 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
Mar 11, 2025Large Language Models (LLMs) have made significant progress in open-ended dialogue, yet their inability to retain and retrieve relevant information from long-term interactions limits their effectiveness in applications requiring sustained personalization. External memory mechanisms have been proposed to address this limitation, enabling LLMs to maintain conversational continuity. However, existing approaches struggle with two key challenges. First, rigid memory granularity fails to capture the natural semantic structure of conversations, leading to fragmented and incomplete representations. Second, fixed retrieval mechanisms cannot adapt to diverse dialogue contexts and user interaction patterns. In this work, we propose Reflective Memory Management (RMM), a novel mechanism for long-term dialogue agents, integrating forward- and backward-looking reflections: (1) Prospective Reflection, which dynamically summarizes interactions across granularities-utterances, turns, and sessions-into a personalized memory bank for effective future retrieval, and (2) Retrospective Reflection, which iteratively refines the retrieval in an online reinforcement learning (RL) manner based on LLMs' cited evidence. Experiments show that RMM demonstrates consistent improvement across various metrics and benchmarks. For example, RMM shows more than 10% accuracy improvement over the baseline without memory management on the LongMemEval dataset.
eMoE: Task-aware Memory Efficient Mixture-of-Experts-Based (MoE) Model Inference
Mar 10, 2025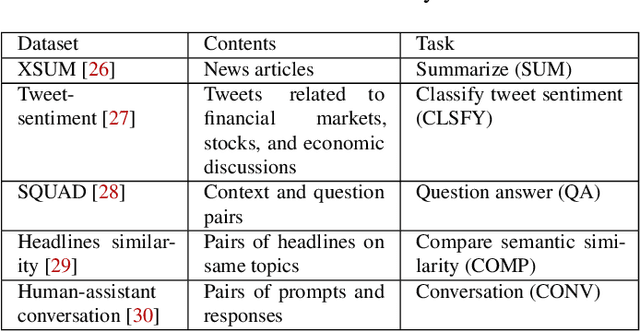
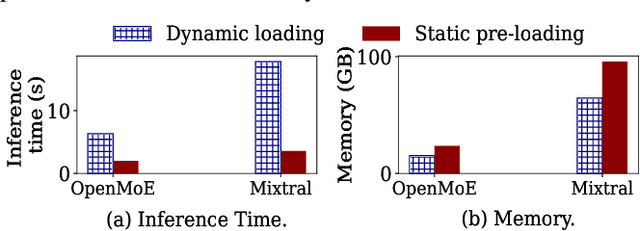
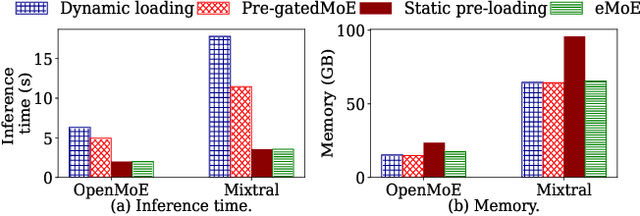
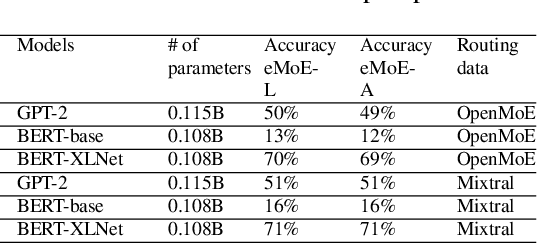
In recent years, Mixture-of-Experts (MoE) has emerged as an effective approach for enhancing the capacity of deep neural network (DNN) with sub-linear computational costs. However, storing all experts on GPUs incurs significant memory overhead, increasing the monetary cost of MoE-based inference. To address this, we propose eMoE, a memory efficient inference system for MoE-based large language models (LLMs) by leveraging our observations from experiment measurements. eMoE reduces memory usage by predicting and loading only the required experts based on recurrent patterns in expert routing. To reduce loading latency while maintaining accuracy, as we found using the same experts for subsequent prompts has minimal impact on perplexity, eMoE invokes the expert predictor every few prompts rather than for each prompt. In addition, it skips predictions for tasks less sensitive to routing accuracy. Finally, it has task-aware scheduling to minimize inference latency by considering Service Level Objectives (SLOs), task-specific output lengths, and expert loading latencies. Experimental results show that compared to existing systems, eMoE reduces memory consumption by up to 80% while maintaining accuracy and reduces inference latency by up to 17%. It also enables processing prompts 40x longer, batches 4.5x larger, and achieves 1.5x higher throughput.
OMEGA: A Low-Latency GNN Serving System for Large Graphs
Jan 15, 2025



Graph Neural Networks (GNNs) have been widely adopted for their ability to compute expressive node representations in graph datasets. However, serving GNNs on large graphs is challenging due to the high communication, computation, and memory overheads of constructing and executing computation graphs, which represent information flow across large neighborhoods. Existing approximation techniques in training can mitigate the overheads but, in serving, still lead to high latency and/or accuracy loss. To this end, we propose OMEGA, a system that enables low-latency GNN serving for large graphs with minimal accuracy loss through two key ideas. First, OMEGA employs selective recomputation of precomputed embeddings, which allows for reusing precomputed computation subgraphs while selectively recomputing a small fraction to minimize accuracy loss. Second, we develop computation graph parallelism, which reduces communication overhead by parallelizing the creation and execution of computation graphs across machines. Our evaluation with large graph datasets and GNN models shows that OMEGA significantly outperforms state-of-the-art techniques.
Let Curves Speak: A Continuous Glucose Monitor based Large Sensor Foundation Model for Diabetes Management
Dec 12, 2024



While previous studies of AI in diabetes management focus on long-term risk, research on near-future glucose prediction remains limited but important as it enables timely diabetes self-management. Integrating AI with continuous glucose monitoring (CGM) holds promise for near-future glucose prediction. However, existing models have limitations in capturing patterns of blood glucose fluctuations and demonstrate poor generalizability. A robust approach is needed to leverage massive CGM data for near-future glucose prediction. We propose large sensor models (LSMs) to capture knowledge in CGM data by modeling patients as sequences of glucose. CGM-LSM is pretrained on 15.96 million glucose records from 592 diabetes patients for near-future glucose prediction. We evaluated CGM-LSM against state-of-the-art methods using the OhioT1DM dataset across various metrics, prediction horizons, and unseen patients. Additionally, we assessed its generalizability across factors like diabetes type, age, gender, and hour of day. CGM-LSM achieved exceptional performance, with an rMSE of 29.81 mg/dL for type 1 diabetes patients and 23.49 mg/dL for type 2 diabetes patients in a two-hour prediction horizon. For the OhioT1DM dataset, CGM-LSM achieved a one-hour rMSE of 15.64 mg/dL, halving the previous best of 31.97 mg/dL. Robustness analyses revealed consistent performance not only for unseen patients and future periods, but also across diabetes type, age, and gender. The model demonstrated adaptability to different hours of day, maintaining accuracy across periods of various activity intensity levels. CGM-LSM represents a transformative step in diabetes management by leveraging pretraining to uncover latent glucose generation patterns in sensor data. Our findings also underscore the broader potential of LSMs to drive innovation across domains involving complex sensor data.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Apparate: Rethinking Early Exits to Tame Latency-Throughput Tensions in ML Serving
Dec 08, 2023Machine learning (ML) inference platforms are tasked with balancing two competing goals: ensuring high throughput given many requests, and delivering low-latency responses to support interactive applications. Unfortunately, existing platform knobs (e.g., batch sizes) fail to ease this fundamental tension, and instead only enable users to harshly trade off one property for the other. This paper explores an alternate strategy to taming throughput-latency tradeoffs by changing the granularity at which inference is performed. We present Apparate, a system that automatically applies and manages early exits (EEs) in ML models, whereby certain inputs can exit with results at intermediate layers. To cope with the time-varying overhead and accuracy challenges that EEs bring, Apparate repurposes exits to provide continual feedback that powers several novel runtime monitoring and adaptation strategies. Apparate lowers median response latencies by 40.5-91.5% and 10.0-24.2% for diverse CV and NLP workloads, respectively, without affecting throughputs or violating tight accuracy constraints.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022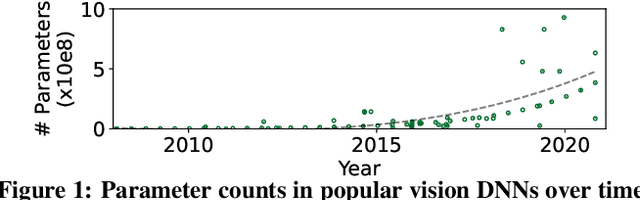
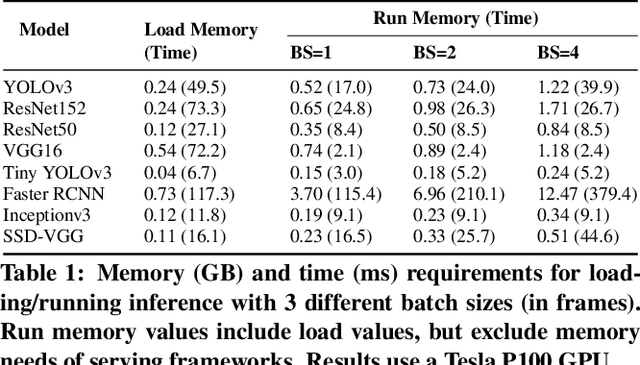
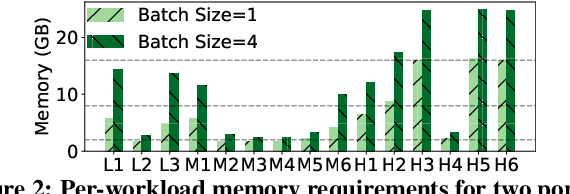

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
An Efficient Bandit Algorithm for Realtime Multivariate Optimization
Oct 22, 2018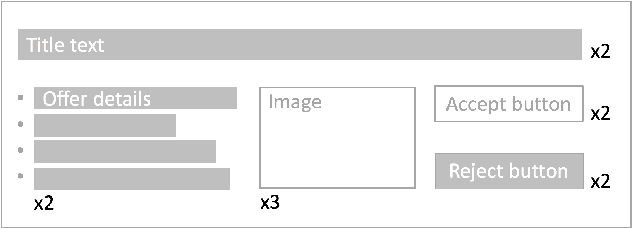
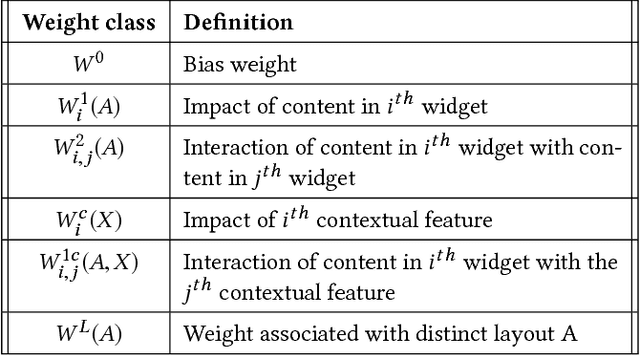


Optimization is commonly employed to determine the content of web pages, such as to maximize conversions on landing pages or click-through rates on search engine result pages. Often the layout of these pages can be decoupled into several separate decisions. For example, the composition of a landing page may involve deciding which image to show, which wording to use, what color background to display, etc. Such optimization is a combinatorial problem over an exponentially large decision space. Randomized experiments do not scale well to this setting, and therefore, in practice, one is typically limited to optimizing a single aspect of a web page at a time. This represents a missed opportunity in both the speed of experimentation and the exploitation of possible interactions between layout decisions. Here we focus on multivariate optimization of interactive web pages. We formulate an approach where the possible interactions between different components of the page are modeled explicitly. We apply bandit methodology to explore the layout space efficiently and use hill-climbing to select optimal content in realtime. Our algorithm also extends to contextualization and personalization of layout selection. Simulation results show the suitability of our approach to large decision spaces with strong interactions between content. We further apply our algorithm to optimize a message that promotes adoption of an Amazon service. After only a single week of online optimization, we saw a 21% conversion increase compared to the median layout. Our technique is currently being deployed to optimize content across several locations at Amazon.com.
* KDD'17 Audience Appreciation Award