 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Model Stitching In the Foundation Model Era
Mar 16, 2026Model stitching, connecting early layers of one model (source) to later layers of another (target) via a light stitch layer, has served as a probe of representational compatibility. Prior work finds that models trained on the same dataset remain stitchable (negligible accuracy drop) despite different initializations or objectives. We revisit stitching for Vision Foundation Models (VFMs) that vary in objectives, data, and modality mix (e.g., CLIP, DINOv2, SigLIP 2) and ask: Are heterogeneous VFMs stitchable? We introduce a systematic protocol spanning the stitch points, stitch layer families, training losses, and downstream tasks. Three findings emerge. (1) Stitch layer training matters: conventional approaches that match the intermediate features at the stitch point or optimize the task loss end-to-end struggle to retain accuracy, especially at shallow stitch points. (2) With a simple feature-matching loss at the target model's penultimate layer, heterogeneous VFMs become reliably stitchable across vision tasks. (3) For deep stitch points, the stitched model can surpass either constituent model at only a small inference overhead (for the stitch layer). Building on these findings, we further propose the VFM Stitch Tree (VST), which shares early layers across VFMs while retaining their later layers, yielding a controllable accuracy-latency trade-off for multimodal LLMs that often leverage multiple VFMs. Taken together, our study elevates stitching from a diagnostic probe to a practical recipe for integrating complementary VFM strengths and pinpointing where their representations align or diverge.
SceneFoundry: Generating Interactive Infinite 3D Worlds
Jan 09, 2026The ability to automatically generate large-scale, interactive, and physically realistic 3D environments is crucial for advancing robotic learning and embodied intelligence. However, existing generative approaches often fail to capture the functional complexity of real-world interiors, particularly those containing articulated objects with movable parts essential for manipulation and navigation. This paper presents SceneFoundry, a language-guided diffusion framework that generates apartment-scale 3D worlds with functionally articulated furniture and semantically diverse layouts for robotic training. From natural language prompts, an LLM module controls floor layout generation, while diffusion-based posterior sampling efficiently populates the scene with articulated assets from large-scale 3D repositories. To ensure physical usability, SceneFoundry employs differentiable guidance functions to regulate object quantity, prevent articulation collisions, and maintain sufficient walkable space for robotic navigation. Extensive experiments demonstrate that our framework generates structurally valid, semantically coherent, and functionally interactive environments across diverse scene types and conditions, enabling scalable embodied AI research.
AI as a Teaching Partner: Early Lessons from Classroom Codesign with Secondary Teachers
Dec 12, 2025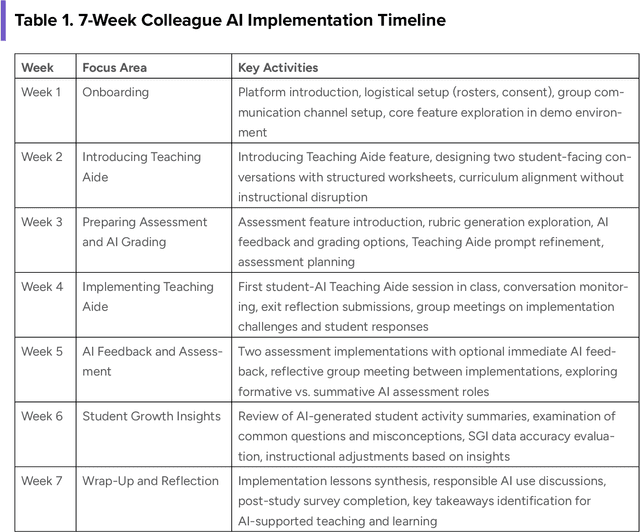

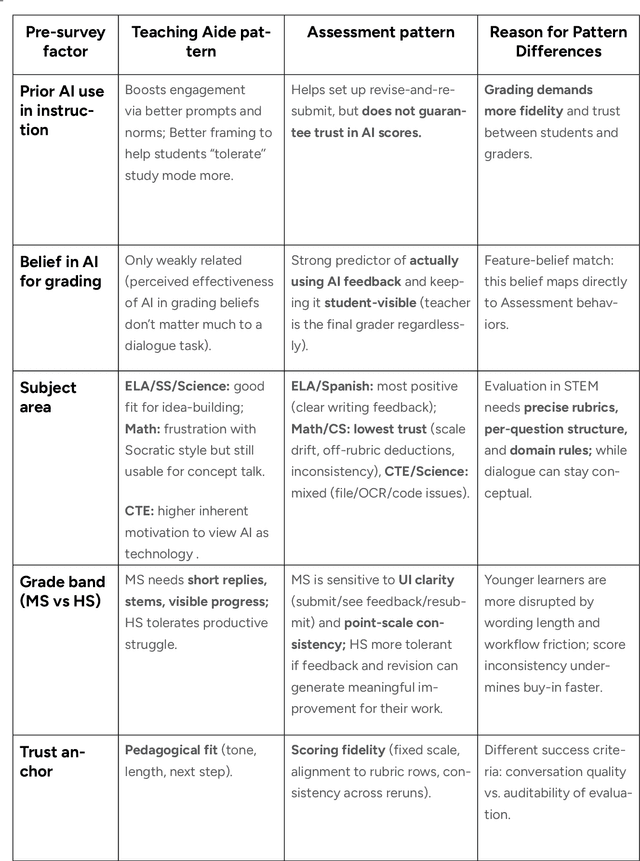
This report presents a comprehensive account of the Colleague AI Classroom pilot, a collaborative design (co-design) study that brought generative AI technology directly into real classrooms. In this study, AI functioned as a third agent, an active participant that mediated feedback, supported inquiry, and extended teachers' instructional reach while preserving human judgment and teacher authority. Over seven weeks in spring 2025, 21 in-service teachers from four Washington State public school districts and one independent school integrated four AI-powered features of the Colleague AI Classroom into their instruction: Teaching Aide, Assessment and AI Grading, AI Tutor, and Student Growth Insights. More than 600 students in grades 6-12 used the platform in class at the direction of their teachers, who designed and facilitated the AI activities. During the Classroom pilot, teachers were co-design partners: they planned activities, implemented them with students, and provided weekly reflections on AI's role in classroom settings. The teachers' feedback guided iterative improvements for Colleague AI. The research team captured rich data through surveys, planning and reflection forms, group meetings, one-on-one interviews, and platform usage logs to understand where AI adds instructional value and where it requires refinement.
DC-Mamba: Bi-temporal deformable alignment and scale-sparse enhancement for remote sensing change detection
Sep 19, 2025Remote sensing change detection (RSCD) is vital for identifying land-cover changes, yet existing methods, including state-of-the-art State Space Models (SSMs), often lack explicit mechanisms to handle geometric misalignments and struggle to distinguish subtle, true changes from noise.To address this, we introduce DC-Mamba, an "align-then-enhance" framework built upon the ChangeMamba backbone. It integrates two lightweight, plug-and-play modules: (1) Bi-Temporal Deformable Alignment (BTDA), which explicitly introduces geometric awareness to correct spatial misalignments at the semantic feature level; and (2) a Scale-Sparse Change Amplifier(SSCA), which uses multi-source cues to selectively amplify high-confidence change signals while suppressing noise before the final classification. This synergistic design first establishes geometric consistency with BTDA to reduce pseudo-changes, then leverages SSCA to sharpen boundaries and enhance the visibility of small or subtle targets. Experiments show our method significantly improves performance over the strong ChangeMamba baseline, increasing the F1-score from 0.5730 to 0.5903 and IoU from 0.4015 to 0.4187. The results confirm the effectiveness of our "align-then-enhance" strategy, offering a robust and easily deployable solution that transparently addresses both geometric and feature-level challenges in RSCD.
Attribute-based Object Grounding and Robot Grasp Detection with Spatial Reasoning
Sep 09, 2025Enabling robots to grasp objects specified through natural language is essential for effective human-robot interaction, yet it remains a significant challenge. Existing approaches often struggle with open-form language expressions and typically assume unambiguous target objects without duplicates. Moreover, they frequently rely on costly, dense pixel-wise annotations for both object grounding and grasp configuration. We present Attribute-based Object Grounding and Robotic Grasping (OGRG), a novel framework that interprets open-form language expressions and performs spatial reasoning to ground target objects and predict planar grasp poses, even in scenes containing duplicated object instances. We investigate OGRG in two settings: (1) Referring Grasp Synthesis (RGS) under pixel-wise full supervision, and (2) Referring Grasp Affordance (RGA) using weakly supervised learning with only single-pixel grasp annotations. Key contributions include a bi-directional vision-language fusion module and the integration of depth information to enhance geometric reasoning, improving both grounding and grasping performance. Experiment results show that OGRG outperforms strong baselines in tabletop scenes with diverse spatial language instructions. In RGS, it operates at 17.59 FPS on a single NVIDIA RTX 2080 Ti GPU, enabling potential use in closed-loop or multi-object sequential grasping, while delivering superior grounding and grasp prediction accuracy compared to all the baselines considered. Under the weakly supervised RGA setting, OGRG also surpasses baseline grasp-success rates in both simulation and real-robot trials, underscoring the effectiveness of its spatial reasoning design. Project page: https://z.umn.edu/ogrg
OpenM3D: Open Vocabulary Multi-view Indoor 3D Object Detection without Human Annotations
Aug 27, 2025Open-vocabulary (OV) 3D object detection is an emerging field, yet its exploration through image-based methods remains limited compared to 3D point cloud-based methods. We introduce OpenM3D, a novel open-vocabulary multi-view indoor 3D object detector trained without human annotations. In particular, OpenM3D is a single-stage detector adapting the 2D-induced voxel features from the ImGeoNet model. To support OV, it is jointly trained with a class-agnostic 3D localization loss requiring high-quality 3D pseudo boxes and a voxel-semantic alignment loss requiring diverse pre-trained CLIP features. We follow the training setting of OV-3DET where posed RGB-D images are given but no human annotations of 3D boxes or classes are available. We propose a 3D Pseudo Box Generation method using a graph embedding technique that combines 2D segments into coherent 3D structures. Our pseudo-boxes achieve higher precision and recall than other methods, including the method proposed in OV-3DET. We further sample diverse CLIP features from 2D segments associated with each coherent 3D structure to align with the corresponding voxel feature. The key to training a highly accurate single-stage detector requires both losses to be learned toward high-quality targets. At inference, OpenM3D, a highly efficient detector, requires only multi-view images for input and demonstrates superior accuracy and speed (0.3 sec. per scene) on ScanNet200 and ARKitScenes indoor benchmarks compared to existing methods. We outperform a strong two-stage method that leverages our class-agnostic detector with a ViT CLIP-based OV classifier and a baseline incorporating multi-view depth estimator on both accuracy and speed.
Decoding Instructional Dialogue: Human-AI Collaborative Analysis of Teacher Use of AI Tool at Scale
Jul 23, 2025The integration of large language models (LLMs) into educational tools has the potential to substantially impact how teachers plan instruction, support diverse learners, and engage in professional reflection. Yet little is known about how educators actually use these tools in practice and how their interactions with AI can be meaningfully studied at scale. This paper presents a human-AI collaborative methodology for large-scale qualitative analysis of over 140,000 educator-AI messages drawn from a generative AI platform used by K-12 teachers. Through a four-phase coding pipeline, we combined inductive theme discovery, codebook development, structured annotation, and model benchmarking to examine patterns of educator engagement and evaluate the performance of LLMs in qualitative coding tasks. We developed a hierarchical codebook aligned with established teacher evaluation frameworks, capturing educators' instructional goals, contextual needs, and pedagogical strategies. Our findings demonstrate that LLMs, particularly Claude 3.5 Haiku, can reliably support theme identification, extend human recognition in complex scenarios, and outperform open-weight models in both accuracy and structural reliability. The analysis also reveals substantive patterns in how educators inquire AI to enhance instructional practices (79.7 percent of total conversations), create or adapt content (76.1 percent), support assessment and feedback loop (46.9 percent), attend to student needs for tailored instruction (43.3 percent), and assist other professional responsibilities (34.2 percent), highlighting emerging AI-related competencies that have direct implications for teacher preparation and professional development. This study offers a scalable, transparent model for AI-augmented qualitative research and provides foundational insights into the evolving role of generative AI in educational practice.
UA-Pose: Uncertainty-Aware 6D Object Pose Estimation and Online Object Completion with Partial References
Jun 09, 2025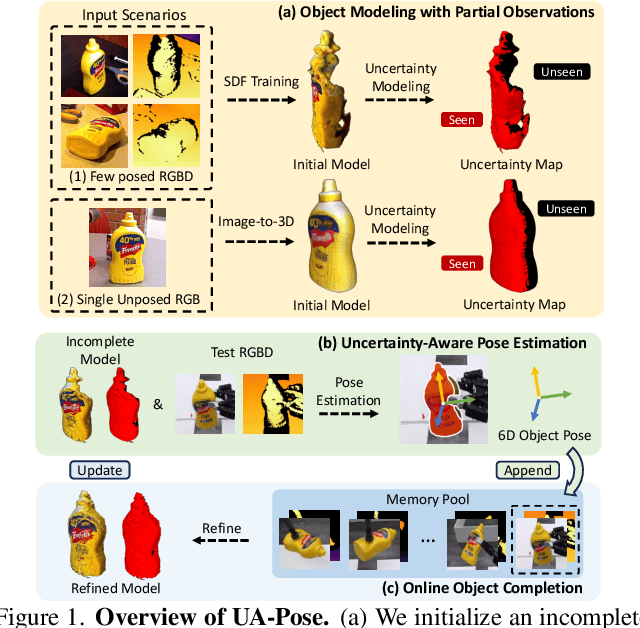

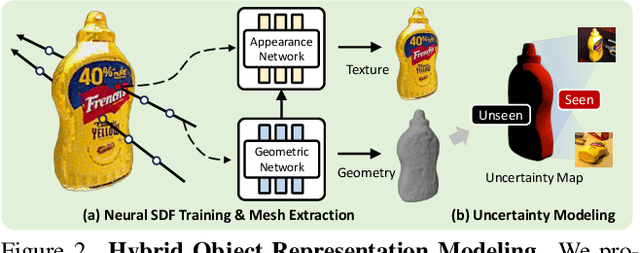

6D object pose estimation has shown strong generalizability to novel objects. However, existing methods often require either a complete, well-reconstructed 3D model or numerous reference images that fully cover the object. Estimating 6D poses from partial references, which capture only fragments of an object's appearance and geometry, remains challenging. To address this, we propose UA-Pose, an uncertainty-aware approach for 6D object pose estimation and online object completion specifically designed for partial references. We assume access to either (1) a limited set of RGBD images with known poses or (2) a single 2D image. For the first case, we initialize a partial object 3D model based on the provided images and poses, while for the second, we use image-to-3D techniques to generate an initial object 3D model. Our method integrates uncertainty into the incomplete 3D model, distinguishing between seen and unseen regions. This uncertainty enables confidence assessment in pose estimation and guides an uncertainty-aware sampling strategy for online object completion, enhancing robustness in pose estimation accuracy and improving object completeness. We evaluate our method on the YCB-Video, YCBInEOAT, and HO3D datasets, including RGBD sequences of YCB objects manipulated by robots and human hands. Experimental results demonstrate significant performance improvements over existing methods, particularly when object observations are incomplete or partially captured. Project page: https://minfenli.github.io/UA-Pose/
Solving the Best Subset Selection Problem via Suboptimal Algorithms
Mar 31, 2025



Best subset selection in linear regression is well known to be nonconvex and computationally challenging to solve, as the number of possible subsets grows rapidly with increasing dimensionality of the problem. As a result, finding the global optimal solution via an exact optimization method for a problem with dimensions of 1000s may take an impractical amount of CPU time. This suggests the importance of finding suboptimal procedures that can provide good approximate solutions using much less computational effort than exact methods. In this work, we introduce a new procedure and compare it with other popular suboptimal algorithms to solve the best subset selection problem. Extensive computational experiments using synthetic and real data have been performed. The results provide insights into the performance of these methods in different data settings. The new procedure is observed to be a competitive suboptimal algorithm for solving the best subset selection problem for high-dimensional data.
uLayout: Unified Room Layout Estimation for Perspective and Panoramic Images
Mar 27, 2025We present uLayout, a unified model for estimating room layout geometries from both perspective and panoramic images, whereas traditional solutions require different model designs for each image type. The key idea of our solution is to unify both domains into the equirectangular projection, particularly, allocating perspective images into the most suitable latitude coordinate to effectively exploit both domains seamlessly. To address the Field-of-View (FoV) difference between the input domains, we design uLayout with a shared feature extractor with an extra 1D-Convolution layer to condition each domain input differently. This conditioning allows us to efficiently formulate a column-wise feature regression problem regardless of the FoV input. This simple yet effective approach achieves competitive performance with current state-of-the-art solutions and shows for the first time a single end-to-end model for both domains. Extensive experiments in the real-world datasets, LSUN, Matterport3D, PanoContext, and Stanford 2D-3D evidence the contribution of our approach. Code is available at https://github.com/JonathanLee112/uLayout.