 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
Feb 12, 2026We propose UniDFlow, a unified discrete flow-matching framework for multimodal understanding, generation, and editing. It decouples understanding and generation via task-specific low-rank adapters, avoiding objective interference and representation entanglement, while a novel reference-based multimodal preference alignment optimizes relative outcomes under identical conditioning, improving faithfulness and controllability without large-scale retraining. UniDFlpw achieves SOTA performance across eight benchmarks and exhibits strong zero-shot generalization to tasks including inpainting, in-context image generation, reference-based editing, and compositional generation, despite no explicit task-specific training.
Fluidity Index: Next-Generation Super-intelligence Benchmarks
Oct 23, 2025This paper introduces the Fluidity Index (FI) to quantify model adaptability in dynamic, scaling environments. The benchmark evaluates response accuracy based on deviations in initial, current, and future environment states, assessing context switching and continuity. We distinguish between closed-ended and open-ended benchmarks, prioritizing closed-loop open-ended real-world benchmarks to test adaptability. The approach measures a model's ability to understand, predict, and adjust to state changes in scaling environments. A truly super-intelligent model should exhibit at least second-order adaptability, enabling self-sustained computation through digital replenishment for optimal fluidity.
Reconstructing Turbulent Flows Using Physics-Aware Spatio-Temporal Dynamics and Test-Time Refinement
Apr 24, 2023Simulating turbulence is critical for many societally important applications in aerospace engineering, environmental science, the energy industry, and biomedicine. Large eddy simulation (LES) has been widely used as an alternative to direct numerical simulation (DNS) for simulating turbulent flows due to its reduced computational cost. However, LES is unable to capture all of the scales of turbulent transport accurately. Reconstructing DNS from low-resolution LES is critical for many scientific and engineering disciplines, but it poses many challenges to existing super-resolution methods due to the spatio-temporal complexity of turbulent flows. In this work, we propose a new physics-guided neural network for reconstructing the sequential DNS from low-resolution LES data. The proposed method leverages the partial differential equation that underlies the flow dynamics in the design of spatio-temporal model architecture. A degradation-based refinement method is also developed to enforce physical constraints and further reduce the accumulated reconstruction errors over long periods. The results on two different types of turbulent flow data confirm the superiority of the proposed method in reconstructing the high-resolution DNS data and preserving the physical characteristics of flow transport.
Understanding and Co-designing the Data Ingestion Pipeline for Industry-Scale RecSys Training
Aug 20, 2021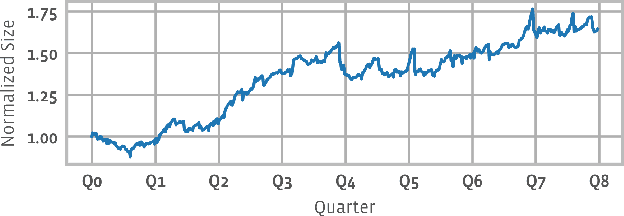
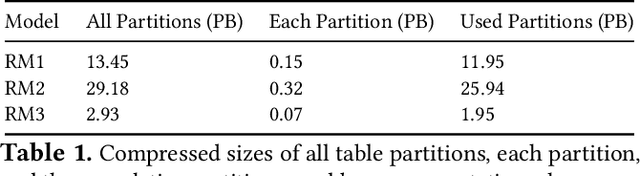
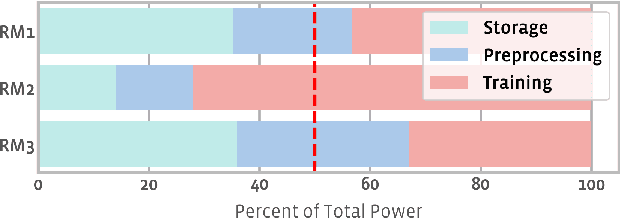

The data ingestion pipeline, responsible for storing and preprocessing training data, is an important component of any machine learning training job. At Facebook, we use recommendation models extensively across our services. The data ingestion requirements to train these models are substantial. In this paper, we present an extensive characterization of the data ingestion challenges for industry-scale recommendation model training. First, dataset storage requirements are massive and variable; exceeding local storage capacities. Secondly, reading and preprocessing data is computationally expensive, requiring substantially more compute, memory, and network resources than are available on trainers themselves. These demands result in drastically reduced training throughput, and thus wasted GPU resources, when current on-trainer preprocessing solutions are used. To address these challenges, we present a disaggregated data ingestion pipeline. It includes a central data warehouse built on distributed storage nodes. We introduce Data PreProcessing Service (DPP), a fully disaggregated preprocessing service that scales to hundreds of nodes, eliminating data stalls that can reduce training throughput by 56%. We implement important optimizations across storage and DPP, increasing storage and preprocessing throughput by 1.9x and 2.3x, respectively, addressing the substantial power requirements of data ingestion. We close with lessons learned and cover the important remaining challenges and opportunities surrounding data ingestion at scale.