 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Weakly Supervised Pre-Training of Visual Perception Models
Jan 20, 2022



Model pre-training is a cornerstone of modern visual recognition systems. Although fully supervised pre-training on datasets like ImageNet is still the de-facto standard, recent studies suggest that large-scale weakly supervised pre-training can outperform fully supervised approaches. This paper revisits weakly-supervised pre-training of models using hashtag supervision with modern versions of residual networks and the largest-ever dataset of images and corresponding hashtags. We study the performance of the resulting models in various transfer-learning settings including zero-shot transfer. We also compare our models with those obtained via large-scale self-supervised learning. We find our weakly-supervised models to be very competitive across all settings, and find they substantially outperform their self-supervised counterparts. We also include an investigation into whether our models learned potentially troubling associations or stereotypes. Overall, our results provide a compelling argument for the use of weakly supervised learning in the development of visual recognition systems. Our models, Supervised Weakly through hashtAGs (SWAG), are available publicly.
Understanding and Co-designing the Data Ingestion Pipeline for Industry-Scale RecSys Training
Aug 20, 2021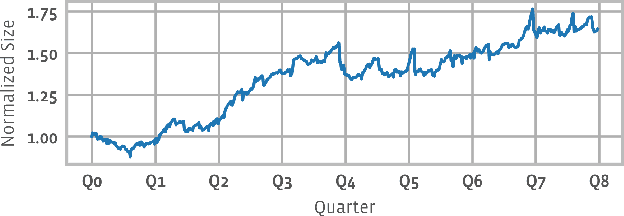
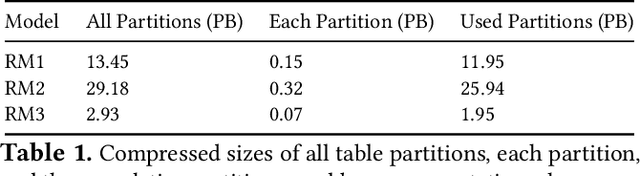
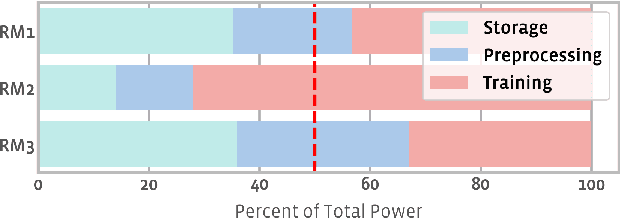

The data ingestion pipeline, responsible for storing and preprocessing training data, is an important component of any machine learning training job. At Facebook, we use recommendation models extensively across our services. The data ingestion requirements to train these models are substantial. In this paper, we present an extensive characterization of the data ingestion challenges for industry-scale recommendation model training. First, dataset storage requirements are massive and variable; exceeding local storage capacities. Secondly, reading and preprocessing data is computationally expensive, requiring substantially more compute, memory, and network resources than are available on trainers themselves. These demands result in drastically reduced training throughput, and thus wasted GPU resources, when current on-trainer preprocessing solutions are used. To address these challenges, we present a disaggregated data ingestion pipeline. It includes a central data warehouse built on distributed storage nodes. We introduce Data PreProcessing Service (DPP), a fully disaggregated preprocessing service that scales to hundreds of nodes, eliminating data stalls that can reduce training throughput by 56%. We implement important optimizations across storage and DPP, increasing storage and preprocessing throughput by 1.9x and 2.3x, respectively, addressing the substantial power requirements of data ingestion. We close with lessons learned and cover the important remaining challenges and opportunities surrounding data ingestion at scale.