 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMEGA: A Low-Latency GNN Serving System for Large Graphs
Jan 15, 2025



Graph Neural Networks (GNNs) have been widely adopted for their ability to compute expressive node representations in graph datasets. However, serving GNNs on large graphs is challenging due to the high communication, computation, and memory overheads of constructing and executing computation graphs, which represent information flow across large neighborhoods. Existing approximation techniques in training can mitigate the overheads but, in serving, still lead to high latency and/or accuracy loss. To this end, we propose OMEGA, a system that enables low-latency GNN serving for large graphs with minimal accuracy loss through two key ideas. First, OMEGA employs selective recomputation of precomputed embeddings, which allows for reusing precomputed computation subgraphs while selectively recomputing a small fraction to minimize accuracy loss. Second, we develop computation graph parallelism, which reduces communication overhead by parallelizing the creation and execution of computation graphs across machines. Our evaluation with large graph datasets and GNN models shows that OMEGA significantly outperforms state-of-the-art techniques.
Impact of RoCE Congestion Control Policies on Distributed Training of DNNs
Jul 22, 2022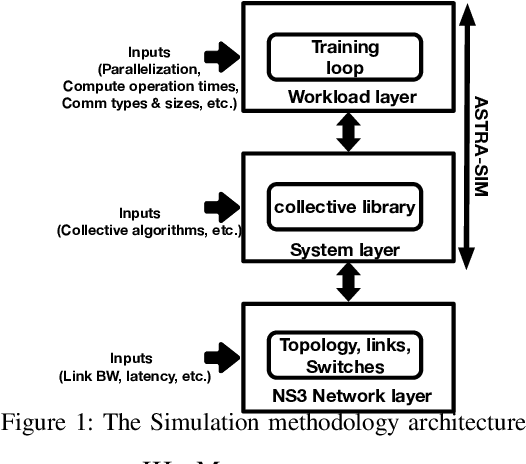
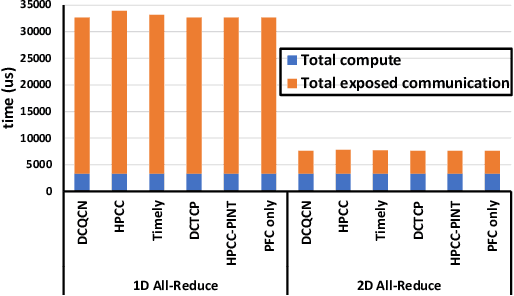
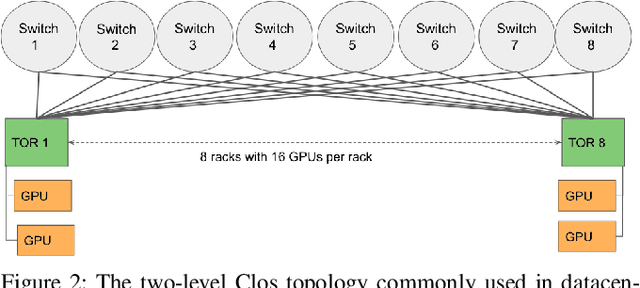
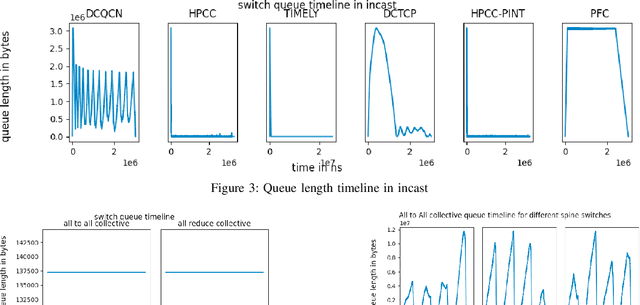
RDMA over Converged Ethernet (RoCE) has gained significant attraction for datacenter networks due to its compatibility with conventional Ethernet-based fabric. However, the RDMA protocol is efficient only on (nearly) lossless networks, emphasizing the vital role of congestion control on RoCE networks. Unfortunately, the native RoCE congestion control scheme, based on Priority Flow Control (PFC), suffers from many drawbacks such as unfairness, head-of-line-blocking, and deadlock. Therefore, in recent years many schemes have been proposed to provide additional congestion control for RoCE networks to minimize PFC drawbacks. However, these schemes are proposed for general datacenter environments. In contrast to the general datacenters that are built using commodity hardware and run general-purpose workloads, high-performance distributed training platforms deploy high-end accelerators and network components and exclusively run training workloads using collectives (All-Reduce, All-To-All) communication libraries for communication. Furthermore, these platforms usually have a private network, separating their communication traffic from the rest of the datacenter traffic. Scalable topology-aware collective algorithms are inherently designed to avoid incast patterns and balance traffic optimally. These distinct features necessitate revisiting previously proposed congestion control schemes for general-purpose datacenter environments. In this paper, we thoroughly analyze some of the SOTA RoCE congestion control schemes vs. PFC when running on distributed training platforms. Our results indicate that previously proposed RoCE congestion control schemes have little impact on the end-to-end performance of training workloads, motivating the necessity of designing an optimized, yet low-overhead, congestion control scheme based on the characteristics of distributed training platforms and workloads.