 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Sensitive Offline Contextual Bandits
Oct 31, 2025Offline contextual bandits allow one to learn policies from historical/offline data without requiring online interaction. However, offline policy optimization that maximizes overall expected rewards can unintentionally amplify the reward disparities across groups. As a result, some groups might benefit more than others from the learned policy, raising concerns about fairness, especially when the resources are limited. In this paper, we study a group-sensitive fairness constraint in offline contextual bandits, reducing group-wise reward disparities that may arise during policy learning. We tackle the following common-parity requirements: the reward disparity is constrained within some user-defined threshold or the reward disparity should be minimized during policy optimization. We propose a constrained offline policy optimization framework by introducing group-wise reward disparity constraints into an off-policy gradient-based optimization procedure. To improve the estimation of the group-wise reward disparity during training, we employ a doubly robust estimator and further provide a convergence guarantee for policy optimization. Empirical results in synthetic and real-world datasets demonstrate that our method effectively reduces reward disparities while maintaining competitive overall performance.
SynthTextEval: Synthetic Text Data Generation and Evaluation for High-Stakes Domains
Jul 09, 2025We present SynthTextEval, a toolkit for conducting comprehensive evaluations of synthetic text. The fluency of large language model (LLM) outputs has made synthetic text potentially viable for numerous applications, such as reducing the risks of privacy violations in the development and deployment of AI systems in high-stakes domains. Realizing this potential, however, requires principled consistent evaluations of synthetic data across multiple dimensions: its utility in downstream systems, the fairness of these systems, the risk of privacy leakage, general distributional differences from the source text, and qualitative feedback from domain experts. SynthTextEval allows users to conduct evaluations along all of these dimensions over synthetic data that they upload or generate using the toolkit's generation module. While our toolkit can be run over any data, we highlight its functionality and effectiveness over datasets from two high-stakes domains: healthcare and law. By consolidating and standardizing evaluation metrics, we aim to improve the viability of synthetic text, and in-turn, privacy-preservation in AI development.
RECOVER: Designing a Large Language Model-based Remote Patient Monitoring System for Postoperative Gastrointestinal Cancer Care
Feb 09, 2025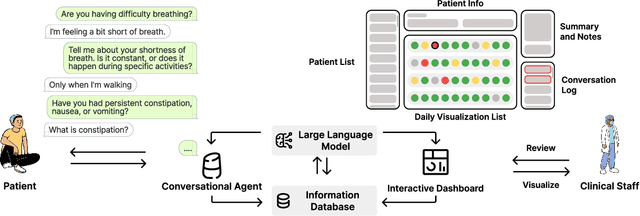

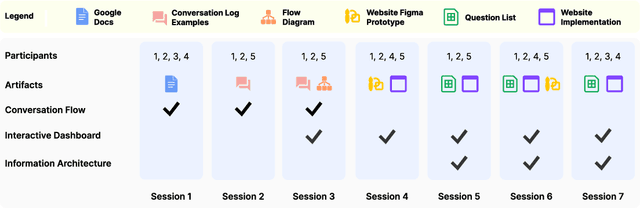
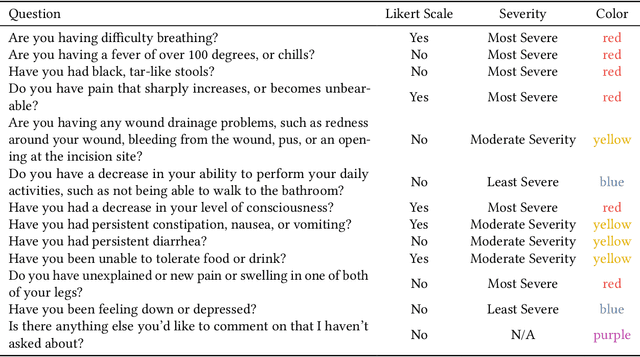
Cancer surgery is a key treatment for gastrointestinal (GI) cancers, a group of cancers that account for more than 35% of cancer-related deaths worldwide, but postoperative complications are unpredictable and can be life-threatening. In this paper, we investigate how recent advancements in large language models (LLMs) can benefit remote patient monitoring (RPM) systems through clinical integration by designing RECOVER, an LLM-powered RPM system for postoperative GI cancer care. To closely engage stakeholders in the design process, we first conducted seven participatory design sessions with five clinical staff and interviewed five cancer patients to derive six major design strategies for integrating clinical guidelines and information needs into LLM-based RPM systems. We then designed and implemented RECOVER, which features an LLM-powered conversational agent for cancer patients and an interactive dashboard for clinical staff to enable efficient postoperative RPM. Finally, we used RECOVER as a pilot system to assess the implementation of our design strategies with four clinical staff and five patients, providing design implications by identifying crucial design elements, offering insights on responsible AI, and outlining opportunities for future LLM-powered RPM systems.
Improving Equity in Health Modeling with GPT4-Turbo Generated Synthetic Data: A Comparative Study
Dec 20, 2024
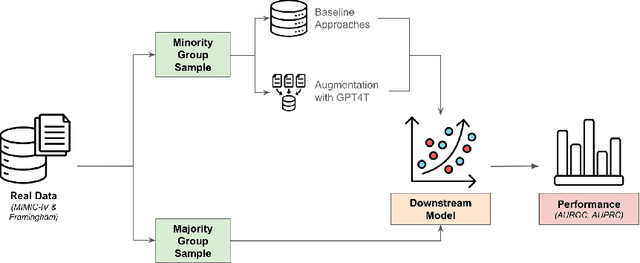
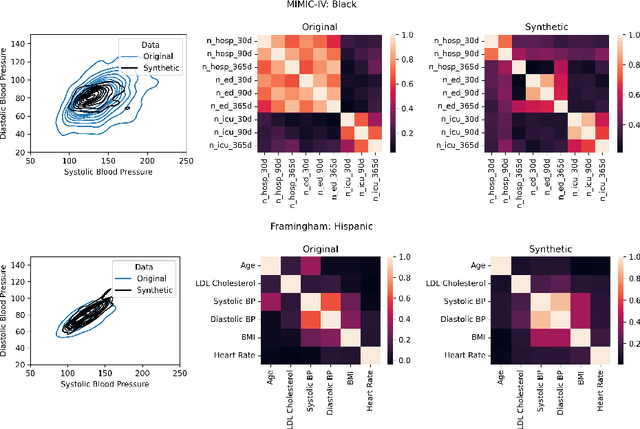

Objective. Demographic groups are often represented at different rates in medical datasets. These differences can create bias in machine learning algorithms, with higher levels of performance for better-represented groups. One promising solution to this problem is to generate synthetic data to mitigate potential adverse effects of non-representative data sets. Methods. We build on recent advances in LLM-based synthetic data generation to create a pipeline where the synthetic data is generated separately for each demographic group. We conduct our study using MIMIC-IV and Framingham "Offspring and OMNI-1 Cohorts" datasets. We prompt GPT4-Turbo to create group-specific data, providing training examples and the dataset context. An exploratory analysis is conducted to ascertain the quality of the generated data. We then evaluate the utility of the synthetic data for augmentation of a training dataset in a downstream machine learning task, focusing specifically on model performance metrics across groups. Results. The performance of GPT4-Turbo augmentation is generally superior but not always. In the majority of experiments our method outperforms standard modeling baselines, however, prompting GPT-4-Turbo to produce data specific to a group provides little to no additional benefit over a prompt that does not specify the group. Conclusion. We developed a method for using LLMs out-of-the-box to synthesize group-specific data to address imbalances in demographic representation in medical datasets. As another "tool in the toolbox", this method can improve model fairness and thus health equity. More research is needed to understand the conditions under which LLM generated synthetic data is useful for non-representative medical data sets.
Let Curves Speak: A Continuous Glucose Monitor based Large Sensor Foundation Model for Diabetes Management
Dec 12, 2024



While previous studies of AI in diabetes management focus on long-term risk, research on near-future glucose prediction remains limited but important as it enables timely diabetes self-management. Integrating AI with continuous glucose monitoring (CGM) holds promise for near-future glucose prediction. However, existing models have limitations in capturing patterns of blood glucose fluctuations and demonstrate poor generalizability. A robust approach is needed to leverage massive CGM data for near-future glucose prediction. We propose large sensor models (LSMs) to capture knowledge in CGM data by modeling patients as sequences of glucose. CGM-LSM is pretrained on 15.96 million glucose records from 592 diabetes patients for near-future glucose prediction. We evaluated CGM-LSM against state-of-the-art methods using the OhioT1DM dataset across various metrics, prediction horizons, and unseen patients. Additionally, we assessed its generalizability across factors like diabetes type, age, gender, and hour of day. CGM-LSM achieved exceptional performance, with an rMSE of 29.81 mg/dL for type 1 diabetes patients and 23.49 mg/dL for type 2 diabetes patients in a two-hour prediction horizon. For the OhioT1DM dataset, CGM-LSM achieved a one-hour rMSE of 15.64 mg/dL, halving the previous best of 31.97 mg/dL. Robustness analyses revealed consistent performance not only for unseen patients and future periods, but also across diabetes type, age, and gender. The model demonstrated adaptability to different hours of day, maintaining accuracy across periods of various activity intensity levels. CGM-LSM represents a transformative step in diabetes management by leveraging pretraining to uncover latent glucose generation patterns in sensor data. Our findings also underscore the broader potential of LSMs to drive innovation across domains involving complex sensor data.
People Talking and AI Listening: How Stigmatizing Language in EHR Notes Affect AI Performance
May 17, 2023

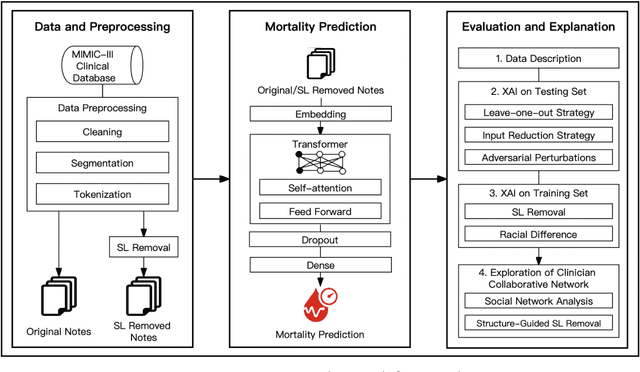
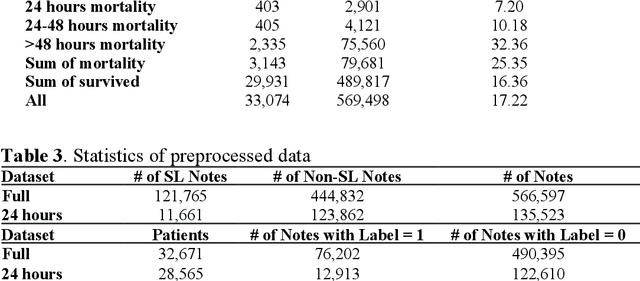
Electronic health records (EHRs) serve as an essential data source for the envisioned artificial intelligence (AI)-driven transformation in healthcare. However, clinician biases reflected in EHR notes can lead to AI models inheriting and amplifying these biases, perpetuating health disparities. This study investigates the impact of stigmatizing language (SL) in EHR notes on mortality prediction using a Transformer-based deep learning model and explainable AI (XAI) techniques. Our findings demonstrate that SL written by clinicians adversely affects AI performance, particularly so for black patients, highlighting SL as a source of racial disparity in AI model development. To explore an operationally efficient way to mitigate SL's impact, we investigate patterns in the generation of SL through a clinicians' collaborative network, identifying central clinicians as having a stronger impact on racial disparity in the AI model. We find that removing SL written by central clinicians is a more efficient bias reduction strategy than eliminating all SL in the entire corpus of data. This study provides actionable insights for responsible AI development and contributes to understanding clinician behavior and EHR note writing in healthcare.
Catch Me If You Can: Identifying Fraudulent Physician Reviews with Large Language Models Using Generative Pre-Trained Transformers
Apr 19, 2023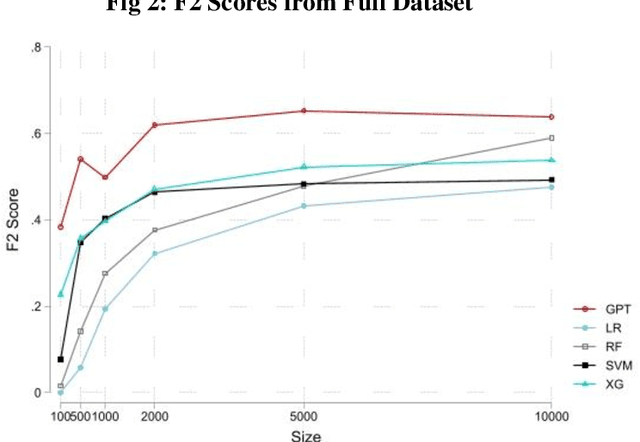


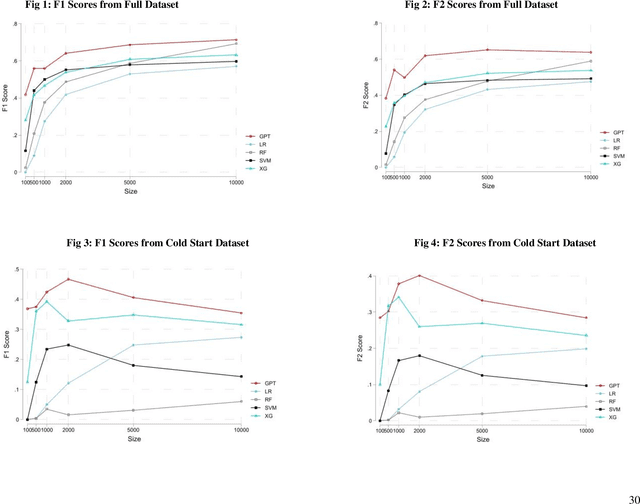
The proliferation of fake reviews of doctors has potentially detrimental consequences for patient well-being and has prompted concern among consumer protection groups and regulatory bodies. Yet despite significant advancements in the fields of machine learning and natural language processing, there remains limited comprehension of the characteristics differentiating fraudulent from authentic reviews. This study utilizes a novel pre-labeled dataset of 38048 physician reviews to establish the effectiveness of large language models in classifying reviews. Specifically, we compare the performance of traditional ML models, such as logistic regression and support vector machines, to generative pre-trained transformer models. Furthermore, we use GPT4, the newest model in the GPT family, to uncover the key dimensions along which fake and genuine physician reviews differ. Our findings reveal significantly superior performance of GPT-3 over traditional ML models in this context. Additionally, our analysis suggests that GPT3 requires a smaller training sample than traditional models, suggesting its appropriateness for tasks with scarce training data. Moreover, the superiority of GPT3 performance increases in the cold start context i.e., when there are no prior reviews of a doctor. Finally, we employ GPT4 to reveal the crucial dimensions that distinguish fake physician reviews. In sharp contrast to previous findings in the literature that were obtained using simulated data, our findings from a real-world dataset show that fake reviews are generally more clinically detailed, more reserved in sentiment, and have better structure and grammar than authentic ones.
Finding patterns in Knowledge Attribution for Transformers
May 04, 2022
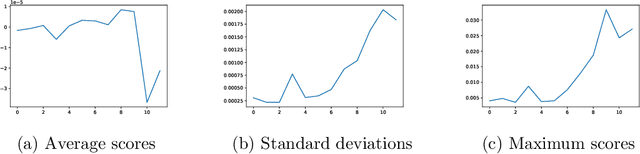
We analyze the Knowledge Neurons framework for the attribution of factual and relational knowledge to particular neurons in the transformer network. We use a 12-layer multi-lingual BERT model for our experiments. Our study reveals various interesting phenomena. We observe that mostly factual knowledge can be attributed to middle and higher layers of the network($\ge 6$). Further analysis reveals that the middle layers($6-9$) are mostly responsible for relational information, which is further refined into actual factual knowledge or the "correct answer" in the last few layers($10-12$). Our experiments also show that the model handles prompts in different languages, but representing the same fact, similarly, providing further evidence for effectiveness of multi-lingual pre-training. Applying the attribution scheme for grammatical knowledge, we find that grammatical knowledge is far more dispersed among the neurons than factual knowledge.