 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenM3D: Open Vocabulary Multi-view Indoor 3D Object Detection without Human Annotations
Aug 27, 2025Open-vocabulary (OV) 3D object detection is an emerging field, yet its exploration through image-based methods remains limited compared to 3D point cloud-based methods. We introduce OpenM3D, a novel open-vocabulary multi-view indoor 3D object detector trained without human annotations. In particular, OpenM3D is a single-stage detector adapting the 2D-induced voxel features from the ImGeoNet model. To support OV, it is jointly trained with a class-agnostic 3D localization loss requiring high-quality 3D pseudo boxes and a voxel-semantic alignment loss requiring diverse pre-trained CLIP features. We follow the training setting of OV-3DET where posed RGB-D images are given but no human annotations of 3D boxes or classes are available. We propose a 3D Pseudo Box Generation method using a graph embedding technique that combines 2D segments into coherent 3D structures. Our pseudo-boxes achieve higher precision and recall than other methods, including the method proposed in OV-3DET. We further sample diverse CLIP features from 2D segments associated with each coherent 3D structure to align with the corresponding voxel feature. The key to training a highly accurate single-stage detector requires both losses to be learned toward high-quality targets. At inference, OpenM3D, a highly efficient detector, requires only multi-view images for input and demonstrates superior accuracy and speed (0.3 sec. per scene) on ScanNet200 and ARKitScenes indoor benchmarks compared to existing methods. We outperform a strong two-stage method that leverages our class-agnostic detector with a ViT CLIP-based OV classifier and a baseline incorporating multi-view depth estimator on both accuracy and speed.
UA-Pose: Uncertainty-Aware 6D Object Pose Estimation and Online Object Completion with Partial References
Jun 09, 2025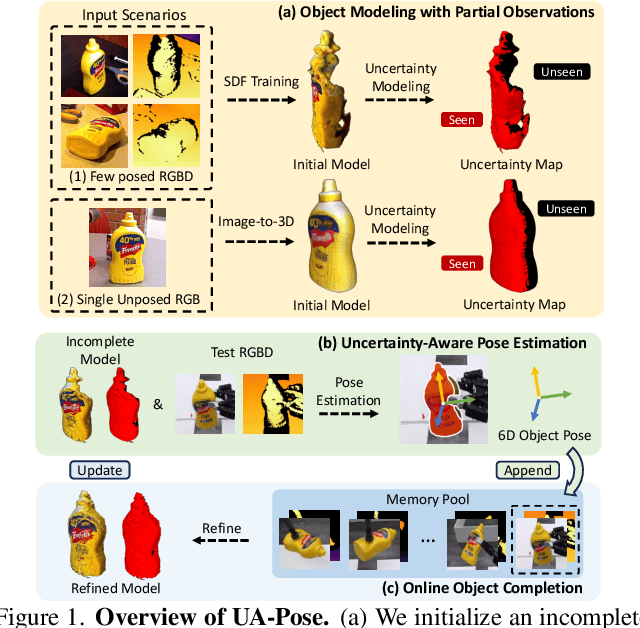

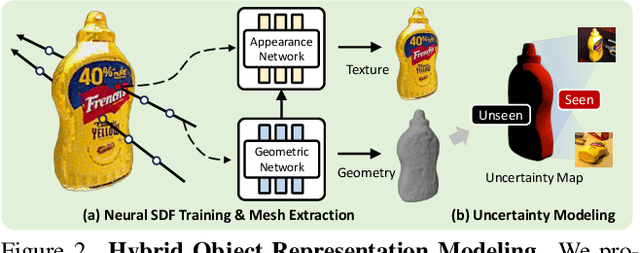

6D object pose estimation has shown strong generalizability to novel objects. However, existing methods often require either a complete, well-reconstructed 3D model or numerous reference images that fully cover the object. Estimating 6D poses from partial references, which capture only fragments of an object's appearance and geometry, remains challenging. To address this, we propose UA-Pose, an uncertainty-aware approach for 6D object pose estimation and online object completion specifically designed for partial references. We assume access to either (1) a limited set of RGBD images with known poses or (2) a single 2D image. For the first case, we initialize a partial object 3D model based on the provided images and poses, while for the second, we use image-to-3D techniques to generate an initial object 3D model. Our method integrates uncertainty into the incomplete 3D model, distinguishing between seen and unseen regions. This uncertainty enables confidence assessment in pose estimation and guides an uncertainty-aware sampling strategy for online object completion, enhancing robustness in pose estimation accuracy and improving object completeness. We evaluate our method on the YCB-Video, YCBInEOAT, and HO3D datasets, including RGBD sequences of YCB objects manipulated by robots and human hands. Experimental results demonstrate significant performance improvements over existing methods, particularly when object observations are incomplete or partially captured. Project page: https://minfenli.github.io/UA-Pose/
Enhancing Single Image to 3D Generation using Gaussian Splatting and Hybrid Diffusion Priors
Oct 12, 2024
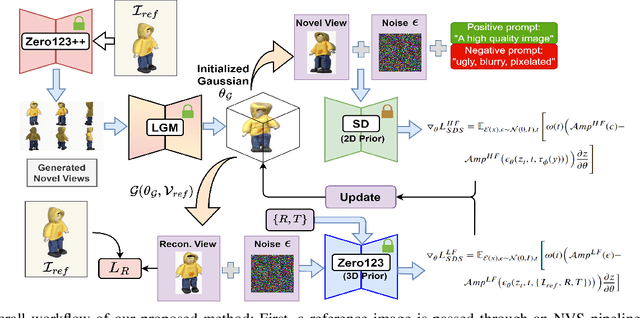
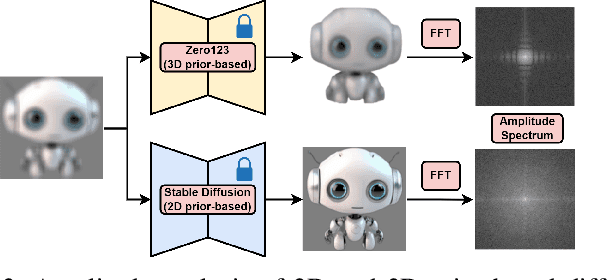
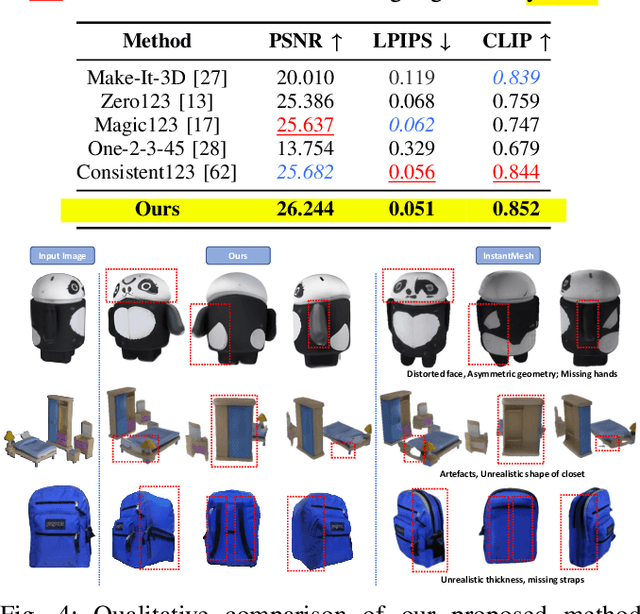
3D object generation from a single image involves estimating the full 3D geometry and texture of unseen views from an unposed RGB image captured in the wild. Accurately reconstructing an object's complete 3D structure and texture has numerous applications in real-world scenarios, including robotic manipulation, grasping, 3D scene understanding, and AR/VR. Recent advancements in 3D object generation have introduced techniques that reconstruct an object's 3D shape and texture by optimizing the efficient representation of Gaussian Splatting, guided by pre-trained 2D or 3D diffusion models. However, a notable disparity exists between the training datasets of these models, leading to distinct differences in their outputs. While 2D models generate highly detailed visuals, they lack cross-view consistency in geometry and texture. In contrast, 3D models ensure consistency across different views but often result in overly smooth textures. We propose bridging the gap between 2D and 3D diffusion models to address this limitation by integrating a two-stage frequency-based distillation loss with Gaussian Splatting. Specifically, we leverage geometric priors in the low-frequency spectrum from a 3D diffusion model to maintain consistent geometry and use a 2D diffusion model to refine the fidelity and texture in the high-frequency spectrum of the generated 3D structure, resulting in more detailed and fine-grained outcomes. Our approach enhances geometric consistency and visual quality, outperforming the current SOTA. Additionally, we demonstrate the easy adaptability of our method for efficient object pose estimation and tracking.
GenRC: Generative 3D Room Completion from Sparse Image Collections
Jul 19, 2024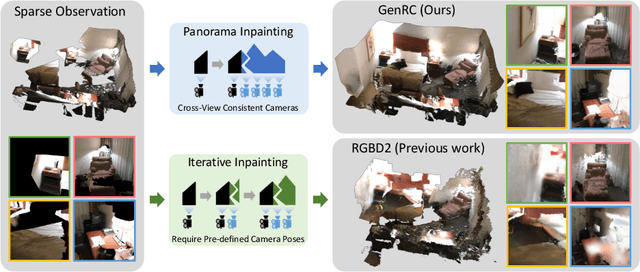



Sparse RGBD scene completion is a challenging task especially when considering consistent textures and geometries throughout the entire scene. Different from existing solutions that rely on human-designed text prompts or predefined camera trajectories, we propose GenRC, an automated training-free pipeline to complete a room-scale 3D mesh with high-fidelity textures. To achieve this, we first project the sparse RGBD images to a highly incomplete 3D mesh. Instead of iteratively generating novel views to fill in the void, we utilized our proposed E-Diffusion to generate a view-consistent panoramic RGBD image which ensures global geometry and appearance consistency. Furthermore, we maintain the input-output scene stylistic consistency through textual inversion to replace human-designed text prompts. To bridge the domain gap among datasets, E-Diffusion leverages models trained on large-scale datasets to generate diverse appearances. GenRC outperforms state-of-the-art methods under most appearance and geometric metrics on ScanNet and ARKitScenes datasets, even though GenRC is not trained on these datasets nor using predefined camera trajectories. Project page: https://minfenli.github.io/GenRC
DreaMo: Articulated 3D Reconstruction From A Single Casual Video
Dec 07, 2023



Articulated 3D reconstruction has valuable applications in various domains, yet it remains costly and demands intensive work from domain experts. Recent advancements in template-free learning methods show promising results with monocular videos. Nevertheless, these approaches necessitate a comprehensive coverage of all viewpoints of the subject in the input video, thus limiting their applicability to casually captured videos from online sources. In this work, we study articulated 3D shape reconstruction from a single and casually captured internet video, where the subject's view coverage is incomplete. We propose DreaMo that jointly performs shape reconstruction while solving the challenging low-coverage regions with view-conditioned diffusion prior and several tailored regularizations. In addition, we introduce a skeleton generation strategy to create human-interpretable skeletons from the learned neural bones and skinning weights. We conduct our study on a self-collected internet video collection characterized by incomplete view coverage. DreaMo shows promising quality in novel-view rendering, detailed articulated shape reconstruction, and skeleton generation. Extensive qualitative and quantitative studies validate the efficacy of each proposed component, and show existing methods are unable to solve correct geometry due to the incomplete view coverage.
The Study of Highway for Lifelong Multi-Agent Path Finding
Apr 09, 2023In modern fulfillment warehouses, agents traverse the map to complete endless tasks that arrive on the fly, which is formulated as a lifelong Multi-Agent Path Finding (lifelong MAPF) problem. The goal of tackling this challenging problem is to find the path for each agent in a finite runtime while maximizing the throughput. However, existing methods encounter exponential growth of runtime and undesirable phenomena of deadlocks and rerouting as the map size or agent density grows. To address these challenges in lifelong MAPF, we explore the idea of highways mainly studied for one-shot MAPF (i.e., finding paths at once beforehand), which reduces the complexity of the problem by encouraging agents to move in the same direction. We utilize two methods to incorporate the highway idea into the lifelong MAPF framework and discuss the properties that minimize the existing problems of deadlocks and rerouting. The experimental results demonstrate that the runtime is considerably reduced and the decay of throughput is gradually insignificant as the map size enlarges under the settings of the highway. Furthermore, when the density of agents increases, the phenomena of deadlocks and rerouting are significantly reduced by leveraging the highway.