 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Collide: Recommendation System Model Compression with Learned Hash Functions
Mar 28, 2022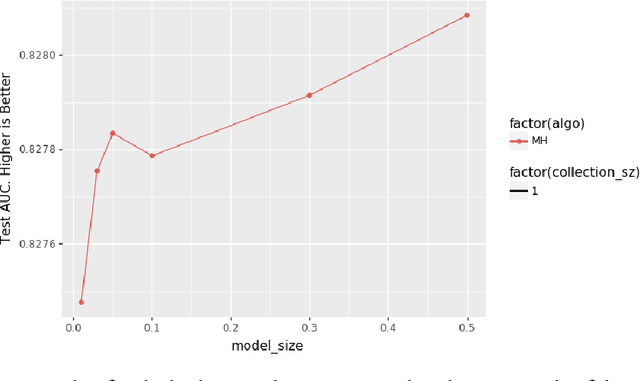

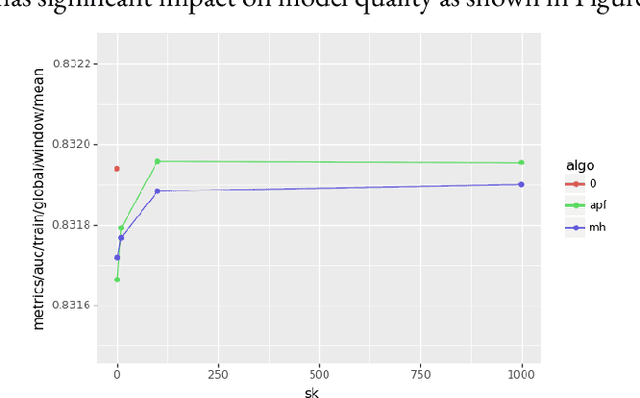
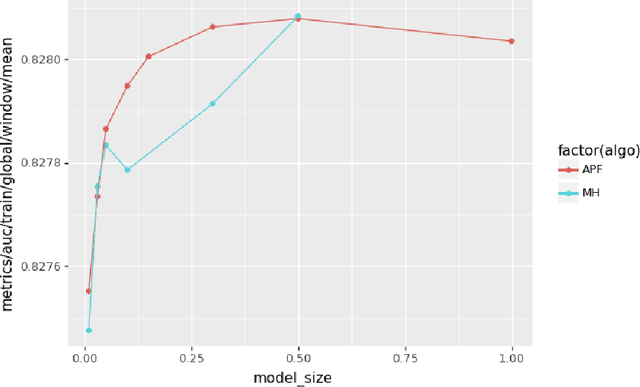
A key characteristic of deep recommendation models is the immense memory requirements of their embedding tables. These embedding tables can often reach hundreds of gigabytes which increases hardware requirements and training cost. A common technique to reduce model size is to hash all of the categorical variable identifiers (ids) into a smaller space. This hashing reduces the number of unique representations that must be stored in the embedding table; thus decreasing its size. However, this approach introduces collisions between semantically dissimilar ids that degrade model quality. We introduce an alternative approach, Learned Hash Functions, which instead learns a new mapping function that encourages collisions between semantically similar ids. We derive this learned mapping from historical data and embedding access patterns. We experiment with this technique on a production model and find that a mapping informed by the combination of access frequency and a learned low dimension embedding is the most effective. We demonstrate a small improvement relative to the hashing trick and other collision related compression techniques. This is ongoing work that explores the impact of categorical id collisions on recommendation model quality and how those collisions may be controlled to improve model performance.
Understanding and Co-designing the Data Ingestion Pipeline for Industry-Scale RecSys Training
Aug 20, 2021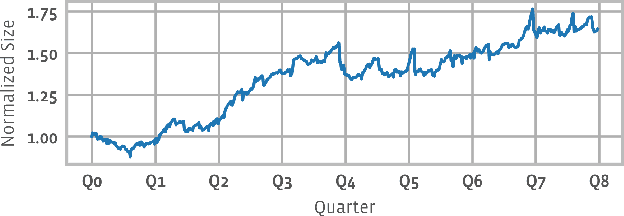
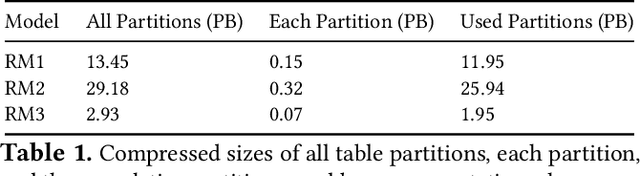
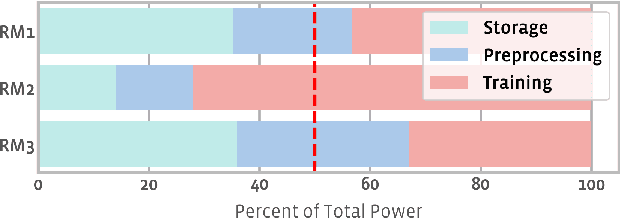

The data ingestion pipeline, responsible for storing and preprocessing training data, is an important component of any machine learning training job. At Facebook, we use recommendation models extensively across our services. The data ingestion requirements to train these models are substantial. In this paper, we present an extensive characterization of the data ingestion challenges for industry-scale recommendation model training. First, dataset storage requirements are massive and variable; exceeding local storage capacities. Secondly, reading and preprocessing data is computationally expensive, requiring substantially more compute, memory, and network resources than are available on trainers themselves. These demands result in drastically reduced training throughput, and thus wasted GPU resources, when current on-trainer preprocessing solutions are used. To address these challenges, we present a disaggregated data ingestion pipeline. It includes a central data warehouse built on distributed storage nodes. We introduce Data PreProcessing Service (DPP), a fully disaggregated preprocessing service that scales to hundreds of nodes, eliminating data stalls that can reduce training throughput by 56%. We implement important optimizations across storage and DPP, increasing storage and preprocessing throughput by 1.9x and 2.3x, respectively, addressing the substantial power requirements of data ingestion. We close with lessons learned and cover the important remaining challenges and opportunities surrounding data ingestion at scale.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021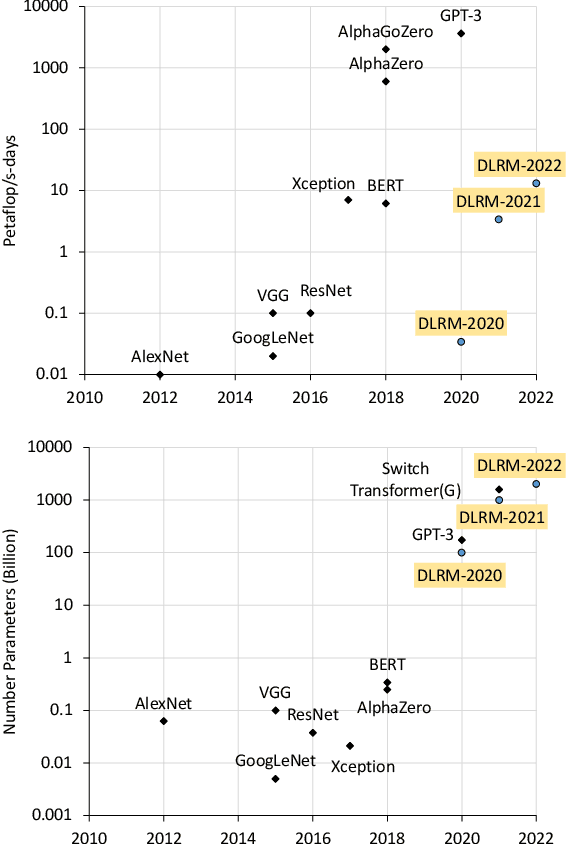

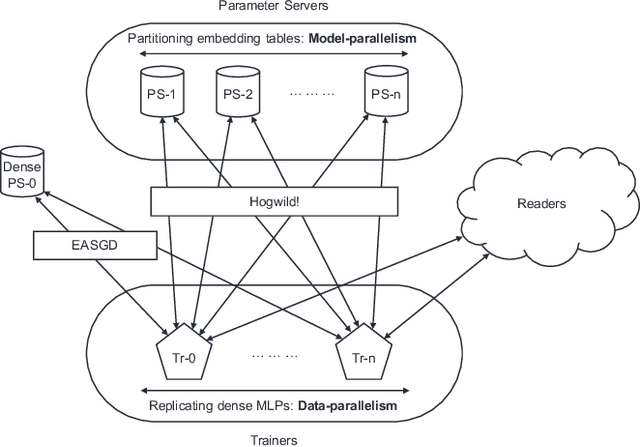
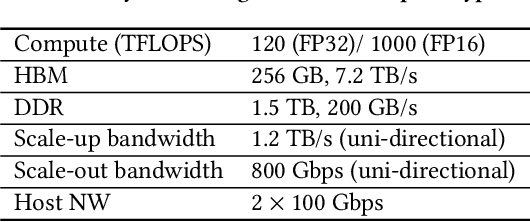
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.