 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
NOMAD Projection
May 21, 2025The rapid adoption of generative AI has driven an explosion in the size of datasets consumed and produced by AI models. Traditional methods for unstructured data visualization, such as t-SNE and UMAP, have not kept up with the pace of dataset scaling. This presents a significant challenge for AI explainability, which relies on methods such as t-SNE and UMAP for exploratory data analysis. In this paper, we introduce Negative Or Mean Affinity Discrimination (NOMAD) Projection, the first method for unstructured data visualization via nonlinear dimensionality reduction that can run on multiple GPUs at train time. We provide theory that situates NOMAD Projection as an approximate upper bound on the InfoNC-t-SNE loss, and empirical results that demonstrate NOMAD Projection's superior performance and speed profile compared to existing state-of-the-art methods. We demonstrate the scalability of NOMAD Projection by computing the first complete data map of Multilingual Wikipedia.
RoFL: Robust Fingerprinting of Language Models
May 19, 2025AI developers are releasing large language models (LLMs) under a variety of different licenses. Many of these licenses restrict the ways in which the models or their outputs may be used. This raises the question how license violations may be recognized. In particular, how can we identify that an API or product uses (an adapted version of) a particular LLM? We present a new method that enable model developers to perform such identification via fingerprints: statistical patterns that are unique to the developer's model and robust to common alterations of that model. Our method permits model identification in a black-box setting using a limited number of queries, enabling identification of models that can only be accessed via an API or product. The fingerprints are non-invasive: our method does not require any changes to the model during training, hence by design, it does not impact model quality. Empirically, we find our method provides a high degree of robustness to common changes in the model or inference settings. In our experiments, it substantially outperforms prior art, including invasive methods that explicitly train watermarks into the model.
Law of the Weakest Link: Cross Capabilities of Large Language Models
Sep 30, 2024
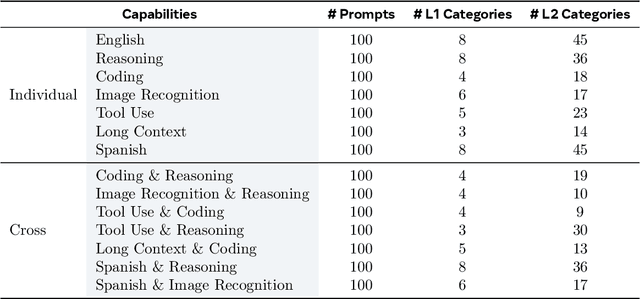
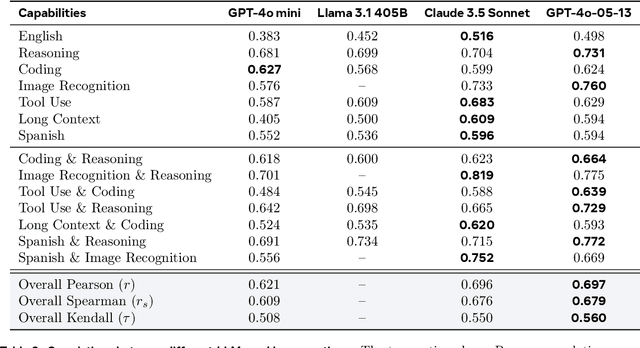
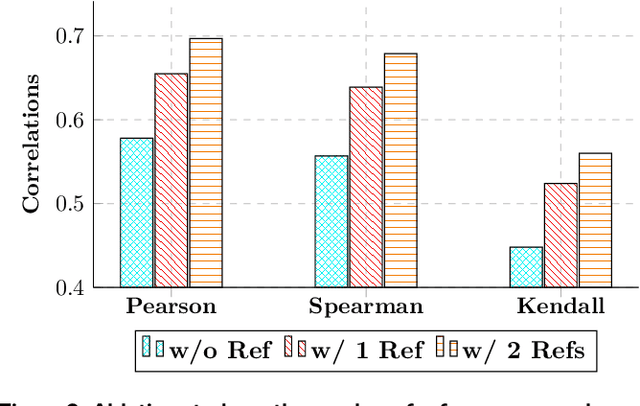
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Guarantees of confidentiality via Hammersley-Chapman-Robbins bounds
Apr 06, 2024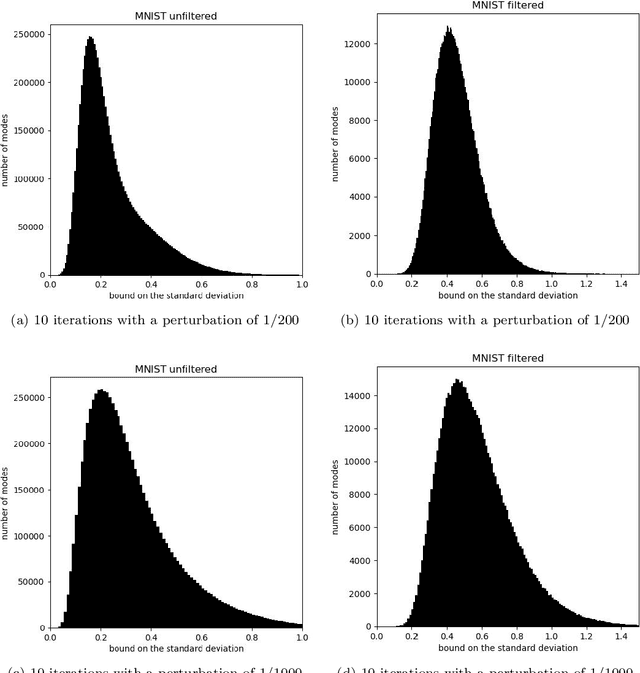

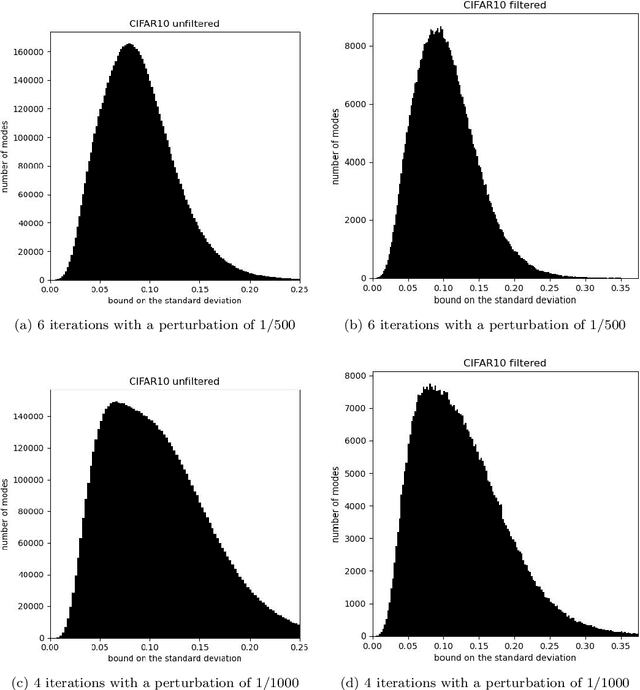

Protecting privacy during inference with deep neural networks is possible by adding noise to the activations in the last layers prior to the final classifiers or other task-specific layers. The activations in such layers are known as "features" (or, less commonly, as "embeddings" or "feature embeddings"). The added noise helps prevent reconstruction of the inputs from the noisy features. Lower bounding the variance of every possible unbiased estimator of the inputs quantifies the confidentiality arising from such added noise. Convenient, computationally tractable bounds are available from classic inequalities of Hammersley and of Chapman and Robbins -- the HCR bounds. Numerical experiments indicate that the HCR bounds are on the precipice of being effectual for small neural nets with the data sets, "MNIST" and "CIFAR-10," which contain 10 classes each for image classification. The HCR bounds appear to be insufficient on their own to guarantee confidentiality of the inputs to inference with standard deep neural nets, "ResNet-18" and "Swin-T," pre-trained on the data set, "ImageNet-1000," which contains 1000 classes. Supplementing the addition of noise to features with other methods for providing confidentiality may be warranted in the case of ImageNet. In all cases, the results reported here limit consideration to amounts of added noise that incur little degradation in the accuracy of classification from the noisy features. Thus, the added noise enhances confidentiality without much reduction in the accuracy on the task of image classification.
Beyond web-scraping: Crowd-sourcing a geographically diverse image dataset
Jan 05, 2023



Current dataset collection methods typically scrape large amounts of data from the web. While this technique is extremely scalable, data collected in this way tends to reinforce stereotypical biases, can contain personally identifiable information, and typically originates from Europe and North America. In this work, we rethink the dataset collection paradigm and introduce GeoDE, a geographically diverse dataset with 61,940 images from 40 classes and 6 world regions, and no personally identifiable information, collected through crowd-sourcing. We analyse GeoDE to understand differences in images collected in this manner compared to web-scraping. Despite the smaller size of this dataset, we demonstrate its use as both an evaluation and training dataset, highlight shortcomings in current models, as well as show improved performances when even small amounts of GeoDE (1000 - 2000 images per region) are added to a training dataset. We release the full dataset and code at https://geodiverse-data-collection.cs.princeton.edu/
Bounding Training Data Reconstruction in Private (Deep) Learning
Jan 28, 2022

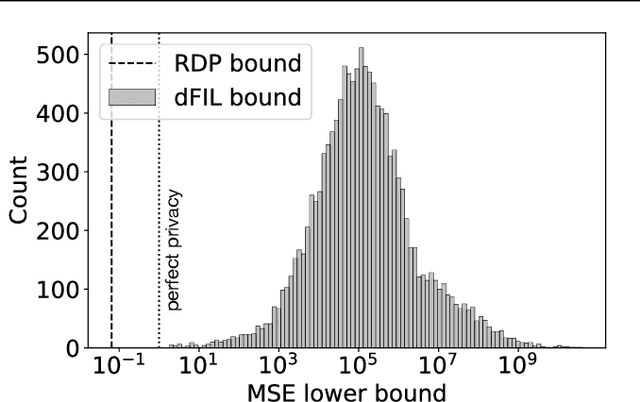

Differential privacy is widely accepted as the de facto method for preventing data leakage in ML, and conventional wisdom suggests that it offers strong protection against privacy attacks. However, existing semantic guarantees for DP focus on membership inference, which may overestimate the adversary's capabilities and is not applicable when membership status itself is non-sensitive. In this paper, we derive the first semantic guarantees for DP mechanisms against training data reconstruction attacks under a formal threat model. We show that two distinct privacy accounting methods -- Renyi differential privacy and Fisher information leakage -- both offer strong semantic protection against data reconstruction attacks.
A Systematic Study of Bias Amplification
Jan 27, 2022



Recent research suggests that predictions made by machine-learning models can amplify biases present in the training data. When a model amplifies bias, it makes certain predictions at a higher rate for some groups than expected based on training-data statistics. Mitigating such bias amplification requires a deep understanding of the mechanics in modern machine learning that give rise to that amplification. We perform the first systematic, controlled study into when and how bias amplification occurs. To enable this study, we design a simple image-classification problem in which we can tightly control (synthetic) biases. Our study of this problem reveals that the strength of bias amplification is correlated to measures such as model accuracy, model capacity, model overconfidence, and amount of training data. We also find that bias amplification can vary greatly during training. Finally, we find that bias amplification may depend on the difficulty of the classification task relative to the difficulty of recognizing group membership: bias amplification appears to occur primarily when it is easier to recognize group membership than class membership. Our results suggest best practices for training machine-learning models that we hope will help pave the way for the development of better mitigation strategies.
Omnivore: A Single Model for Many Visual Modalities
Jan 20, 2022
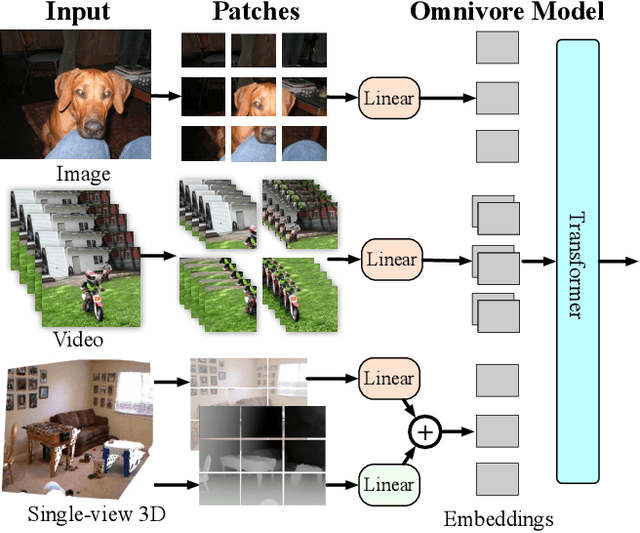
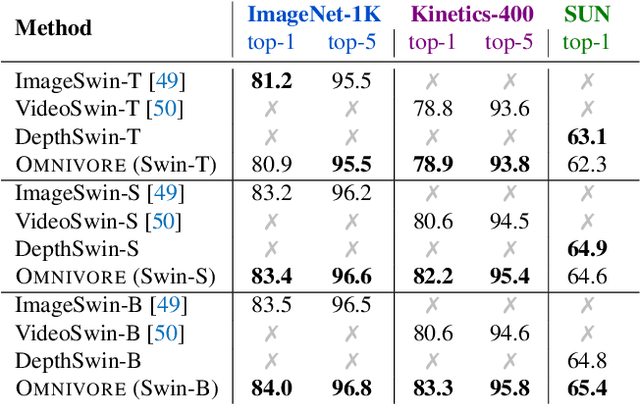
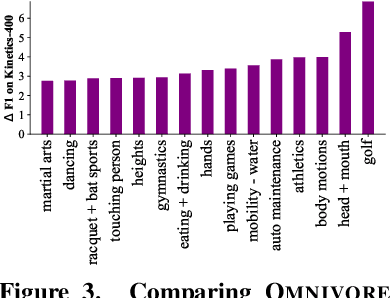
Prior work has studied different visual modalities in isolation and developed separate architectures for recognition of images, videos, and 3D data. Instead, in this paper, we propose a single model which excels at classifying images, videos, and single-view 3D data using exactly the same model parameters. Our 'Omnivore' model leverages the flexibility of transformer-based architectures and is trained jointly on classification tasks from different modalities. Omnivore is simple to train, uses off-the-shelf standard datasets, and performs at-par or better than modality-specific models of the same size. A single Omnivore model obtains 86.0% on ImageNet, 84.1% on Kinetics, and 67.1% on SUN RGB-D. After finetuning, our models outperform prior work on a variety of vision tasks and generalize across modalities. Omnivore's shared visual representation naturally enables cross-modal recognition without access to correspondences between modalities. We hope our results motivate researchers to model visual modalities together.