 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoFL: Robust Fingerprinting of Language Models
May 19, 2025AI developers are releasing large language models (LLMs) under a variety of different licenses. Many of these licenses restrict the ways in which the models or their outputs may be used. This raises the question how license violations may be recognized. In particular, how can we identify that an API or product uses (an adapted version of) a particular LLM? We present a new method that enable model developers to perform such identification via fingerprints: statistical patterns that are unique to the developer's model and robust to common alterations of that model. Our method permits model identification in a black-box setting using a limited number of queries, enabling identification of models that can only be accessed via an API or product. The fingerprints are non-invasive: our method does not require any changes to the model during training, hence by design, it does not impact model quality. Empirically, we find our method provides a high degree of robustness to common changes in the model or inference settings. In our experiments, it substantially outperforms prior art, including invasive methods that explicitly train watermarks into the model.
LAVID: An Agentic LVLM Framework for Diffusion-Generated Video Detection
Feb 20, 2025The impressive achievements of generative models in creating high-quality videos have raised concerns about digital integrity and privacy vulnerabilities. Recent works of AI-generated content detection have been widely studied in the image field (e.g., deepfake), yet the video field has been unexplored. Large Vision Language Model (LVLM) has become an emerging tool for AI-generated content detection for its strong reasoning and multimodal capabilities. It breaks the limitations of traditional deep learning based methods faced with like lack of transparency and inability to recognize new artifacts. Motivated by this, we propose LAVID, a novel LVLMs-based ai-generated video detection with explicit knowledge enhancement. Our insight list as follows: (1) The leading LVLMs can call external tools to extract useful information to facilitate its own video detection task; (2) Structuring the prompt can affect LVLM's reasoning ability to interpret information in video content. Our proposed pipeline automatically selects a set of explicit knowledge tools for detection, and then adaptively adjusts the structure prompt by self-rewriting. Different from prior SOTA that trains additional detectors, our method is fully training-free and only requires inference of the LVLM for detection. To facilitate our research, we also create a new benchmark \vidfor with high-quality videos generated from multiple sources of video generation tools. Evaluation results show that LAVID improves F1 scores by 6.2 to 30.2% over the top baselines on our datasets across four SOTA LVLMs.
Turns Out I'm Not Real: Towards Robust Detection of AI-Generated Videos
Jun 13, 2024The impressive achievements of generative models in creating high-quality videos have raised concerns about digital integrity and privacy vulnerabilities. Recent works to combat Deepfakes videos have developed detectors that are highly accurate at identifying GAN-generated samples. However, the robustness of these detectors on diffusion-generated videos generated from video creation tools (e.g., SORA by OpenAI, Runway Gen-2, and Pika, etc.) is still unexplored. In this paper, we propose a novel framework for detecting videos synthesized from multiple state-of-the-art (SOTA) generative models, such as Stable Video Diffusion. We find that the SOTA methods for detecting diffusion-generated images lack robustness in identifying diffusion-generated videos. Our analysis reveals that the effectiveness of these detectors diminishes when applied to out-of-domain videos, primarily because they struggle to track the temporal features and dynamic variations between frames. To address the above-mentioned challenge, we collect a new benchmark video dataset for diffusion-generated videos using SOTA video creation tools. We extract representation within explicit knowledge from the diffusion model for video frames and train our detector with a CNN + LSTM architecture. The evaluation shows that our framework can well capture the temporal features between frames, achieves 93.7% detection accuracy for in-domain videos, and improves the accuracy of out-domain videos by up to 16 points.
GDA: Generalized Diffusion for Robust Test-time Adaptation
Apr 02, 2024



Machine learning models struggle with generalization when encountering out-of-distribution (OOD) samples with unexpected distribution shifts. For vision tasks, recent studies have shown that test-time adaptation employing diffusion models can achieve state-of-the-art accuracy improvements on OOD samples by generating new samples that align with the model's domain without the need to modify the model's weights. Unfortunately, those studies have primarily focused on pixel-level corruptions, thereby lacking the generalization to adapt to a broader range of OOD types. We introduce Generalized Diffusion Adaptation (GDA), a novel diffusion-based test-time adaptation method robust against diverse OOD types. Specifically, GDA iteratively guides the diffusion by applying a marginal entropy loss derived from the model, in conjunction with style and content preservation losses during the reverse sampling process. In other words, GDA considers the model's output behavior with the semantic information of the samples as a whole, which can reduce ambiguity in downstream tasks during the generation process. Evaluation across various popular model architectures and OOD benchmarks shows that GDA consistently outperforms prior work on diffusion-driven adaptation. Notably, it achieves the highest classification accuracy improvements, ranging from 4.4\% to 5.02\% on ImageNet-C and 2.5\% to 7.4\% on Rendition, Sketch, and Stylized benchmarks. This performance highlights GDA's generalization to a broader range of OOD benchmarks.
Test-time Detection and Repair of Adversarial Samples via Masked Autoencoder
Apr 02, 2023Training-time defenses, known as adversarial training, incur high training costs and do not generalize to unseen attacks. Test-time defenses solve these issues but most existing test-time defenses require adapting the model weights, therefore they do not work on frozen models and complicate model memory management. The only test-time defense that does not adapt model weights aims to adapt the input with self-supervision tasks. However, we empirically found these self-supervision tasks are not sensitive enough to detect adversarial attacks accurately. In this paper, we propose DRAM, a novel defense method to detect and repair adversarial samples at test time via Masked autoencoder (MAE). We demonstrate how to use MAE losses to build a Kolmogorov-Smirnov test to detect adversarial samples. Moreover, we use the MAE losses to calculate input reversal vectors that repair adversarial samples resulting from previously unseen attacks. Results on large-scale ImageNet dataset show that, compared to all detection baselines evaluated, DRAM achieves the best detection rate (82% on average) on all eight adversarial attacks evaluated. For attack repair, DRAM improves the robust accuracy by 6% ~ 41% for standard ResNet50 and 3% ~ 8% for robust ResNet50 compared with the baselines that use contrastive learning and rotation prediction.
Self-Supervised Convolutional Visual Prompts
Mar 01, 2023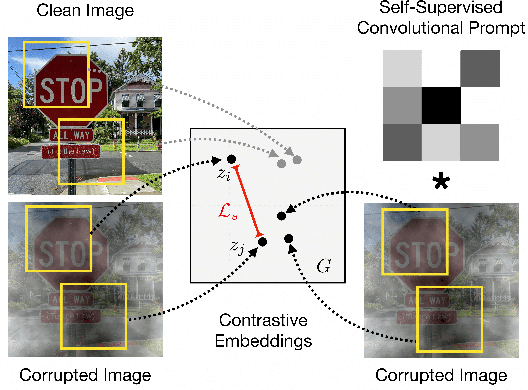
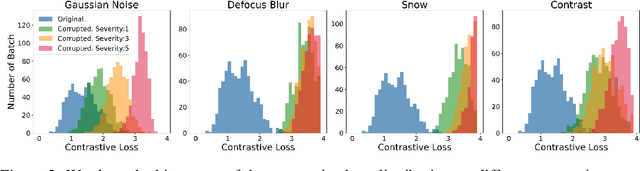
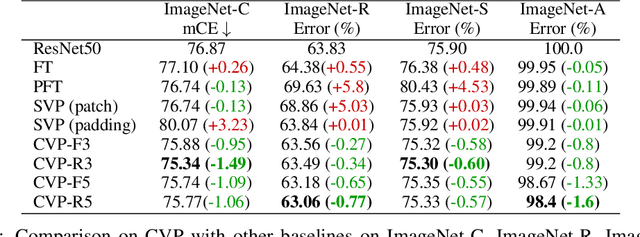
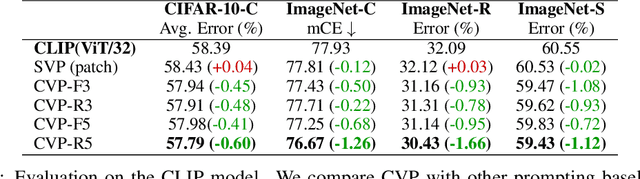
Machine learning models often fail on out-of-distribution (OOD) samples. Visual prompts emerge as a light-weight adaptation method in input space for large-scale vision models. Existing vision prompts optimize a high-dimensional additive vector and require labeled data on training. However, we find this paradigm fails on test-time adaptation when labeled data is unavailable, where the high-dimensional visual prompt overfits to the self-supervised objective. We present convolutional visual prompts for test-time adaptation without labels. Our convolutional prompt is structured and requires fewer trainable parameters (less than 1 % parameters of standard visual prompts). Extensive experiments on a wide variety of OOD recognition tasks show that our approach is effective, improving robustness by up to 5.87 % over a number of large-scale model architectures.
CARBEN: Composite Adversarial Robustness Benchmark
Jul 16, 2022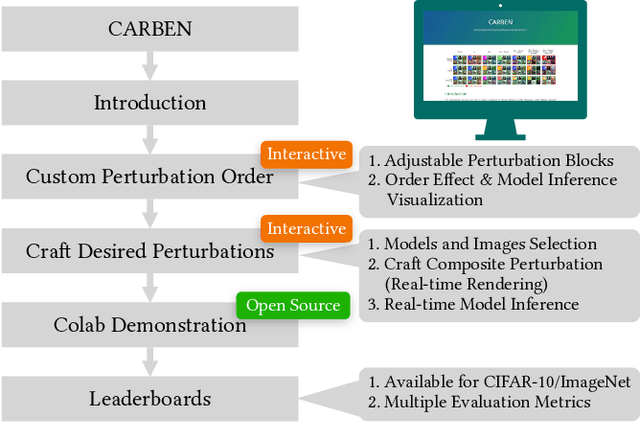



Prior literature on adversarial attack methods has mainly focused on attacking with and defending against a single threat model, e.g., perturbations bounded in Lp ball. However, multiple threat models can be combined into composite perturbations. One such approach, composite adversarial attack (CAA), not only expands the perturbable space of the image, but also may be overlooked by current modes of robustness evaluation. This paper demonstrates how CAA's attack order affects the resulting image, and provides real-time inferences of different models, which will facilitate users' configuration of the parameters of the attack level and their rapid evaluation of model prediction. A leaderboard to benchmark adversarial robustness against CAA is also introduced.
Towards Compositional Adversarial Robustness: Generalizing Adversarial Training to Composite Semantic Perturbations
Feb 09, 2022Model robustness against adversarial examples of single perturbation type such as the $\ell_{p}$-norm has been widely studied, yet its generalization to more realistic scenarios involving multiple semantic perturbations and their composition remains largely unexplored. In this paper, we firstly propose a novel method for generating composite adversarial examples. By utilizing component-wise projected gradient descent and automatic attack-order scheduling, our method can find the optimal attack composition. We then propose \textbf{generalized adversarial training} (\textbf{GAT}) to extend model robustness from $\ell_{p}$-norm to composite semantic perturbations, such as the combination of Hue, Saturation, Brightness, Contrast, and Rotation. The results on ImageNet and CIFAR-10 datasets show that GAT can be robust not only to any single attack but also to any combination of multiple attacks. GAT also outperforms baseline $\ell_{\infty}$-norm bounded adversarial training approaches by a significant margin.
Voice2Series: Reprogramming Acoustic Models for Time Series Classification
Jun 17, 2021



Learning to classify time series with limited data is a practical yet challenging problem. Current methods are primarily based on hand-designed feature extraction rules or domain-specific data augmentation. Motivated by the advances in deep speech processing models and the fact that voice data are univariate temporal signals, in this paper, we propose Voice2Series (V2S), a novel end-to-end approach that reprograms acoustic models for time series classification, through input transformation learning and output label mapping. Leveraging the representation learning power of a large-scale pre-trained speech processing model, on 30 different time series tasks we show that V2S either outperforms or is tied with state-of-the-art methods on 20 tasks, and improves their average accuracy by 1.84%. We further provide a theoretical justification of V2S by proving its population risk is upper bounded by the source risk and a Wasserstein distance accounting for feature alignment via reprogramming. Our results offer new and effective means to time series classification.
Transfer Learning without Knowing: Reprogramming Black-box Machine Learning Models with Scarce Data and Limited Resources
Jul 29, 2020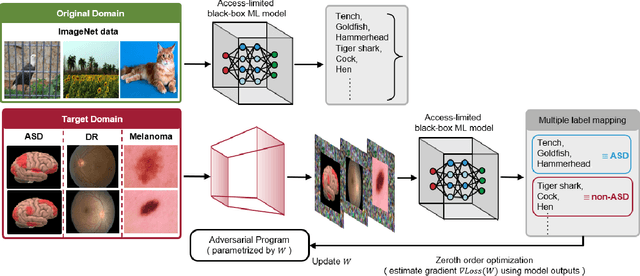



Current transfer learning methods are mainly based on finetuning a pretrained model with target-domain data. Motivated by the techniques from adversarial machine learning (ML) that are capable of manipulating the model prediction via data perturbations, in this paper we propose a novel approach, black-box adversarial reprogramming (BAR), that repurposes a well-trained black-box ML model (e.g., a prediction API or a proprietary software) for solving different ML tasks, especially in the scenario with scarce data and constrained resources. The rationale lies in exploiting high-performance but unknown ML models to gain learning capability for transfer learning. Using zeroth order optimization and multi-label mapping techniques, BAR can reprogram a black-box ML model solely based on its input-output responses without knowing the model architecture or changing any parameter. More importantly, in the limited medical data setting, on autism spectrum disorder classification, diabetic retinopathy detection, and melanoma detection tasks, BAR outperforms state-of-the-art methods and yields comparable performance to the vanilla adversarial reprogramming method requiring complete knowledge of the target ML model. BAR also outperforms baseline transfer learning approaches by a significant margin, demonstrating cost-effective means and new insights for transfer learning.