 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-organizing multi-agent system for distributed voltage regulation
Feb 01, 2022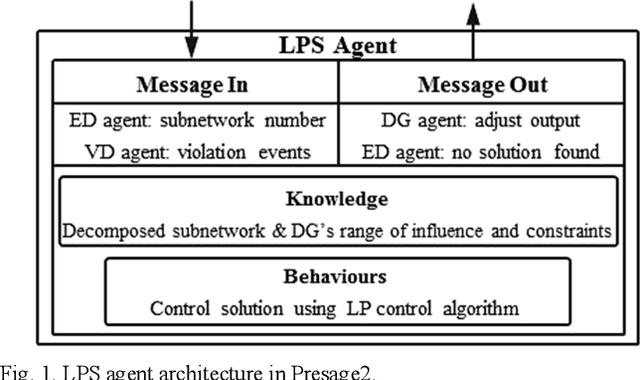
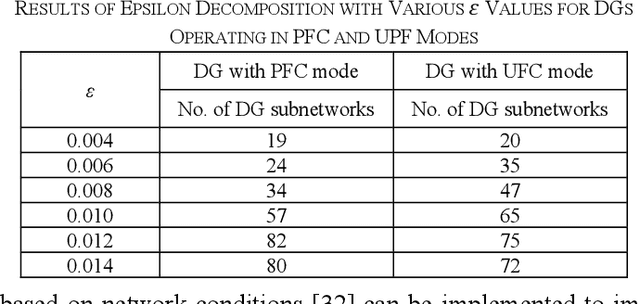
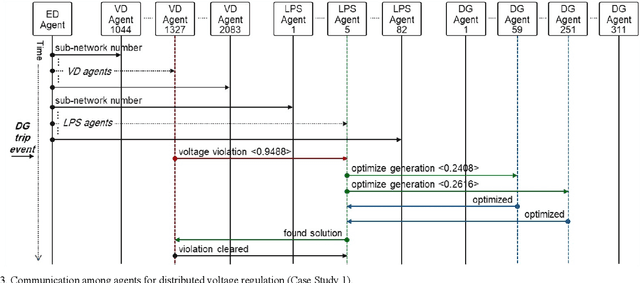
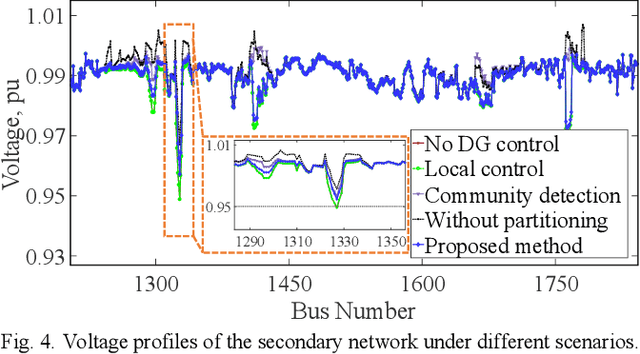
This paper presents a distributed voltage regulation method based on multi-agent system control and network self-organization for a large distribution network. The network autonomously organizes itself into small subnetworks through the epsilon decomposition of the sensitivity matrix, and agents group themselves into these subnetworks with the communication links being autonomously determined. Each subnetwork controls its voltage by locating the closest local distributed generation and optimizing their outputs. This simplifies and reduces the size of the optimization problem and the interaction requirements. This approach also facilitates adaptive grouping of the network by self-reorganizing to maintain a stable state in response to time-varying network requirements and changes. The effectiveness of the proposed approach is validated through simulations on a model of a real heavily-meshed secondary distribution network. Simulation results and comparisons with other methods demonstrate the ability of the subnetworks to autonomously and independently regulate the voltage and to adapt to unpredictable network conditions over time, thereby enabling autonomous and flexible distribution networks.
Understanding and Co-designing the Data Ingestion Pipeline for Industry-Scale RecSys Training
Aug 20, 2021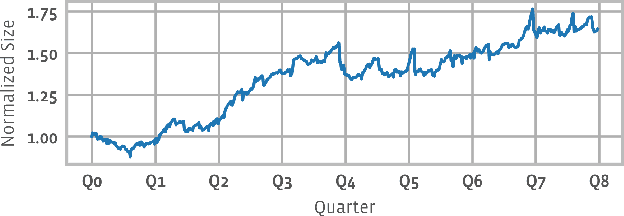
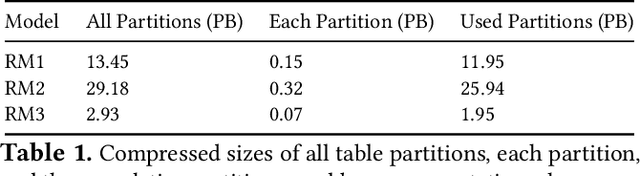
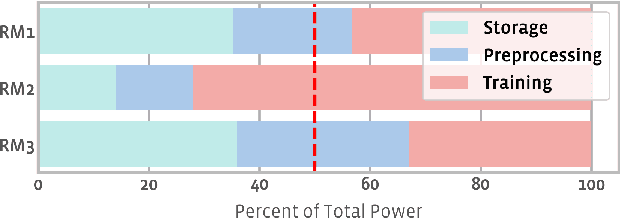

The data ingestion pipeline, responsible for storing and preprocessing training data, is an important component of any machine learning training job. At Facebook, we use recommendation models extensively across our services. The data ingestion requirements to train these models are substantial. In this paper, we present an extensive characterization of the data ingestion challenges for industry-scale recommendation model training. First, dataset storage requirements are massive and variable; exceeding local storage capacities. Secondly, reading and preprocessing data is computationally expensive, requiring substantially more compute, memory, and network resources than are available on trainers themselves. These demands result in drastically reduced training throughput, and thus wasted GPU resources, when current on-trainer preprocessing solutions are used. To address these challenges, we present a disaggregated data ingestion pipeline. It includes a central data warehouse built on distributed storage nodes. We introduce Data PreProcessing Service (DPP), a fully disaggregated preprocessing service that scales to hundreds of nodes, eliminating data stalls that can reduce training throughput by 56%. We implement important optimizations across storage and DPP, increasing storage and preprocessing throughput by 1.9x and 2.3x, respectively, addressing the substantial power requirements of data ingestion. We close with lessons learned and cover the important remaining challenges and opportunities surrounding data ingestion at scale.