 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenRC: Generative 3D Room Completion from Sparse Image Collections
Jul 19, 2024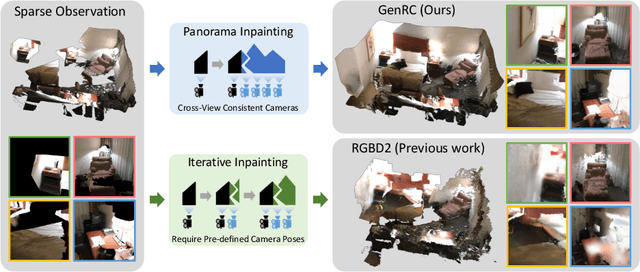



Sparse RGBD scene completion is a challenging task especially when considering consistent textures and geometries throughout the entire scene. Different from existing solutions that rely on human-designed text prompts or predefined camera trajectories, we propose GenRC, an automated training-free pipeline to complete a room-scale 3D mesh with high-fidelity textures. To achieve this, we first project the sparse RGBD images to a highly incomplete 3D mesh. Instead of iteratively generating novel views to fill in the void, we utilized our proposed E-Diffusion to generate a view-consistent panoramic RGBD image which ensures global geometry and appearance consistency. Furthermore, we maintain the input-output scene stylistic consistency through textual inversion to replace human-designed text prompts. To bridge the domain gap among datasets, E-Diffusion leverages models trained on large-scale datasets to generate diverse appearances. GenRC outperforms state-of-the-art methods under most appearance and geometric metrics on ScanNet and ARKitScenes datasets, even though GenRC is not trained on these datasets nor using predefined camera trajectories. Project page: https://minfenli.github.io/GenRC