 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAGE: A Symbolic Tensor grAph GEnerator for distributed AI system co-design
Nov 14, 2025Optimizing the performance of large language models (LLMs) on large-scale AI training and inference systems requires a scalable and expressive mechanism to model distributed workload execution. Such modeling is essential for pre-deployment system-level optimizations (e.g., parallelization strategies) and design-space explorations. While recent efforts have proposed collecting execution traces from real systems, access to large-scale infrastructure remains limited to major cloud providers. Moreover, traces obtained from existing platforms cannot be easily adapted to study future larger-scale system configurations. We introduce Symbolic Tensor grAph GEnerator(STAGE), a framework that synthesizes high-fidelity execution traces to accurately model LLM workloads. STAGE supports a comprehensive set of parallelization strategies, allowing users to systematically explore a wide spectrum of LLM architectures and system configurations. STAGE demonstrates its scalability by synthesizing high-fidelity LLM traces spanning over 32K GPUs, while preserving tensor-level accuracy in compute, memory, and communication. STAGE is publicly available to facilitate further research in distributed machine learning systems: https://github.com/astra-sim/symbolic tensor graph
Maya: Optimizing Deep Learning Training Workloads using Emulated Virtual Accelerators
Mar 26, 2025



Training large foundation models costs hundreds of millions of dollars, making deployment optimization critical. Current approaches require machine learning engineers to manually craft training recipes through error-prone trial-and-error on expensive compute clusters. To enable efficient exploration of training configurations, researchers have developed performance modeling systems. However, these systems force users to translate their workloads into custom specification languages, introducing a fundamental semantic gap between the actual workload and its representation. This gap creates an inherent tradeoff: systems must either support a narrow set of workloads to maintain usability, require complex specifications that limit practical adoption, or compromise prediction accuracy with simplified models. We present Maya, a performance modeling system that eliminates these tradeoffs through transparent device emulation. By operating at the narrow interface between training frameworks and accelerator devices, Maya can capture complete workload behavior without requiring code modifications or translations. Maya intercepts device API calls from unmodified training code to directly observe low-level operations, enabling accurate performance prediction while maintaining both ease of use and generality. Our evaluation shows Maya achieves less than 5% prediction error across diverse models and optimization strategies, identifying configurations that reduce training costs by up to 56% compared to existing approaches.
LayerDAG: A Layerwise Autoregressive Diffusion Model for Directed Acyclic Graph Generation
Nov 04, 2024



Directed acyclic graphs (DAGs) serve as crucial data representations in domains such as hardware synthesis and compiler/program optimization for computing systems. DAG generative models facilitate the creation of synthetic DAGs, which can be used for benchmarking computing systems while preserving intellectual property. However, generating realistic DAGs is challenging due to their inherent directional and logical dependencies. This paper introduces LayerDAG, an autoregressive diffusion model, to address these challenges. LayerDAG decouples the strong node dependencies into manageable units that can be processed sequentially. By interpreting the partial order of nodes as a sequence of bipartite graphs, LayerDAG leverages autoregressive generation to model directional dependencies and employs diffusion models to capture logical dependencies within each bipartite graph. Comparative analyses demonstrate that LayerDAG outperforms existing DAG generative models in both expressiveness and generalization, particularly for generating large-scale DAGs with up to 400 nodes-a critical scenario for system benchmarking. Extensive experiments on both synthetic and real-world flow graphs from various computing platforms show that LayerDAG generates valid DAGs with superior statistical properties and benchmarking performance. The synthetic DAGs generated by LayerDAG enhance the training of ML-based surrogate models, resulting in improved accuracy in predicting performance metrics of real-world DAGs across diverse computing platforms.
Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
May 26, 2023



Benchmarking and co-design are essential for driving optimizations and innovation around ML models, ML software, and next-generation hardware. Full workload benchmarks, e.g. MLPerf, play an essential role in enabling fair comparison across different software and hardware stacks especially once systems are fully designed and deployed. However, the pace of AI innovation demands a more agile methodology to benchmark creation and usage by simulators and emulators for future system co-design. We propose Chakra, an open graph schema for standardizing workload specification capturing key operations and dependencies, also known as Execution Trace (ET). In addition, we propose a complementary set of tools/capabilities to enable collection, generation, and adoption of Chakra ETs by a wide range of simulators, emulators, and benchmarks. For instance, we use generative AI models to learn latent statistical properties across thousands of Chakra ETs and use these models to synthesize Chakra ETs. These synthetic ETs can obfuscate key proprietary information and also target future what-if scenarios. As an example, we demonstrate an end-to-end proof-of-concept that converts PyTorch ETs to Chakra ETs and uses this to drive an open-source training system simulator (ASTRA-sim). Our end-goal is to build a vibrant industry-wide ecosystem of agile benchmarks and tools to drive future AI system co-design.
ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale
Mar 24, 2023As deep learning models and input data are scaling at an unprecedented rate, it is inevitable to move towards distributed training platforms to fit the model and increase training throughput. State-of-the-art approaches and techniques, such as wafer-scale nodes, multi-dimensional network topologies, disaggregated memory systems, and parallelization strategies, have been actively adopted by emerging distributed training systems. This results in a complex SW/HW co-design stack of distributed training, necessitating a modeling/simulation infrastructure for design-space exploration. In this paper, we extend the open-source ASTRA-sim infrastructure and endow it with the capabilities to model state-of-the-art and emerging distributed training models and platforms. More specifically, (i) we enable ASTRA-sim to support arbitrary model parallelization strategies via a graph-based training-loop implementation, (ii) we implement a parameterizable multi-dimensional heterogeneous topology generation infrastructure with analytical performance estimates enabling simulating target systems at scale, and (iii) we enhance the memory system modeling to support accurate modeling of in-network collective communication and disaggregated memory systems. With such capabilities, we run comprehensive case studies targeting emerging distributed models and platforms. This infrastructure lets system designers swiftly traverse the complex co-design stack and give meaningful insights when designing and deploying distributed training platforms at scale.
Mystique: Accurate and Scalable Production AI Benchmarks Generation
Dec 16, 2022



Building and maintaining large AI fleets to efficiently support the fast-growing DL workloads is an active research topic for modern cloud infrastructure providers. Generating accurate benchmarks plays an essential role in the design and evaluation of rapidly evoloving software and hardware solutions in this area. Two fundamental challenges to make this process scalable are (i) workload representativeness and (ii) the ability to quickly incorporate changes to the fleet into the benchmarks. To overcome these issues, we propose Mystique, an accurate and scalable framework for production AI benchmark generation. It leverages the PyTorch execution graph (EG), a new feature that captures the runtime information of AI models at the granularity of operators, in a graph format, together with their metadata. By sourcing EG traces from the fleet, we can build AI benchmarks that are portable and representative. Mystique is scalable, with its lightweight data collection, in terms of runtime overhead and user instrumentation efforts. It is also adaptive, as the expressiveness and composability of EG format allows flexible user control over benchmark creation. We evaluate our methodology on several production AI workloads, and show that benchmarks generated with Mystique closely resemble original AI models, both in execution time and system-level metrics. We also showcase the portability of the generated benchmarks across platforms, and demonstrate several use cases enabled by the fine-grained composability of the execution graph.
Impact of RoCE Congestion Control Policies on Distributed Training of DNNs
Jul 22, 2022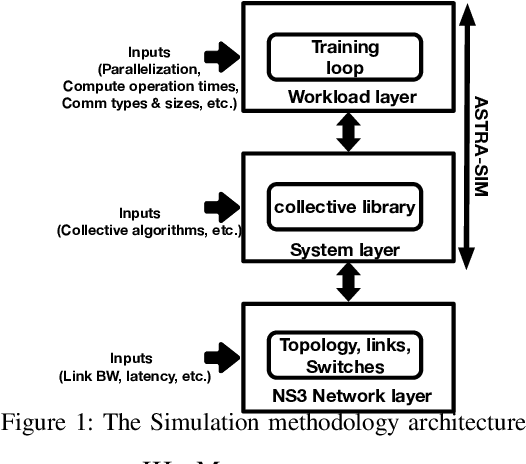
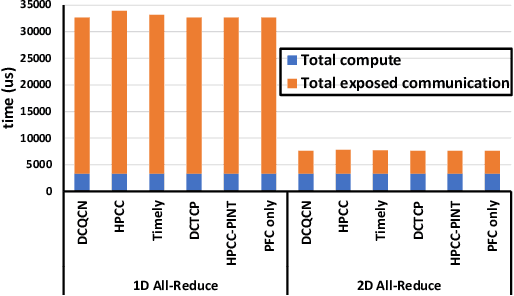
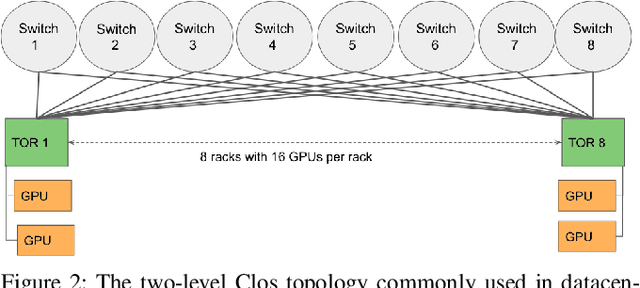
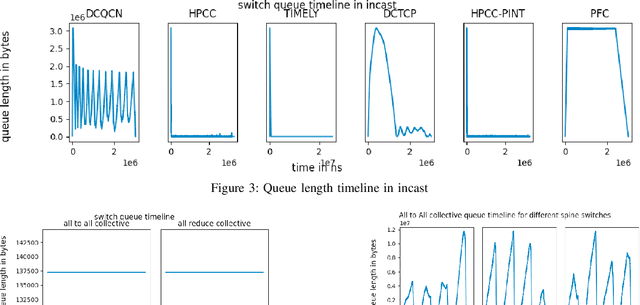
RDMA over Converged Ethernet (RoCE) has gained significant attraction for datacenter networks due to its compatibility with conventional Ethernet-based fabric. However, the RDMA protocol is efficient only on (nearly) lossless networks, emphasizing the vital role of congestion control on RoCE networks. Unfortunately, the native RoCE congestion control scheme, based on Priority Flow Control (PFC), suffers from many drawbacks such as unfairness, head-of-line-blocking, and deadlock. Therefore, in recent years many schemes have been proposed to provide additional congestion control for RoCE networks to minimize PFC drawbacks. However, these schemes are proposed for general datacenter environments. In contrast to the general datacenters that are built using commodity hardware and run general-purpose workloads, high-performance distributed training platforms deploy high-end accelerators and network components and exclusively run training workloads using collectives (All-Reduce, All-To-All) communication libraries for communication. Furthermore, these platforms usually have a private network, separating their communication traffic from the rest of the datacenter traffic. Scalable topology-aware collective algorithms are inherently designed to avoid incast patterns and balance traffic optimally. These distinct features necessitate revisiting previously proposed congestion control schemes for general-purpose datacenter environments. In this paper, we thoroughly analyze some of the SOTA RoCE congestion control schemes vs. PFC when running on distributed training platforms. Our results indicate that previously proposed RoCE congestion control schemes have little impact on the end-to-end performance of training workloads, motivating the necessity of designing an optimized, yet low-overhead, congestion control scheme based on the characteristics of distributed training platforms and workloads.
Themis: A Network Bandwidth-Aware Collective Scheduling Policy for Distributed Training of DL Models
Oct 09, 2021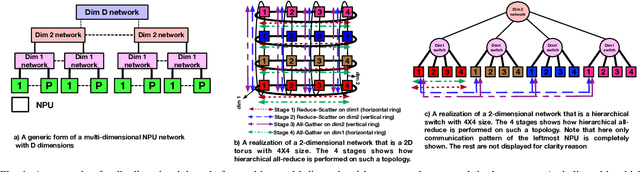



The continuous growth in both size and training data for modern Deep Neural Networks (DNNs) models has led to training tasks taking days or even months. Distributed training is a solution to reduce training time by splitting the task across multiple NPUs (e.g., GPU/TPU). However, distributed training adds communication overhead between the NPUs in order to synchronize the gradients and/or activation, depending on the parallelization strategy. In today's datacenters, for training at scale, NPUs are connected through multi-dimensional interconnection links with different bandwidth and latency. Hence, keeping all network dimensions busy and maximizing the network BW is a challenging task in such a hybrid network environment, as this work identifies. We propose Themis, a novel collective scheduling scheme that dynamically schedules collectives (divided into chunks) to balance the communication loads across all dimensions, further improving the network BW utilization. Our results show that on average, Themis can improve the network BW utilization of single All-Reduce by 1.88x (2.92x max), and improve the end-to-end training iteration performance of real workloads such as ResNet-50, GNMT, DLRM, and Transformer- 1T by 1.49x (1.96x max), 1.41x (1.81x max), 1.42x (1.80x max), and 1.35x (1.78x max), respectively.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021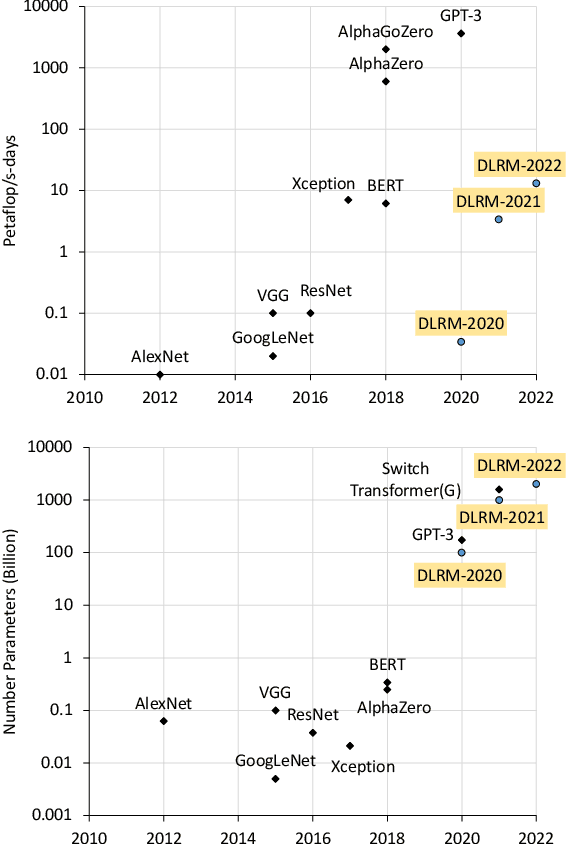

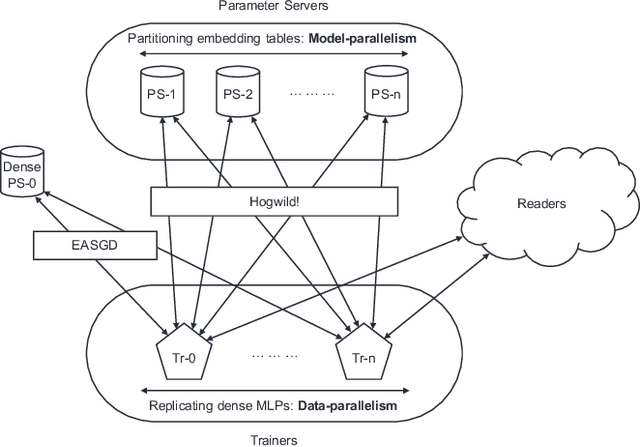
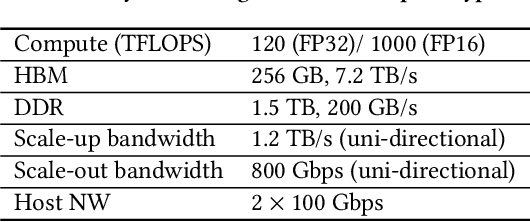
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Automatic Model Parallelism for Deep Neural Networks with Compiler and Hardware Support
Jun 11, 2019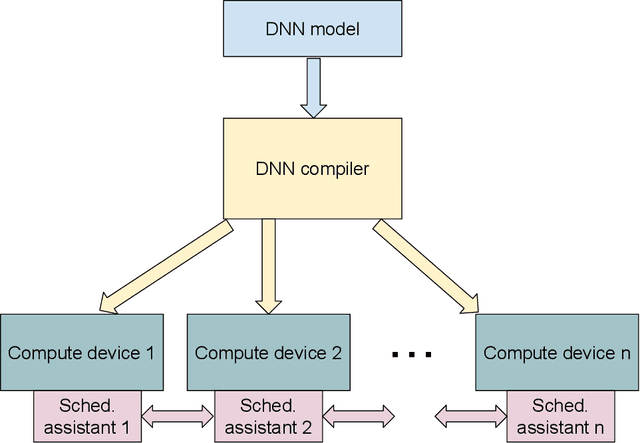
The deep neural networks (DNNs) have been enormously successful in tasks that were hitherto in the human-only realm such as image recognition, and language translation. Owing to their success the DNNs are being explored for use in ever more sophisticated tasks. One of the ways that the DNNs are made to scale for the complex undertakings is by increasing their size -- deeper and wider networks can model well the additional complexity. Such large models are trained using model parallelism on multiple compute devices such as multi-GPUs and multi-node systems. In this paper, we develop a compiler-driven approach to achieve model parallelism. We model the computation and communication costs of a dataflow graph that embodies the neural network training process and then, partition the graph using heuristics in such a manner that the communication between compute devices is minimal and we have a good load balance. The hardware scheduling assistants are proposed to assist the compiler in fine tuning the distribution of work at runtime.