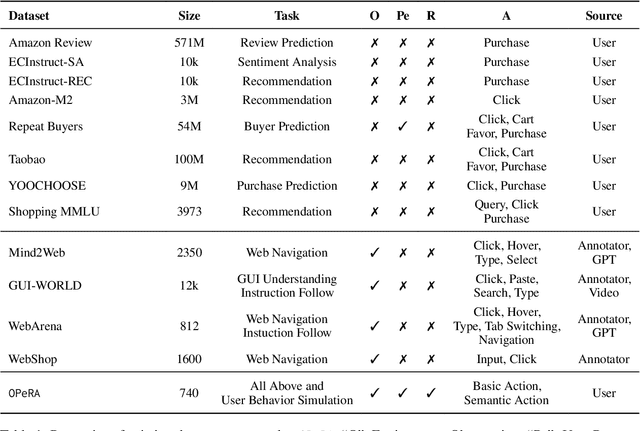
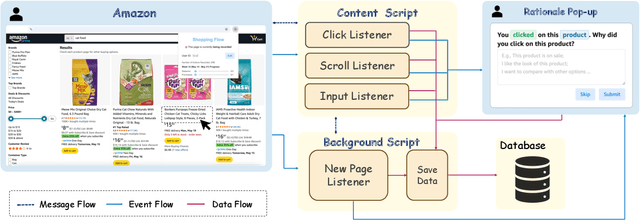
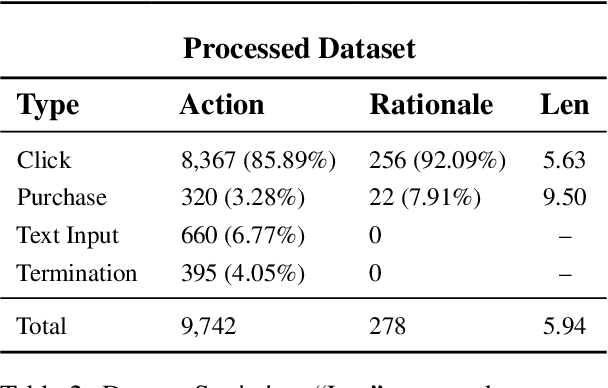
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.